五、程序员指南:数据平面开发套件
最佳答案 问答题库1338位专家为你答疑解惑
服务质量 (QoS) 框架
本章介绍 DPDK 服务质量 (QoS) 框架。
21.1 带有 QoS 支持的数据包流水线
下图显示了一个具有 QoS 支持的复杂数据包处理流水线的示例
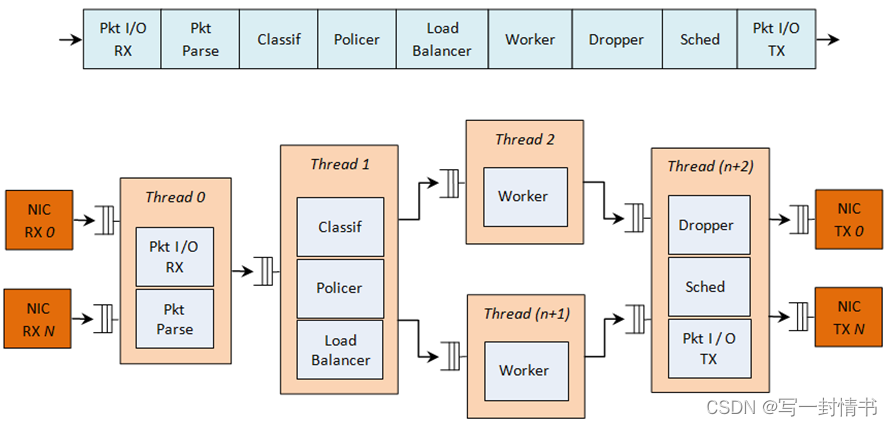
表21.1:带有 QoS 支持的复杂数据包处理流水线
这个流水线可以使用可重用的 DPDK 软件库构建。在这个流水线中实现 QoS 的主要模块有:policer(警察器)、dropper(丢包器)和scheduler(调度器)。下表提供了每个模块的功能描述
以下是在数据包处理流程中使用的基础设施模块列表
表21.2: 数据包处理流程使用的基础设施模块
数据包处理流程模块与 CPU 核心的映射可以根据每个特定应用程序所需的性能水平以及为每个模块启用的特性集进行配置。一些模块可能会消耗多个 CPU 核心(每个 CPU 核心在不同的输入数据包上运行相同模块的不同实例),而其他几个模块可能映射到同一个 CPU 核心上。
21.2 分层调度器
当存在分层调度器模块时,通常位于传输阶段之前的发送端(TX)位置。其目的是根据每个网络节点的服务级别协议(SLAs)指定的策略,优先传输来自不同用户和不同流量类别的数据包。
21.2.1 概述
分层调度器模块类似于网络处理器使用的流量管理器模块,通常实现每个流(或一组流)的数据包排队和调度。它通常充当缓冲区,能够在传输之前暂时存储大量数据包(入列操作)。随着网络接口控制器(NIC TX)请求更多要传输的数据包,这些数据包稍后会被移除并传递给 NIC TX,同时数据包选择逻辑会遵循预定义的SLAs(出列操作)。
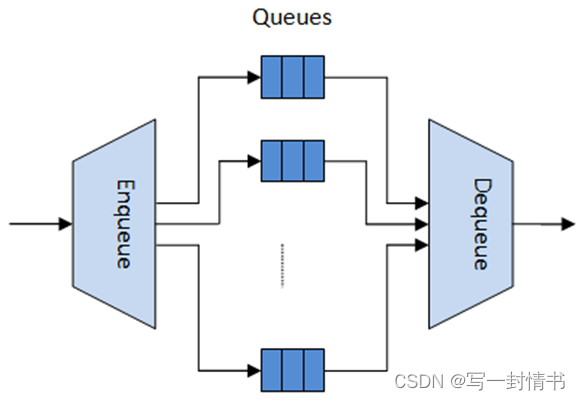
图 21.2:分层调度程序块内部图
调度层次结构优化了大量数据包队列的分层调度器。当只需要少量队列时,应使用消息传递队列而不是这个模块。详细讨论请参阅性能最差情况部分。
21.2.2 调度层次结构
调度层次结构如图21.3所示。层次结构的第一级是以太网TX端口 1/10/40 GbE,随后的层次级别被定义为子端口、管道、流量类和队列。
通常,每个子端口代表一个预定义的用户组,而每个管道代表一个单独的用户/订阅者。每个流量类是不同流量类型的表示,具有特定的丢包率、延迟和抖动要求,例如语音、视频或数据传输。每个队列托管来自同一用户的同一类型的一个或多个连接的数据包。
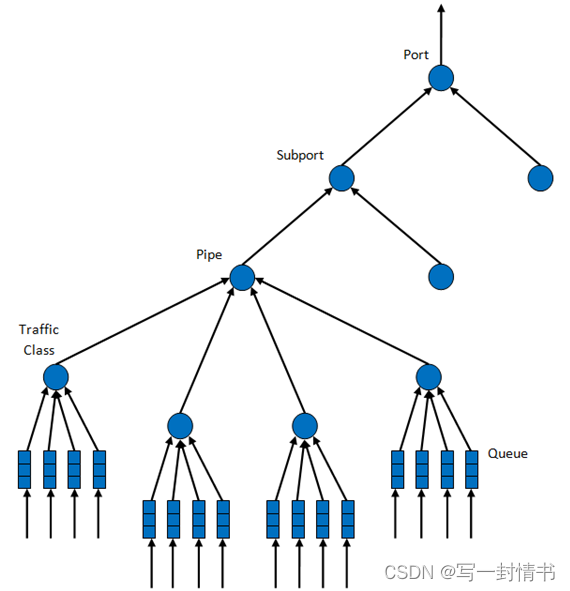
图 21.3:每个端口的调度层次结构
下表详细介绍了每个层级的功能。
表 21.3:端口调度层次结构
21.2.3 应用程序编程接口 (API)
端口调度器配置 API
rte_sched.h 文件包含用于端口、子端口和管道的配置函数。
端口调度器入队 API
端口调度器入队 API 与 DPDK PMD TX 函数的 API 非常相似。
int rte_sched_port_enqueue(struct rte_sched_port *port,
