数据分析实战 - 2 订单销售数据分析(pandas 进阶)
最佳答案 问答题库818位专家为你答疑解惑
题目来源:和鲸社区的题目推荐:
刷题源链接(用于直接fork运行
https://www.heywhale.com/mw/project/6527b5560259478972ea87ed
刷题准备
请依次运行这部分的代码(下方4个代码块),完成刷题前的数据准备
数据准备:
链接:https://pan.baidu.com/s/1F7iyHys1edRaOTR0LzxiYQ?pwd=m1ve
提取码:m1ve
–来自百度网盘超级会员V4的分享
导包及读取数据
import pandas as pd
# 如遇到OSerror,可以稍等十几秒,等待数据加载完成即可读取df = pd.read_csv("./data/order.csv")
df.head()
数据预处理
# 删除重复值
# df.drop_duplicates(inplace=True)
df.drop_duplicates(inplace = True)
# 查看数据信息
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 60391 entries, 0 to 60397
Data columns (total 17 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 订单日期 60391 non-null object 1 年份 60391 non-null int64 2 订单数量 60391 non-null int64 3 产品ID 60391 non-null int64 4 客户ID 60391 non-null object 5 交易类型 60391 non-null int64 6 销售区域ID 60391 non-null int64 7 销售大区 60391 non-null object 8 国家 60391 non-null object 9 区域 60391 non-null object 10 产品类别 60391 non-null object 11 产品型号名称 60391 non-null object 12 产品名称 60391 non-null object 13 产品成本 60391 non-null float6414 利润 60391 non-null float6415 单价 60391 non-null float6416 销售金额 60391 non-null float64
dtypes: float64(4), int64(5), object(8)
memory usage: 8.3+ MB
数据集中无缺失值,因此不需要进行缺失值处理
开始刷题
任务1
主管想了解 2013-2016 年各年份的总销售额情况,需要你统计各年份的销售金额,并依据年份降序输出各年的总销售额。
# 你的代码# 观察年份
df['年份'].unique() # array([2016, 2015, 2014, 2013])
# 直接根据年份根据销售金额统计总销售额
gmv_by_year = df.groupby(by = ['年份'])['销售金额'].sum().reset_index().sort_values(by = ['年份'],ascending = False)
gmv_by_year
任务2
主管想了解在 2013-2016 年各月份的订单数量都有多少?
需要你新增一列数据记录每笔订单的购买年份及月份信息,其值需从订单日期中拆分出来,之后再统计各月份的订单数量并输出订单数量最多的月份,同时并分析订单数量的时间变化趋势。
思考:订单数量是否可以直接使用
sum()方法直接统计? 回答:订单数量只有1,意味着是每一单一行数据,sum()会漏掉空值,如果存在的空值的话,单纯计数使用size()会更好一些。
df['订单数量'].unique()
array([1], dtype=int64)
# 你的代码# 抽取月份信息
df['月份'] = pd.to_datetime(df['订单日期']).dt.strftime("%m")
# 分年分月汇总数据
gmv_by_month = df.groupby(by = ['年份','月份'])['销售金额'].size().reset_index().sort_values(by = ['年份'],ascending = False)
gmv_by_month.columns = ['年份','月份','订单数量']
gmv_by_month.head()
# 使用idxmax()找到订单数量最多的行
max_order_index = gmv_by_month['订单数量'].idxmax()
# 根据上一步找到的索引,使用loc定位这一行
max_order_row = gmv_by_month.loc[max_order_index]
# 输出结果
print(f"订单数量最多的年月为{max_order_row['年份']}-{max_order_row['月份']},订单数量为{max_order_row['订单数量']}")
订单数量最多的年月为2016-06,订单数量为5544
任务3*
主管想了解 2016 年各个国家的订单数量、销售额及利润详情;
需要你统计在 2016年间各国的订单数量、销售额及利润并依据年份输出结果。
# 你的代码
# 指定年份,分国家的订单数量汇总,销售额求和,利润求和
country_2016 = df[df['年份']==2016].groupby(by = ['国家'])['订单数量','销售金额','利润'].sum().reset_index()
country_2016
C:\Users\chengyuanting\AppData\Local\Temp\ipykernel_14224\3368580504.py:3: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.country_2016 = df[df['年份']==2016].groupby(by = ['国家'])['订单数量','销售金额','利润'].sum().reset_index()
