15 _ 二分查找(上):如何用最省内存的方式实现快速查找功能?
最佳答案 问答题库778位专家为你答疑解惑
今天我们讲一种针对有序数据集合的查找算法:二分查找(Binary Search)算法,也叫折半查找算法。二分查找的思想非常简单,很多非计算机专业的同学很容易就能理解,但是看似越简单的东西往往越难掌握好,想要灵活应用就更加困难。
老规矩,我们还是来看一道思考题。
假设我们有1000万个整数数据,每个数据占8个字节,如何设计数据结构和算法,快速判断某个整数是否出现在这1000万数据中? 我们希望这个功能不要占用太多的内存空间,最多不要超过100MB,你会怎么做呢?带着这个问题,让我们进入今天的内容吧!
无处不在的二分思想
二分查找是一种非常简单易懂的快速查找算法,生活中到处可见。比如说,我们现在来做一个猜字游戏。我随机写一个0到99之间的数字,然后你来猜我写的是什么。猜的过程中,你每猜一次,我就会告诉你猜的大了还是小了,直到猜中为止。你来想想,如何快速猜中我写的数字呢?
假设我写的数字是23,你可以按照下面的步骤来试一试。(如果猜测范围的数字有偶数个,中间数有两个,就选择较小的那个。)
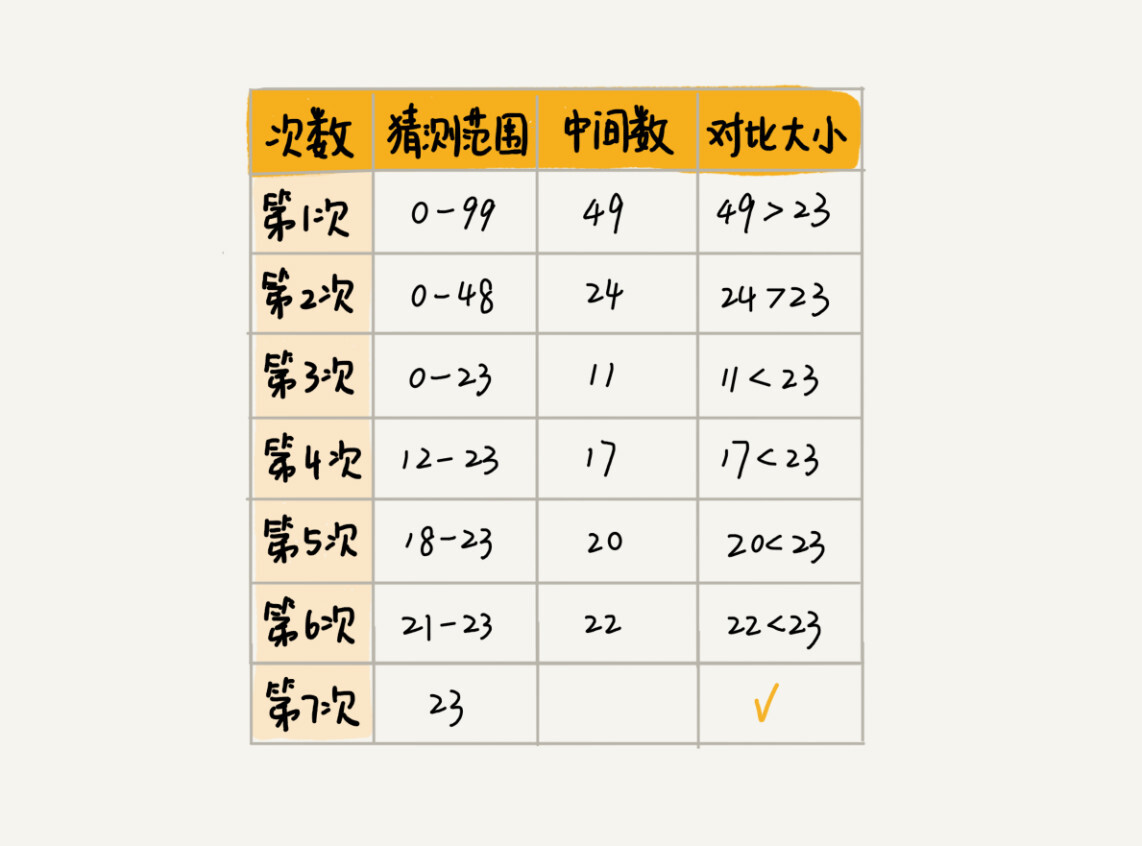
7次就猜出来了,是不是很快?这个例子用的就是二分思想,按照这个思想,即便我让你猜的是0到999的数字,最多也只要10次就能猜中。不信的话,你可以试一试。
这是一个生活中的例子,我们现在回到实际的开发场景中。假设有1000条订单数据,已经按照订单金额从小到大排序,每个订单金额都不同,并且最小单位是元。我们现在想知道是否存在金额等于19元的订单。如果存在,则返回订单数据,如果不存在则返回null。
最简单的办法当然是从第一个订单开始,一个一个遍历这1000个订单,直到找到金额等于19元的订单为止。但这样查找会比较慢,最坏情况下,可能要遍历完这1000条记录才能找到。那用二分查找能不能更快速地解决呢?
为了方便讲解,我们假设只有10个订单,订单金额分别是:8,11,19,23,27,33,45,55,67,98。
还是利用二分思想,每次都与区间的中间数据比对大小,缩小查找区间的范围。为了更加直观,我画了一张查找过程的图。其中,low和high表示待查找区间的下标,mid表示待查找区间的中间元素下标。
99%的人还看了
相似问题
- “三面一体”的业务调度方案在运营商订单运营的实践
- 基于灰色神经网络的预测算法——订单需求预测
- 以订单退款流程为例,聊聊如何优化策略模式
- web3通过antd 在React dapp中构建订单组件基本结构
- 数据分析实战 - 2 订单销售数据分析(pandas 进阶)
- Android sqlite分页上传离线订单后删除
- python django获取某个角色的某个数据和——例如:获取所有订单的应付金额总和
- 机器视觉能不能再火爆?大多数企业订单减少是现实,大多数企业维持现有的经营状态将会非常困难,就看人工智能和新兴产业能不能破门而入
- 在销售区域 销售范围 <‘5100‘,‘20‘,‘00‘> 中, 订单类型 ZO05 没有定义
- 淘宝API接口获取商品信息,订单管理,库存管理,数据分析
猜你感兴趣
版权申明
本文"15 _ 二分查找(上):如何用最省内存的方式实现快速查找功能?":http://eshow365.cn/6-32920-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!