struct rte_mbuf **pkts,
uint32_t n_pkts);
端口调度器出队 API
端口调度器出队 API 与 DPDK PMD RX 函数的 API 非常相似
int rte_sched_port_dequeue(struct rte_sched_port *port,
struct rte_mbuf **pkts,
uint32_t n_pkts);
用法示例
/* 文件 "application.c" */
#define N_PKTS_RX 64
#define N_PKTS_TX 48
#define NIC_RX_PORT 0
#define NIC_RX_QUEUE 0
#define NIC_TX_PORT 1
#define NIC_TX_QUEUE 0
struct rte_sched_port *port = NULL;
struct rte_mbuf *pkts_rx[N_PKTS_RX], *pkts_tx[N_PKTS_TX];
uint32_t n_pkts_rx, n_pkts_tx;
/* 初始化 */
<初始化代码>
/* 运行时 */
while (1) {/* 从 NIC RX 队列读取数据包 */n_pkts_rx = rte_eth_rx_burst(NIC_RX_PORT, NIC_RX_QUEUE, pkts_rx, N_PKTS_RX);/* 分层调度器入队 */rte_sched_port_enqueue(port, pkts_rx, n_pkts_rx);/* 分层调度器出队 */n_pkts_tx = rte_sched_port_dequeue(port, pkts_tx, N_PKTS_TX);/* 将数据包写入 NIC TX 队列 */rte_eth_tx_burst(NIC_TX_PORT, NIC_TX_QUEUE, pkts_tx, n_pkts_tx);
}21.2.4 实现
每个端口的内部数据结构
内部数据结构的示意图显示在详细信息中
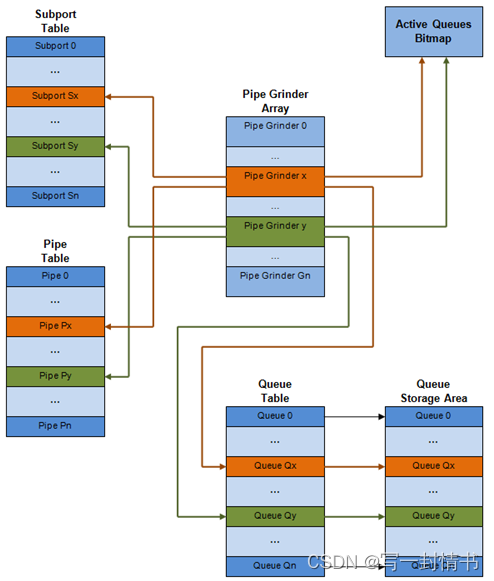
图 21.4:每个端口的内部数据结构
表 21.4:每个端口的调度程序内部数据结构
21.2. 层次调度器
多核扩展策略
多核扩展策略如下:
- 在不同的线程上运行不同的物理端口。同一端口的入队和出队由同一个线程处理。
- 通过在不同的线程上运行同一物理端口的不同子端口集合(虚拟端口)来将同一物理端口拆分到不同的线程上。类似地,一个子端口可以被拆分为多个由不同线程运行的子端口。同一端口的入队和出队由同一个线程处理。只有在性能原因上无法使用单个核处理完整个端口时才需要这样做。
同一输出端口的入队和出队
从不同核心对同一输出端口进行入队和出队操作可能会对调度器的性能造成显著影响,因此不建议这样做。
端口入队和出队操作共享以下数据结构的访问: - 包描述符
- 队列表
- 队列存储区域
- 活动队列的位图
性能下降的预期原因包括: - 需要使队列和位图操作线程安全,这要求使用锁原语进行访问序列化(例如自旋锁/信号量),或者使用原子原语进行无锁访问(例如测试和设置,比较和交换等)。在前一种情况下,影响要大得多。