任务4*
主管想了解在 2013-2016 年间哪些产品所带来的利润最高;
需要你统计不同产品(产品名称)的订单数量,并根据该产品所属类别(产品类别)分别输出不同类别产品订单数量最多的前 3 种产品。
# 你的代码
# 根据产品类别,产品名称分组,汇总订单数量。根据订单数量降序取前三
goods_grouped = df.groupby(by = ['产品类别','产品名称'])['订单数量'].sum().reset_index()
goods_grouped
# 接着获取每个产品类别的前三订单数量的产品# 已产品类别继续分组,直接在分组的结果上应用nlargest()
goods_top3 = goods_grouped.groupby(by = ['产品类别']).apply(lambda x:x.nlargest(3,'订单数量')).reset_index(drop = True)
goods_top3
说明:
1:apply函数中的x在此处代表dataframe的每个分组
2:nlargest()使用方法举例:
df.nlargest(3, '订单数量') df['订单数量'].nlargest(3)
任务5 (方法一:直接写逻辑,重点理解apply的用法)
主管想了解在面向中国的订单中,各月份的订单数量以及利润是怎样的情况;
需要你统计面向中国的各月份订单数量及利润,并同时输出这个订单数量和利润的同比增长及环比增长。
# 你的代码
# 筛选中国的数据,按月汇总订单数量及利润
china_describe = df[df['国家']=='中国'].groupby(by = ['年份','月份'])['订单数量','利润'].sum().reset_index()
china_describe.head() # 观察数据
C:\Users\chengyuanting\AppData\Local\Temp\ipykernel_14224\3318811943.py:3: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.china_describe = df[df['国家']=='中国'].groupby(by = ['年份','月份'])['订单数量','利润'].sum().reset_index()
china_describe
df[:1]['订单数量']
0 1
Name: 订单数量, dtype: int64
df[:1]['订单数量'].values
array([1], dtype=int64)
df[:1]['订单数量'].values[0]
1
# 计算上述两个维度的同比增长以及环比增长
def calculate_yoy(row, column_name):"""它需要当前行和列名称作为参数,并查找去年同月的数据。如果找到了去年的数据,它将计算增长率;否则返回 None。"""last_year = china_describe[(china_describe['年份'] == row['年份'] - 1) & (china_describe['月份'] == row['月份'])]if last_year.empty:return Nonereturn (row[column_name] - last_year[column_name].values[0]) / last_year[column_name].values[0] * 100def calculate_mom(row, column_name):last_month_year = row['年份']if row['月份'] == '01':last_month_month = '12'last_month_year -= 1else:last_month_month = str(int(row['月份']) - 1).zfill(2) # zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0。last_month = china_describe[(china_describe['年份'] == last_month_year) & (china_describe['月份'] == last_month_month)]if last_month.empty:return Nonereturn (row[column_name] - last_month[column_name].values[0]) / last_month[column_name].values[0] * 100china_describe['订单数量同比'] = china_describe.apply(lambda row: calculate_yoy(row, '订单数量'), axis=1)
china_describe['订单数量环比'] = china_describe.apply(lambda row: calculate_mom(row, '订单数量'), axis=1)
china_describe['利润同比'] = china_describe.apply(lambda row: calculate_yoy(row, '利润'), axis=1)
china_describe['利润环比'] = china_describe.apply(lambda row: calculate_mom(row, '利润'), axis=1)
china_describe
提问:为什么上述计算中取值要使用.values[0]取值呢?
回答:# 因为使用apply对每一行数据进行计算,得到的去年数据也是一行,不能使用df[column_name][index]这种方式取值。
索引过程示例:
df[:1]['订单数量'] '''
output:
0 1
Name: 订单数量, dtype: int64
''' df[:1]['订单数量'].values # output : array([1]) df[:1]['订单数量'].values[0] # output : 1 ;正确的取值方式 提问:apply函数应用在DataFrame的行或列中,也可以应用到单独一个Series的每个元素中,我如何判断此处是针对行还是列,还是行的某个值?
