论文阅读——What Can Human Sketches Do for Object Detection?(cvpr2023)
最佳答案 问答题库768位专家为你答疑解惑
论文:https://openaccess.thecvf.com/content/CVPR2023/papers/Chowdhury_What_Can_Human_Sketches_Do_for_Object_Detection_CVPR_2023_paper.pdf
代码:What Can Human Sketches Do for Object Detection? (pinakinathc.me)
一、
Baseline SBIR Framework:给一组图片:轮廓和图片,学习到对应的两个特征,然后使用余弦距离计算triplet loss。
本文使用hard-triplet loss,再加上一个分类损失
二、
使用RPN或者selective search生成框和对应的特征,输入到分类头检测头得到两个分数。通过这两个来判断图片中是否出现某个类别。分类头分数分别判断每个区域属于某个类别的概率,检测头分数判断这个patch对属于被分到的这个类别的贡献度。
labels:![]()
![]()
![]()
![]()
![]()

![]()
![]() ,
, ![]()
![]()
![]()
三、
下面是微调框:
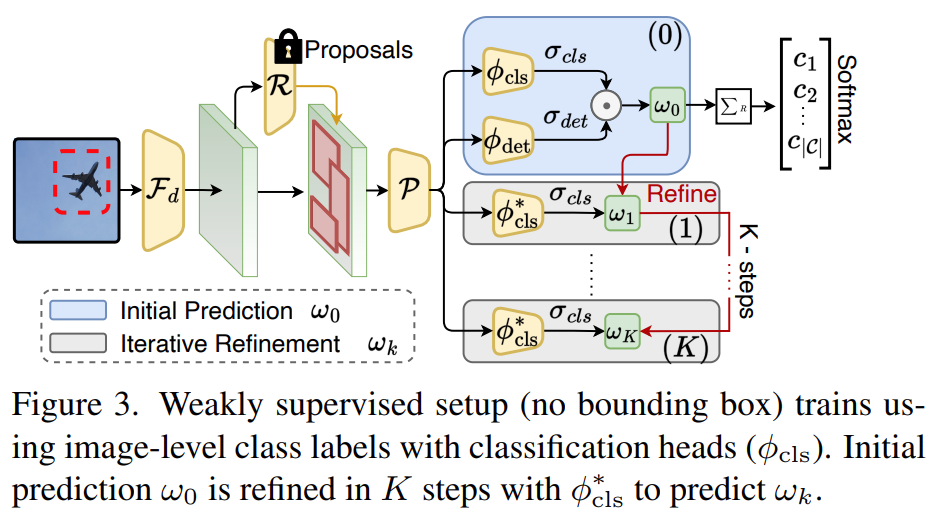
因为没有坐标标注,所以使用了一个迭代微调分类器![]() 对每个ROI预测一个精细的类别分数,标签从第k-1步迭代获得:
对每个ROI预测一个精细的类别分数,标签从第k-1步迭代获得:
1、计算每个类别分数最高的patch
2、和这个patch重叠度高的(iou>0.5)patch都是一个类别
3、如果某个区域和任何一个分数高的patch重合度都不高,就是背景。
4、如果某个类别没出现在图片中,也是0
损失函数:
![]()
![]()

四、
然后检测一般是预先固定多少类别,作者克服了这个限制

每个头![]() 原本预测分数
原本预测分数![]()
![]() ,改为计算嵌入向量
,改为计算嵌入向量![]()
用预训练的Fs编码patch![]() 得到
得到![]()
![]() ,
,
计算分数:![]()
多加了一个来自原始图片的监督Fp,![]()
最终损失为:
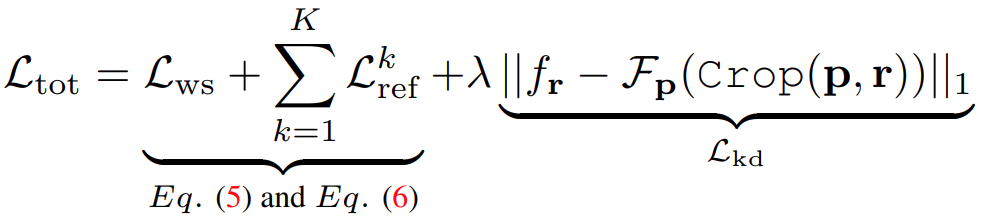
五、
泛化到开放词汇检测:
轮廓向量集合:![]()
图片向量集合:![]()
映射到ViT第一层,以诱导CLIP学习下游轮廓/照片分布
ViT权重冻结,CLIP学习到知识被蒸馏为prompts的权重。
最后新的轮廓和图片encoder为使用sketch prompt和图片prompt的CLIP’s image encoder,![]() ,
,![]()
只训练Vs和Vp
学习跨类别的FGSBIR:

![]()
99%的人还看了
相似问题
- YOLO目标检测——卫星遥感多类别检测数据集下载分享【含对应voc、coco和yolo三种格式标签】
- SELinux零知识学习十三、SELinux策略语言之客体类别和许可(7)
- 第十一篇 基于JSP 技术的网上购书系统——产品类别管理、评论/留言管理、注册用户管理、新闻管理功能实现(网上商城、仿淘宝、当当、亚马逊)
- 常用的数据库类别及介绍
- Python按类别和比例从Labelme数据集中划分出训练数据集和测试数据集
- Python实现从Labelme数据集中挑选出含有指定类别的数据集
- 怎么通过联表合并表格的后查找不同职务职称的人数(python自动化办公,表格合并,同时查询不同类别情况下的个数)
- AI 大框架分析基于python之TensorFlow(归一化处理,多类别分类的概率)
猜你感兴趣
版权申明
本文"论文阅读——What Can Human Sketches Do for Object Detection?(cvpr2023)":http://eshow365.cn/6-34717-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!