- 在两个核心的缓存层次结构之间存储共享数据结构的缓存行的来回传输(由MESI协议缓存一致性CPU硬件透明地完成)。
因此,调度器的入队和出队操作必须从同一个线程运行,这允许队列和位图操作不是线程安全的,并将调度器数据结构保持在同一个核心内部。
性能扩展
增加NIC端口数量只需按比例增加用于流量调度的CPU核心数量。
入队管道
每个数据包的步骤顺序如下: - 访问mbuf以读取标识数据包目标队列所需的数据字段。这些字段通常由分类阶段设置,包括:端口、子端口、流量类和流量类内的队列。
- 访问队列结构以确定队列数组中的写入位置。如果队列已满,则丢弃数据包。
- 访问队列数组位置以存储数据包(即写入mbuf指针)。
应当注意到这些步骤之间的强数据依赖关系,因为步骤2和3在步骤1和2的结果可用之前无法开始,这阻止了处理器乱序执行引擎提供任何重要的性能优化。
由于输入数据包的高速率和大量队列,预计用于入队当前数据包的数据结构不在当前核心的L1或L2数据缓存中,因此以上3个内存访问(平均)将导致L1和L2数据缓存未命中。出于性能原因,每个数据包的3个L1/L2缓存未命中是不可接受的。
解决方法是提前预取所需的数据结构。预取操作具有执行延迟期间,在此期间,处理器不应尝试访问当前处于预取状态的数据结构,因此处理器应执行其他工作。唯一可用的其他工作是在其他输入数据包上执行入队操作的不同阶段,从而实现入队操作的流水线化实现。
图21.5展示了入队操作的流水线化实现,具有4个流水线阶段,每个阶段执行2个不同的输入数据包。在给定时间内,没有任何输入数据包可以成为多个流水线阶段的一部分。

图 21.5:分层调度程序入队操作的预取管道
队列拥塞管理方案与出队状态机
上述入队管道实现的拥塞管理方案非常基本:数据包被入队直到特定队列变满,然后同一队列的所有数据包被丢弃,直到数据包被消耗(由出队操作完成)。这可以通过在入队管道中启用RED/WRED来改进,该方案会考虑队列占用情况和数据包优先级,从而决定特定数据包的入队/丢弃(而不是不加选择地入队所有数据包或丢弃所有数据包)。
出队状态机
从当前管道调度下一个数据包的步骤顺序如下:
- 使用位图扫描操作标识下一个活动管道,预取管道。
- 读取管道数据结构。更新当前管道及其子端口的信用额度。确定当前管道内的第一个活动流量类别,使用WRR选择下一个队列,预取当前管道的所有16个队列的队列指针。
- 从当前WRR队列中读取下一个元素,并预取其数据包描述符。
- 从数据包描述符(mbuf结构)中读取数据包长度。根据数据包长度和可用信用额度(当前管道、管道流量类、子端口和子端口流量类的信用额度),为当前数据包做出调度是/否的决定。
为避免缓存未命中,上述数据结构(管道、队列、队列数组、mbufs)在被访问之前会提前预取。隐藏预取操作的延迟策略是在为当前管道发出预取操作后立即切换到另一个管道(在磨坊B中的管道),这样可以给预取操作足够的时间完成,然后在执行再次切换回这个管道(在磨坊A中)之前。