回答:当您在 pandas 中使用 apply 函数,是否应用于行还是列主要取决于参数 axis 的值。
axis=0或者不指定axis:函数会应用于每一列,即针对列进行操作。axis=1:函数会应用于每一行,即针对行进行操作。
在我们之前的代码中:
df['订单数量同比'] = df.apply(lambda row: calculate_yoy_corrected(row, '订单数量'), axis=1)
我们指定了 axis=1,这意味着 apply 函数将 lambda 函数应用于数据帧的每一行。lambda 函数会将整行数据(即当前行的所有列值)作为参数传递给 calculate_yoy_corrected 函数,这就是为什么我们可以在 calculate_yoy_corrected 函数内部访问行的 ‘年份’ 和 ‘月份’ 列的值。
如果您将 apply 函数应用于一个 Series,那么该函数会应用于 Series 的每个元素。例如:
df['年份'].apply(lambda x: x + 1)
上述代码会将每个 ‘年份’ 值加 1。
总之,要确定 apply 是应用于行还是列,您可以查看 axis 参数的值。如果 apply 是直接应用于一个 Series,那么它会应用于该 Series 的每个元素。
提问2:lambda函数在处理数据的时候一行一行读取,但是计算是根据整体的数据计算的吗,因为涉及环比同比计算不可能只根据一行数据计算
您是对的。当 apply 函数与 lambda 函数一起使用并设置为 axis=1 时,lambda 函数确实会逐行处理数据。但是,当我们在 lambda 函数内部调用其他函数(如 calculate_yoy 或 calculate_mom)时,那些函数可以访问并使用整个数据框 df 来进行计算。
例如,在我们的 calculate_mom 函数中:
last_month = df[(df['年份'] == last_month_year) & (df['月份'] == last_month_month)]
这里,我们使用整个 df 数据框来查找上个月的数据,尽管 apply 函数正在处理当前行。
因此,虽然 lambda 函数逐行处理数据,但它内部调用的函数可以使用整个数据框进行计算。这正是我们能够计算环比和同比的原因,因为这些计算需要查看其他月份的数据。
任务5 (方法二:简便方法,推荐)
需要注意的是,时间需要升序排列,这样计算出来的才是正确的
# 筛选中国的数据,按月汇总订单数量及利润
china_describe2 = df[df['国家']=='中国'].groupby(by = ['年份','月份'])['订单数量','利润'].sum().reset_index()
china_describe2.head() # 观察数据
C:\Users\chengyuanting\AppData\Local\Temp\ipykernel_14224\3967723160.py:2: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.china_describe2 = df[df['国家']=='中国'].groupby(by = ['年份','月份'])['订单数量','利润'].sum().reset_index()
china_describe2['订单数量环比'] = china_describe2['订单数量'].pct_change().fillna(0)*100
china_describe2['利润环比'] = china_describe2['利润'].pct_change().fillna(0)*100
china_describe2['订单数量同比'] = china_describe2.groupby(by = ['月份'])['订单数量'].pct_change().fillna(0)*100
china_describe2['利润同比'] = china_describe2.groupby(by = ['月份'])['利润'].pct_change().fillna(0)*100
china_describe2
提问:计算同比使用了groupby,这样经过分组计算的数据,和直接计算的数据放一起不会造成对应不上的麻烦吗
回答:伟大的观察!
