已解决
论文笔记:ViTGAN: Training GANs with Vision Transformers
来自网友在路上 150850提问 提问时间:2023-09-26 07:16:39阅读次数: 50
最佳答案 问答题库508位专家为你答疑解惑
2021
1 intro
- 论文研究的问题是:ViT是否可以在不使用卷积或池化的情况下完成图像生成任务
- 即不用CNN,而使用ViT来完成图像生成任务
- 将ViT架构集成到GAN中,发现现有的GAN正则化方法与self-attention机制的交互很差,导致训练过程中严重的不稳定
- ——>引入了新的正则化技术来训练带有ViT的GAN
- ViTGAN模型远优于基于Transformer的GAN模型,在不使用卷积或池化的情况下,性能与基于CNN的GAN(如Style-GAN2)相当
- ViTGAN模型是首个在GAN中利用视觉Transformer的模型之一
2 方法
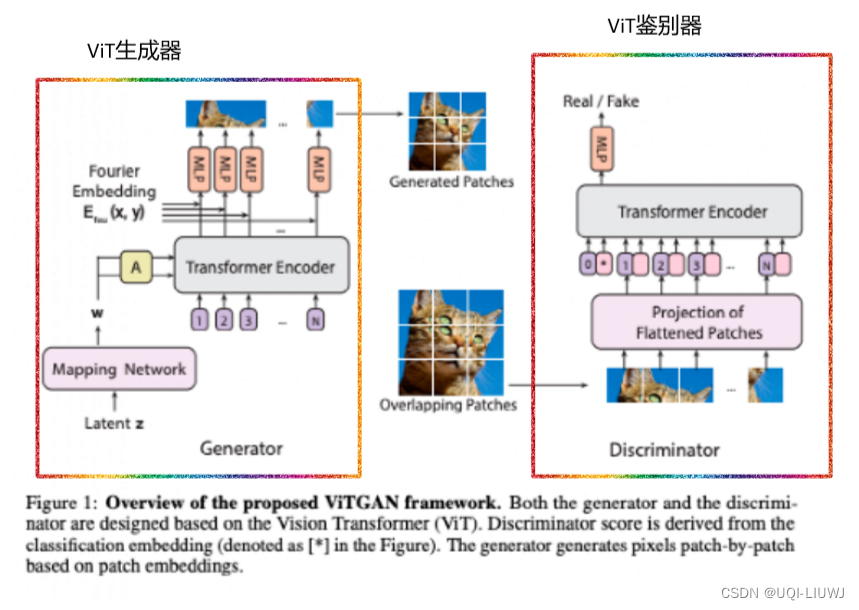
- 直接使用ViT作为鉴别器会使训练变得不稳定。
- 论文对生成器和鉴别器都引入了新的技术,用来稳定训练动态并促进收敛。
- (1)ViT鉴别器的正则化;
- (2)生成器的新架构
- 论文对生成器和鉴别器都引入了新的技术,用来稳定训练动态并促进收敛。
2.1 ViT鉴别器的正则化
- 利普希茨连续(Lipschitz continuity)在GAN鉴别器中很重要
- GAN笔记:利普希茨连续(Lipschitz continuity)_UQI-LIUWJ的博客-CSDN博客
- 然而,最近的一项工作表明,标准dot product self-attention层的Lipschitz常数可以是无界的,使Lipschitz连续在ViTs中被违反。
- —>1,用欧氏距离代替点积相似度
- —>2,在初始化时将每层的归一化权重矩阵与spectral norm相乘
- 对于任意矩阵 A,其Spectral Norm定义为:
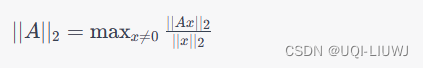
- 也可以定义为矩阵 A 的最大奇异值

- σ计算矩阵的Spectral Norm
- 对于任意矩阵 A,其Spectral Norm定义为:
- —>1,用欧氏距离代替点积相似度
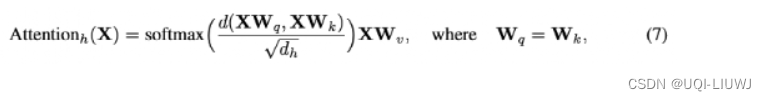
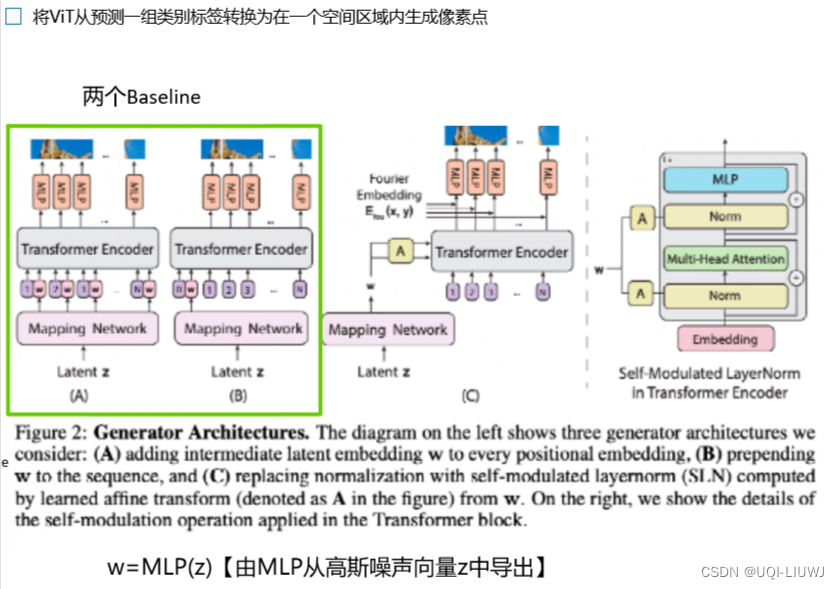
2.2 设计生成器
3 实验
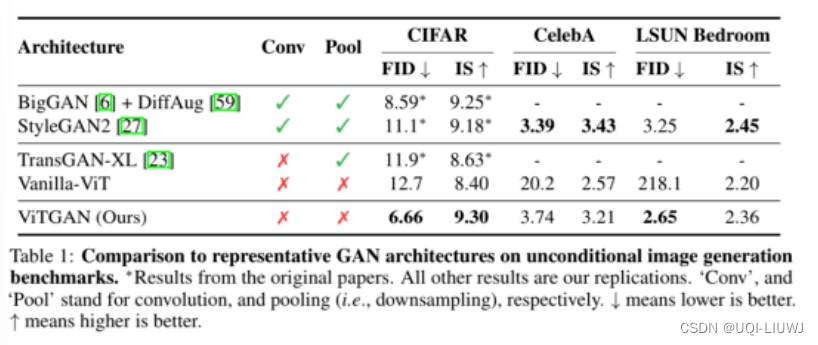

查看全文
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"论文笔记:ViTGAN: Training GANs with Vision Transformers":http://eshow365.cn/6-13770-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: iOS 17隐私设置指南
- 下一篇: 夜莺启动时报dialector() not supported