出队管道状态机利用了处理器缓存中的数据存在性,因此它试图在移动到同一管道TC和管道中尽可能多地发送数据包(达到可用数据包和信用额度上限)之前,尽可能发送尽可能多的数据包,然后再移动到同一管道中的下一个活动TC(如果有)或移动到另一个活动管道。
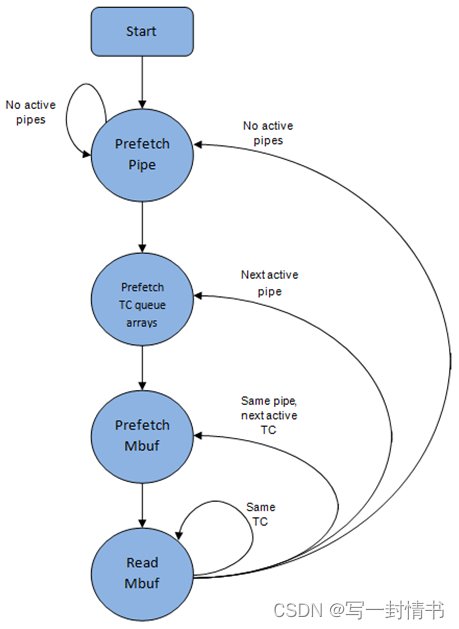
图 21.6:分层调度程序出队操作的管道预取状态机
时序与同步
输出端口被建模为需要由调度器填充数据进行传输的字节槽的传送带。对于10GbE,每秒需要端口调度器填充12.5亿个字节槽。如果调度器填充速度不够快以填满这些槽(假设有足够的数据包和信用额度),则会有一些槽未被使用,造成带宽浪费。
原则上,分层调度器的出队操作应该由NIC TX触发。通常情况下,一旦NIC TX输入队列的占用率降至预定义的阈值以下,端口调度器就会被唤醒(基于中断或轮询,通过持续监控队列占用率)以向队列推送更多数据包。
内部时间参考
调度器需要跟踪时间的推进以进行信用逻辑的更新,这需要基于时间进行信用更新(例如,子端口和管道的流量整形、流量类上限强制等)。
每当调度器决定将数据包发送到NIC TX进行传输时,调度器将相应地增加其内部时间参考。因此,方便将内部时间参考单位设定为字节,其中一个字节表示物理接口在传输介质上发送一个字节所需的时间。这样,当调度数据包进行传输时,时间将以(n + h)增加,其中n是字节长度,h是每个数据包的帧开销字节数。
内部时间参考重新同步
调度器需要将其内部时间参考与端口传送带的速度同步。原因在于确保调度器不会向NIC TX提供比物理介质的线速率更多的字节,以防止数据包丢失(由调度器造成,因为NIC TX输入队列已满,或稍后由NIC TX内部造成)。
调度器在每次出队调用时读取当前时间。CPU时间戳可以通过读取时间戳计数器(TSC)寄存器或高精度事件计时器(HPET)寄存器来获取。当前CPU时间戳从CPU时钟数转换为字节数:time_bytes = time_cycles / cycles_per_byte,其中cycles_per_byte是等效于在传输介质上发送一个字节所需的CPU周期数(例如对于2GHz的CPU频率和10GbE端口,cycles_per_byte = 1.6)。
调度器保持NIC时间的内部时间参考。每当调度数据包时,NIC时间都会随数据包长度(包括帧开销)增加。在每次出队调用时,调度器将其NIC时间的内部参考与当前时间进行比较:
- 如果NIC时间在未来(NIC时间 >= 当前时间),则不需要调整NIC时间。这意味着调度器能够在NIC实际需要这些数据包之前进行调度,因此NIC TX已得到充分提供。
- 如果NIC时间在过去(NIC时间 < 当前时间),则应通过将其设置为当前时间来调整NIC时间。这意味着调度器无法跟上NIC字节传送带的速度,因此由于无法向NIC TX提供足够的数据包,NIC带宽被浪费。
调度器准确性和粒度
调度器往返延迟(SRTD)是调度器对同一管道连续检查之间的时间(CPU周期数)。
为了跟上输出端口(即避免带宽损失),调度器应能够比NIC TX传输同样数量的数据包更快。
调度器需要跟上每个单独管道的速率,按照管道令牌桶的配置,假设没有端口超额订阅。这意味着管道令牌桶的大小应设置得足够高,以防止由于大的SRTD导致溢出,因为这将导致管道的信用损失(因此会损失管道的带宽)。