当您将’ groupby() ‘与’ pct_change() ‘等操作结合使用时,结果数据仍然保留其原始顺序和索引,并且该操作应用于每个组。因此,即使在分组并应用’ pct_change() '方法之后,数据的顺序仍然保持不变,并且结果与原始数据正确地对齐。
在前面的代码中:
df['订单数量_YoY '] = df.groupby(“月份”)(“订单数量的].pct_change () .fillna (0) * 100
事情是这样的:
- 数据按“月”进行分组。
- 在每个月份组中,’ pct_change() '方法计算同比变化。
- 结果保留了原始DataFrame的顺序和索引。
- 计算同比变化分配给新列”订单数量_YoY”。
因此,数据中没有不匹配或不对齐。计算值与DataFrame中的原始行正确对齐。
提问:如果分组后跟着聚合函数比如sum也会不变吗,或者说.fillna函数很重要,即使使用了聚合函数,因为会被填充数字,也不会担心顺序对不上的情况
回答:你的问题涉及到熊猫行为的几个细微差别。让我们来分析一下:
- ** ’ groupby() ‘后面跟着转换(如’ pct_change() ')😗*
当您使用’ groupby() ‘和’ pct_change() '等转换函数时,生成的Series或DataFrame将保持与原始序列相同的形状和索引。这确保了转换后的数据与原始数据保持一致。
- ** ’ groupby() ‘后面跟着聚合(如’ sum() ')😗*
当您使用’ groupby() ‘后面跟着’ sum() ‘这样的聚合函数时,生成的Series或DataFrame通常更小(除非使用’ as_index=False '),因为它将数据聚合到组中。这意味着如果没有进一步处理,结果数据可能不会直接与原始数据对齐。
- ** ’ .fillna() '的作用:**
’ .fillna() ‘方法用于处理缺失值(nan)。在前面的代码中,它的主要作用是在计算’ pct_change() '时处理由每组中的第一个值产生的nan。它不会直接影响数据的形状或对齐方式。然而,重要的是要使用它来确保丢失的值得到适当的处理。
总结:
-对于像’ pct_change() ‘这样的转换,数据在’ groupby() ‘之后保持其形状,确保对齐。
-对于像’ sum() '这样的聚合,数据可能不会保持其原始形状,从而导致潜在的不对齐。
- ’ .fillna() '方法对于处理nan是必不可少的,但它本身并不影响数据对齐。
如果您不确定如何转换数据,那么在每一步检查结果或使用较小的数据子集来测试和理解转换总是一个很好的做法。
任务5 (方法三:方法二的进一步优化,推荐方法)
计算同比增长率和环比增长率,使用pct_change这个函数可以用来计算百分比变化率,当periods=1计算的是环比增长率,当periods=12计算的是同比增长率
# 筛选中国的数据,按月汇总订单数量及利润
china_describe3 = df[df['国家']=='中国'].groupby(by = ['年份','月份'])['订单数量','利润'].sum().reset_index()
china_describe3.head() # 观察数据
# 计算同环比
china_describe3['订单数量环比'] = china_describe3['订单数量'].pct_change()*100
china_describe3['利润环比'] = china_describe3['利润'].pct_change()*100
china_describe3['订单数量同比'] = china_describe3['订单数量'].pct_change(periods = 12)*100
china_describe3['利润同比'] = china_describe3['利润'].pct_change(periods = 12)*100
china_describe3
C:\Users\chengyuanting\AppData\Local\Temp\ipykernel_14224\2071208107.py:2: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.china_describe3 = df[df['国家']=='中国'].groupby(by = ['年份','月份'])['订单数量','利润'].sum().reset_index()
任务6
主管想了解面向 中国 的订单中,哪个销售大区在 2016 年的订单数量以及利润最高?
