0基础学习PyFlink——使用DataStream进行字数统计
最佳答案 问答题库488位专家为你答疑解惑
大纲
- source
- Map
- Splitting
- Mapping
- Reduce
- Keying
- Reducing
- 完整代码
- 结构
- 参考资料
在《0基础学习PyFlink——模拟Hadoop流程》一文中,我们看到Hadoop在处理大数据时的MapReduce过程。
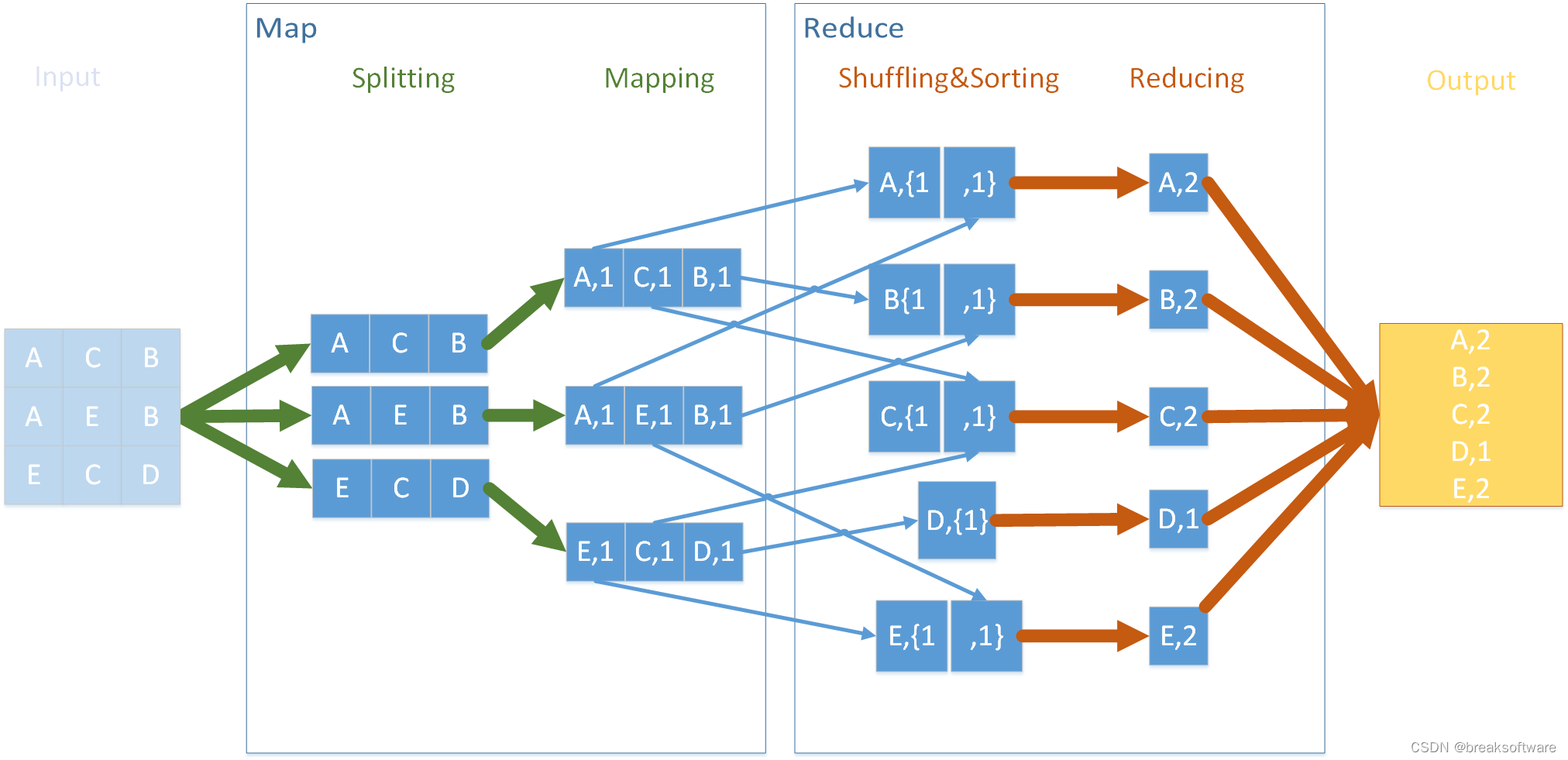
本节介绍的DataStream API,则使用了类似的结构。
source
为了方便,我们依然使用from_collection从内存中读取数据。
和使用Table API类似,我们给from_collection传递的第二参数是每行数据类型。本例中是String,即“A C B”的类型。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionModeword_count_data = ["A C B","A E B","E C D"]def word_count():env = StreamExecutionEnvironment.get_execution_environment()env.set_runtime_mode(RuntimeExecutionMode.BATCH)# write all the data to one fileenv.set_parallelism(1)source_type_info = Types.STRING()# define the sourcesource = env.from_collection(word_count_data, source_type_info)
可以使用下面指令输出source内容
source.print()
A C B
A E B
E C D
Map
和上图一样,Map由Splitting和Mapping组成。它们分别将数据切割成做小运算单元,和生成map结构。
Splitting
def split(line):for s in line.split():yield ssplitted = source.flat_map(split)
上述splitted的结构输出是
A
C
B
A
E
B
E