信用逻辑
调度决策
发送来自(子端口S,管道P,流量类TC,队列Q)的下一个数据包的调度决策是有利的(发送数据包)当满足以下所有条件时:
• 子端口S的管道P目前被一个端口磨坊所选中;
• 流量类TC是管道P的最高优先级的活动流量类别;
• 队列Q是管道P内流量类TC中由WRR选择的下一个队列;
• 子端口S有足够的信用来发送数据包;
• 子端口S的流量类TC有足够的信用来发送数据包;
• 管道P有足够的信用来发送数据包;
• 管道P的流量类TC有足够的信用来发送数据包。
如果所有上述条件都满足,则选择该数据包进行传输,并从子端口S、子端口S的流量类TC、管道P、管道P的流量类TC中减去所需的信用。
帧开销
由于所有数据包长度的最大公约数为一个字节,所选信用单位为一个字节。传输n字节的数据包所需的信用数等于(n+h),其中h等于每个数据包的帧开销字节数。
表 21.5:以太网帧开销字段
通信流量整形
子端口和管道的通信流量整形是使用每个子端口/每个管道一个令牌桶来实现的。每个令牌桶使用一个饱和计数器来记录可用信用的数量。
令牌桶的通用参数和操作如下表所示(表6和表7):
表 21.6:令牌桶通用操作
表 21.7:令牌桶通用参数
实现令牌桶通用操作
为了实现上述描述的令牌桶通用操作,当前设计使用了所提供的持久化数据结构,在表9中描述了令牌桶操作的实现。
表 21.8:令牌桶持久数据结构
令牌桶速率计算公式
令牌桶速率(以每秒字节数计)可以使用以下公式计算:
bucket_rate = (tb_credits_per_period / tb_period) * r
其中,
- ( r ) = 端口线速率(以每秒字节数计)。
- (\text{tb_credits_per_period}) = 令牌桶每周期产生的信用数量。
- (\text{tb_period}) = 令牌桶周期(以秒为单位)。
表 21.9:令牌桶操作
• 每次为端口发送数据包时,更新该端口的所有子端口和管道的信用。不可行。
• 每次发送数据包时,更新管道和子端口的信用。非常准确,但不需要(需要大量计算)。
• 每次选择管道(即由研磨器之一选择)时,更新管道及其子端口的信用。当前实现使用选项3。根据出队状态机章节,在实际使用管道和子端口信用之前,每次由出队过程选择管道时都会更新管道和子端口信用。
实现在准确性和速度之间进行权衡,仅在至少经过一个完整的 tb_period 自上次更新以来才更新桶信用。
• 通过选择 tb_credits_per_period = 1 的 tb_period 值可以实现完全的准确性。
• 当不需要完全的准确性时,通过将 tb_credits 设置为较大的值可以实现更好的性能。
更新操作:
• n_periods =(时间 - tb_time)/ tb_period;
• tb_credits += n_periods * tb_credits_per_period;
• tb_credits = min(tb_credits,tb_size);
• tb_time += n_periods * tb_period;