需要你统计输出其结果,同时,主管还想知道不同销售大区的订单数量最多的产品、最少的产品分别是哪几类(产品类型),需要你统计并输出其结果。
# 你的代码
# 输出中国地区各销售大区2016年的订单数量以及最高利润
china_bigarea_2016 = df[(df['国家']=='中国') & (df['年份']==2016)].groupby(by = ['销售大区'])['订单数量','利润'].sum().reset_index()
print(china_bigarea_2016,'\n')
print(f"中国2016年{china_bigarea_2016['销售大区'][china_bigarea_2016['订单数量'].idxmax()]}的订单数量最高,订单数量为:{china_bigarea_2016['订单数量'][china_bigarea_2016['订单数量'].idxmax()]};\n{china_bigarea_2016['销售大区'][china_bigarea_2016['利润'].idxmax()]}的利润最高,利润为:{china_bigarea_2016['利润'][china_bigarea_2016['利润'].idxmax()]}",'\n')# 不同销售大区订单数量最多/最少的产品类型是哪些
china_bigarea_2016_2 = df[(df['国家']=='中国') & (df['年份']==2016)].groupby(by = ['销售大区','产品类别'])['订单数量'].sum().reset_index()
# print(china_bigarea_2016_2,'\n')
# 不同销售大区订单数量最多的产品类型
china_bigarea_2016_2_max = china_bigarea_2016_2.groupby(by = ['销售大区']).apply(lambda x:x.nlargest(1,'订单数量')).reset_index(drop = True)
print(china_bigarea_2016_2_max,'\n')
# 不同销售大区订单数量最少的产品类型
china_bigarea_2016_2_min = china_bigarea_2016_2.groupby(by = ['销售大区']).apply(lambda x:x.nsmallest(1,'订单数量')).reset_index(drop = True)
print(china_bigarea_2016_2_min,'\n')
销售大区 订单数量 利润
0 东北区 15 6529.89
1 东南区 30 7592.59
2 中部 10 4207.80
3 西北区 4952 1583580.11
4 西南区 6624 1923326.09 中国2016年西南区的订单数量最高,订单数量为:6624;
西南区的利润最高,利润为:1923326.09 销售大区 产品类别 订单数量
0 东北区 配件 11
1 东南区 配件 20
2 中部 配件 8
3 西北区 配件 3316
4 西南区 配件 4273 销售大区 产品类别 订单数量
0 东北区 球 1
1 东南区 球 4
2 中部 服装 2
3 西北区 球 750
4 西南区 服装 1139
C:\Users\chengyuanting\AppData\Local\Temp\ipykernel_14224\973851953.py:3: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.china_bigarea_2016 = df[(df['国家']=='中国') & (df['年份']==2016)].groupby(by = ['销售大区'])['订单数量','利润'].sum().reset_index()
任务7
主管想了解在所有订单中,服装类(产品类别)产品的整体订单数量月变化趋势如何,需要你统计并依据年份输出各月份的订单数量。
# 你的代码
# 获取服装品类的数据
cloth_cat_by_month = df[df['产品类别']=='服装'].groupby(by = ['年份','月份'])['订单数量'].sum().reset_index()
cloth_cat_by_month
# 绘图观察数据变化趋势
import pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# Convert 年份 and 月份 to a single datetime column
cloth_cat_by_month['年月'] = pd.to_datetime(cloth_cat_by_month['年份'].astype(str) + '-' + cloth_cat_by_month['月份'].astype(str) )# Plot
plt.figure(figsize=(12, 6))
plt.plot(cloth_cat_by_month['年月'], cloth_cat_by_month['订单数量'], marker='o', linestyle='-')# Adding data labels
for idx, row in cloth_cat_by_month.iterrows():plt.annotate(row['订单数量'], (row['年月'], row['订单数量']), textcoords="offset points", xytext=(0,5), ha='center')plt.title('服装订单数量随时间变化趋势')