C
D
Mapping
Mapping的操作就是将之前的数组结构转换成map结构
mapped=splitted.map(lambda i: (i, 1), Types.TUPLE([Types.STRING(), Types.INT()]))
mapped的输出值如下,可以看到它还是按我们输入数据的顺序排列的。
(A,1)
(C,1)
(B,1)
(A,1)
(E,1)
(B,1)
(E,1)
(C,1)
(D,1)
Reduce
Keying
这一步对应于上图中的Shuffling&Sorting,它会将相同key的数据进行分区,以供后面reducing操作使用。
keyed=mapped.key_by(lambda i: i[0])
可以看到keyed数据已经经过排序和聚合了。
(A,1)
(A,1)
(B,1)
(B,1)
(C,1)
(C,1)
(D,1)
Reducing
reduced=keyed.reduce(lambda i, j: (i[0], i[1] + j[1]))
reduce的方法有如下注释
Applies a reduce transformation on the grouped data stream grouped on by the given
key position. TheReduceFunctionwill receive input values based on the key value.
Only input values with the same key will go to the same reducer.
特别是最后一句非常有用“Only input values with the same key will go to the same reducer”(只有相同Key的输入数据才会进入相同的Reducer中)。这句话意味着上述Keyed的数据会被分组执行,于是就不会出现计算错乱。
(A,2)
(B,2)
(C,2)
(D,1)
(E,2)
完整代码