plt.xlabel('年月')
plt.ylabel('订单数量')
plt.grid(True)
plt.tight_layout() # 自动调整子图的位置,在某些情况下,如果不使用tight_layout(), 图形元素可能会重叠或被剪裁。
plt.show()
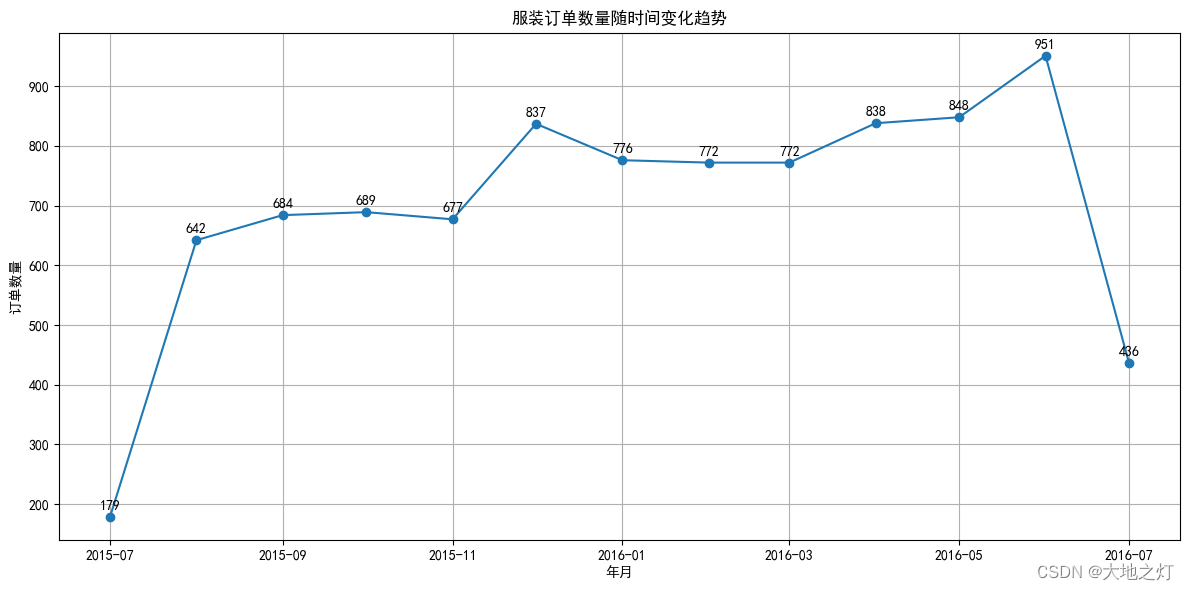
任务8
基于任务7的输出结果,主管需要你统计在各年份订单数量最低的月份里,在 服装类(产品类别)的产品中,哪些产品(产品名称)的订单是最少的?
# 你的代码# 获取服装名称的数据
cloth_goods_by_month = df[df['产品类别']=='服装'].groupby(by = ['年份','月份','产品名称'])['订单数量'].sum().reset_index()
# 获取7月数据,因为7月订单数量最低
cloth_goods_by_month_7 = cloth_goods_by_month[cloth_goods_by_month['月份']=='07']
# 获取订单数量最低的产品名称
cloth_goods_by_month_7.groupby(by = ['年份','月份']).apply(lambda x : x.nsmallest(1,'订单数量')).reset_index(drop = True)
# 任务8补充,如果绘图数据展示不好分辨,还是需要判断订单数量最小的年月
# 筛选数据
cloth_goods_by_month_2 = df[df['产品类别']=='服装'].groupby(by = ['年份','月份'])['订单数量'].sum().reset_index()
# 找按年分组订单数量最小的索引
cloth_min_index = cloth_goods_by_month_2.groupby(by = ['年份'])['订单数量'].idxmin()
# 输出结果
cloth_min = cloth_goods_by_month_2.loc[cloth_min_index]
cloth_min
任务9
主管想知道在面向 中国 的 大中华区域 的订单中不同用户的购物特点是怎样的;
需要你先依据 客户ID 统计每位客户的购物次数及购物花费总金额,并在此基础计算每位客户的平均购物花费。
# 你的代码
# 该区域数据
dzh_of_china = df[(df['国家']=='中国') & (df['区域']=='大中华区')]
# 统计购物次数以及花费总金额
dzh_of_china_describe = dzh_of_china.groupby(by = ['客户ID'])['订单数量','销售金额'].sum().reset_index()
dzh_of_china_describe
# 该区域客户总数
dzh_kehu_counts = len(dzh_of_china_describe)
# 每位客户的平均花费
dzh_of_china_describe['平均购物花销'] = dzh_of_china_describe['销售金额']/ dzh_of_china_describe['订单数量']
dzh_of_china_describe
C:\Users\chengyuanting\AppData\Local\Temp\ipykernel_14224\4058715340.py:5: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.dzh_of_china_describe = dzh_of_china.groupby(by = ['客户ID'])['订单数量','销售金额'].sum().reset_index()
7819 rows × 4 columns
任务10
根据任务9所计算的结果,主管想更加直观的了解不同客户的购物特点,
需要你新增两列分别对客户购物次数以及平均购物花费进行分组划分,针对购物次数可以划分为"高"、"中"、"低"等共三种频次;
针对平均购物花费可将其划分为 "高"、"中"、"低"三种消费等级;
之后再将两列结果进行合并,经过排列组合形成如 "高高"、"高中"等共九种用户购物特征;
最后再统计不同特征的用户最喜欢购买的产品(产品类别)是哪些,并将结果输出。
任务10 方法一:均等分箱
# 定义箱子
bins_order = [0,dzh_of_china_describe['订单数量'].quantile(0.33),dzh_of_china_describe['订单数量'].quantile(0.66),dzh_of_china_describe['订单数量'].max()+1]
labels_order = ['低','中','高']bins_cost = [0,dzh_of_china_describe['平均购物花销'].quantile(0.33),dzh_of_china_describe['平均购物花销'].quantile(0.66),dzh_of_china_describe['平均购物花销'].max()+1]
labels_cost = ['低','中','高']# 为消费频次等级和购物等级两列
dzh_of_china_describe['购物频次'] = pd.cut(dzh_of_china_describe['订单数量'],bins = bins_order,labels = labels_order,right = False)
dzh_of_china_describe['消费等级'] = pd.cut(dzh_of_china_describe['平均购物花销'],bins = bins_cost,labels = labels_cost,right = False)# 合并两种购物特征
dzh_of_china_describe['购物特征'] = dzh_of_china_describe['购物频次'].astype('str') + dzh_of_china_describe['消费等级'].astype('str')# 将购物特征合并到大众华区的数据上
merged_df = pd.merge(dzh_of_china,dzh_of_china_describe[['客户ID','购物特征']],on = '客户ID')# 输出偏好产品
# favorite_products = merged_df.groupby(by = ['购物特征'])['产品类别'].apply(lambda x : x.value_counts().nlargest(1))
favorite_products = merged_df.groupby(by = ['购物特征'])['产品类别'].apply(lambda x : x.value_counts().idxmax())
favorite_products
购物特征
中中 配件
中低 球
中高 配件
低中 配件
低低 球
低高 配件
高中 配件
高低 球
高高 配件
Name: 产品类别, dtype: object
cut函数的right参数决定了区间的闭合方式。
- 如果
right=True(默认值):则每个区间的右边是闭合的,也就是说,区间会是这样的形式:[a, b]、[b, c]、[c, d] 等。 - 如果
right=False:则每个区间的左边是闭合的,也就是说,区间会是这样的形式:(a, b]、(b, c]、(c, d] 等。
具体例子:
考虑一个简单的数据集:[1, 2, 3, 4, 5]和一个区间边界[1, 3, 5]。
- 使用
right=True,数据将被分箱为:[1, 3] 和 [3, 5]。此时,数字3将属于第二个箱子。 - 使用
right=False,数据将被分箱为:(1, 3] 和 (3, 5]。此时,数字3将属于第一个箱子。
因此,right参数的值会影响数据点如何被分配到不同的箱子中。
任务10 方法二:聚类分箱
dzh_of_china_describe2 = dzh_of_china_describe[['客户ID','订单数量','销售金额','平均购物花销']].copy()
dzh_of_china_2 = dzh_of_china.copy()
from sklearn.cluster import KMeans# Using K-means for clustering binning on "订单数量"
kmeans_order = KMeans(n_clusters=3, random_state=0).fit(dzh_of_china_describe2[['订单数量']])
dzh_of_china_describe2['购物频次_cluster'] = kmeans_order.labels_# Map the cluster labels to the desired labels: '低', '中', '高'
order_centers = kmeans_order.cluster_centers_.flatten()
order_label_map = {i: '低' if center == min(order_centers) else '高' if center == max(order_centers) else '中' for i, center in enumerate(order_centers)}
dzh_of_china_describe2['购物频次'] = dzh_of_china_describe2['购物频次_cluster'].map(order_label_map)# Drop the cluster label column
dzh_of_china_describe2.drop('购物频次_cluster', axis=1, inplace=True)dzh_of_china_describe2C:\Users\chengyuanting\AppData\Roaming\Python\Python39\site-packages\sklearn\cluster\_kmeans.py:1416: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warningsuper()._check_params_vs_input(X, default_n_init=10)
7819 rows × 5 columns
# Using K-means for clustering binning on "平均购物花销"
kmeans_cost = KMeans(n_clusters=3, random_state=0).fit(dzh_of_china_describe2[['平均购物花销']])
dzh_of_china_describe2['消费等级_cluster'] = kmeans_cost.labels_# Map the cluster labels to the desired labels: '低', '中', '高'