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionModeword_count_data = ["A C B","A E B","E C D"]def word_count():env = StreamExecutionEnvironment.get_execution_environment()env.set_runtime_mode(RuntimeExecutionMode.BATCH)# write all the data to one fileenv.set_parallelism(1)source_type_info = Types.STRING()# define the sourcesource = env.from_collection(word_count_data, source_type_info)# source.print()def split(line):for s in line.split():yield ssplitted = source.flat_map(split) # splitted.print()mapped=splitted.map(lambda i: (i, 1), Types.TUPLE([Types.STRING(), Types.INT()]))# mapped.print()keyed=mapped.key_by(lambda i: i[0]) # keyed.print()reduced=keyed.reduce(lambda i, j: (i[0], i[1] + j[1]))# define the sinkreduced.print()# submit for executionenv.execute()if __name__ == '__main__':word_count()
结构
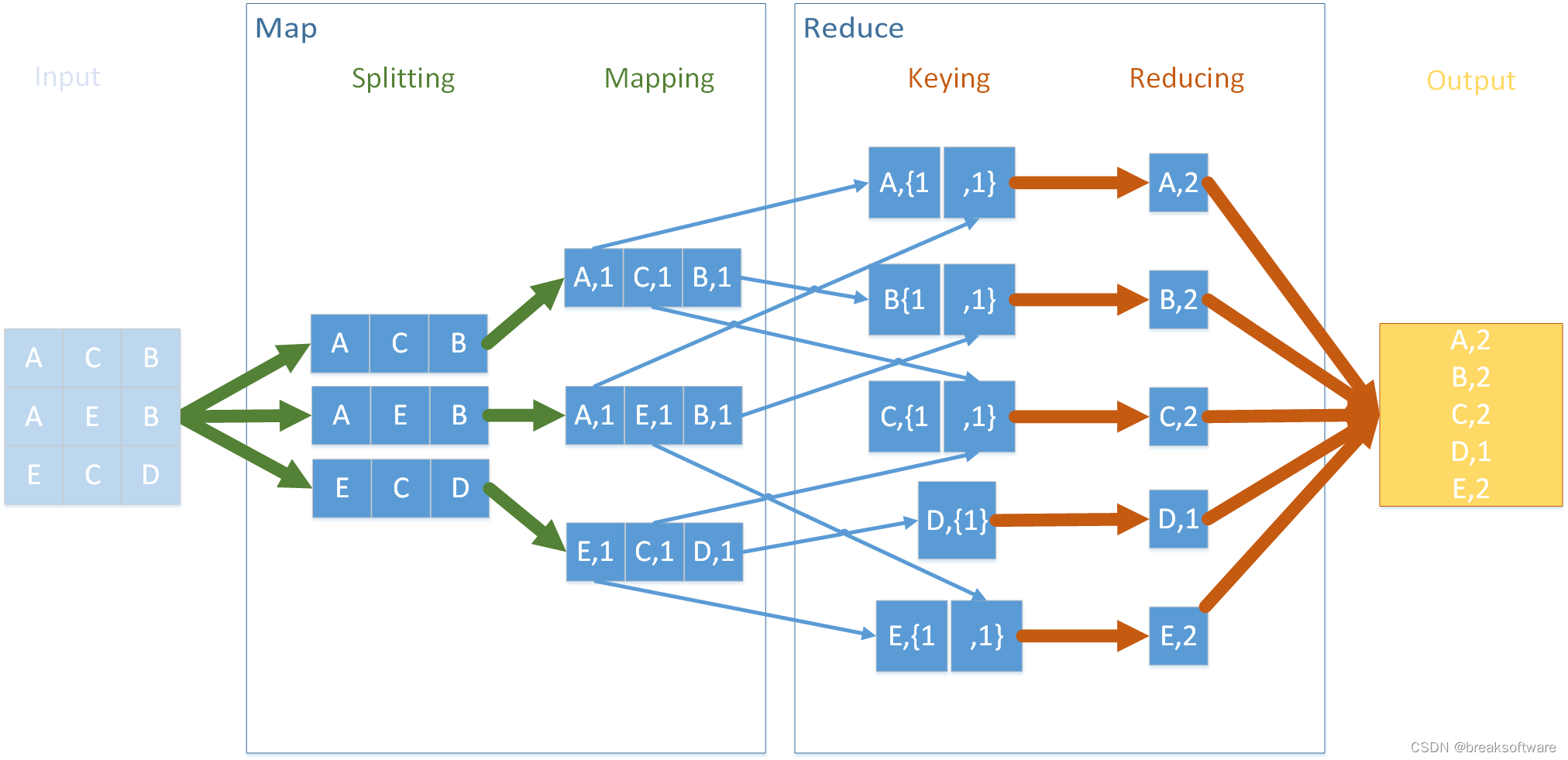
参考资料
- https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/python/datastream_tutorial/
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"0基础学习PyFlink——使用DataStream进行字数统计":http://eshow365.cn/6-31527-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 忆往事
- 下一篇: 二十三种设计模式全面解析-桥接模式的高级应用:构建灵活的跨平台UI框架