cost_centers = kmeans_cost.cluster_centers_.flatten()
cost_label_map = {i: '低' if center == min(cost_centers) else '高' if center == max(cost_centers) else '中' for i, center in enumerate(cost_centers)}
dzh_of_china_describe2['消费等级'] = dzh_of_china_describe2['消费等级_cluster'].map(cost_label_map)# Drop the cluster label column
dzh_of_china_describe2.drop('消费等级_cluster', axis=1, inplace=True)dzh_of_china_describe2
C:\Users\chengyuanting\AppData\Roaming\Python\Python39\site-packages\sklearn\cluster\_kmeans.py:1416: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warningsuper()._check_params_vs_input(X, default_n_init=10)
7819 rows × 6 columns
# 合并两种购物特征
dzh_of_china_describe2['购物特征'] = dzh_of_china_describe2['购物频次'].astype('str') + dzh_of_china_describe2['消费等级'].astype('str')# 将购物特征合并到大众华区的数据上
merged_df2 = pd.merge(dzh_of_china,dzh_of_china_describe2[['客户ID','购物特征']],on = '客户ID')# 输出偏好产品
# favorite_products2 = merged_df2.groupby(by = ['购物特征'])['产品类别'].apply(lambda x : x.value_counts().nlargest(1))
favorite_products2 = merged_df2.groupby(by = ['购物特征'])['产品类别'].apply(lambda x : x.value_counts().idxmax())
favorite_products2
购物特征
中中 配件
中低 配件
中高 配件
低中 配件
低低 配件
低高 配件
高中 配件
高低 配件
高高 配件
Name: 产品类别, dtype: object
提问:上述聚类分箱时,是怎么保证高的数据不会打错高中低标签呢
回答:
当我们使用K-means聚类进行分箱时,算法会为我们的数据找到三个中心(假设我们选择了3个簇)。这三个中心分别代表了数据的三个“平均”或“典型”值。为了将这三个中心与“低”、“中”和“高”标签正确地匹配起来,我们执行了以下操作:
- 获取这三个中心的值。
- 找到这三个值中的最小值、最大值和中间值。
- 将最小值映射到“低”,将最大值映射到“高”,将中间值映射到“中”。
通过这种方式,我们确保了正确地标记了每个数据点的标签。
这是上述代码的相关部分,用于映射簇标签到我们的“低”、“中”和“高”标签:
order_centers = kmeans_order.cluster_centers_.flatten()
order_label_map = {i: '低' if center == min(order_centers) else '高' if center == max(order_centers) else '中' for i, center in enumerate(order_centers)}
df['购物频次'] = df['购物频次_cluster'].map(order_label_map)
在这里,order_centers是我们得到的三个中心的值,然后我们使用字典推导式为每个中心创建一个映射,最后使用map函数应用这个映射到数据框中的簇标签上。
99%的人还看了
相似问题
- “三面一体”的业务调度方案在运营商订单运营的实践
- 基于灰色神经网络的预测算法——订单需求预测
- 以订单退款流程为例,聊聊如何优化策略模式
- web3通过antd 在React dapp中构建订单组件基本结构
- 数据分析实战 - 2 订单销售数据分析(pandas 进阶)
- Android sqlite分页上传离线订单后删除
- python django获取某个角色的某个数据和——例如:获取所有订单的应付金额总和
- 机器视觉能不能再火爆?大多数企业订单减少是现实,大多数企业维持现有的经营状态将会非常困难,就看人工智能和新兴产业能不能破门而入
- 在销售区域 销售范围 <‘5100‘,‘20‘,‘00‘> 中, 订单类型 ZO05 没有定义
- 淘宝API接口获取商品信息,订单管理,库存管理,数据分析
猜你感兴趣
版权申明
本文"数据分析实战 - 2 订单销售数据分析(pandas 进阶)":http://eshow365.cn/6-31554-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 【Linux】Linux文件IO常规操作
- 下一篇: 阿里云多款ECS产品全面升级 性能最多提升40%