严格优先级调度和上限强制
严格优先级调度实现
同一管道内的流量类别的严格优先级调度由管道出队状态机实现,它按升序选择队列。因此,处理队列0到3(与最高优先级TC 0相关联的队列)先于处理队列4到7(TC 1,优先级低于TC 0),而这些队列又先于处理队列8到11(TC 2),依此类推先于处理队列12到15(TC 3,优先级最低的TC)。
上限强制
管道和子端口级别的流量类别没有进行流量整形,因此在这个情境下没有维护令牌桶。子端口和管道级别的流量类别的上限由定期重新填充子端口/管道流量类别信用计数器来执行。每当为该子端口/管道调度数据包时,就会消耗其中的信用,如表10和表11所描述。
表21.10:子端口/管道流量类别上限强制持久化数据结构
表 21.11:子端口/管道流量类别上限强制执行操作
tc_time = tc_period;2Credit update更新操作:
如果(时间 >= tc_time){
tc_credits = tc_credits_per_period;
tc_time = time + tc_period;
}3Credit consumption (on packet scheduling)作为数据包调度的结果,TC 限制随着所需的信用数量减少。只有在当前 TC 限制中有足够的信用来发送完整数据包(数据包字节和数据包的帧开销)时,才能发送该数据包。调度操作:
pkt_credits = pk_len + frame_overhead;
如果(tc_credits >= pkt_credits){tc_credits -= pkt_credits;}
加权循环法 (WRR)
WRR 设计解决方案从简单到复杂的演变如表 12 所示。
表 21.12:加权循环法 (WRR)
子端口流量类别超额订阅
问题陈述
对于子端口流量类别X,超额订阅是在配置时发生的事件。这种情况发生在子端口成员管道级别为流量类别X分配的带宽比父子端口级别为相同流量类别分配的带宽更多时。
对于特定子端口和流量类别的超额订阅的存在,纯粹是由于管道和子端口级别的配置而不是由于运行时流量负载的动态演变(就像拥塞一样)。
当流量类别X的整体需求较低时
对于当前子端口的流量类别X的整体需求较低时,超额订阅条件的存在并不代表问题,因为对于所有成员管道,流量类别X的需求得到了完全满足。然而,当所有子端口成员管道的流量类别X的总需求超过了在子端口级别配置的限制时,这就无法再实现了。
解决方案空间
解决这个问题的一些可能方法被总结如下,其中第三种方法被选定用于实现。
表21.13:子端口流量类别超额订阅
子端口流量类别超额订阅实现概述
典型情况下
通常情况下,子端口流量类别(TC)超额订阅功能仅对最低优先级流量类别(TC 3)启用,该流量类别通常用于尽力而为的流量,并且管理平面可以防止此条件发生于其他(优先级更高的)流量类别。
前提假设
为了简化实现,还假设子端口 TC 3 的上限设置为子端口速率的 100%,管道 TC 3 的上限对于所有子端口成员管道也设置为各自管道速率的 100%。
实现概述
算法计算一个水位线(watermark),它基于子端口成员管道当前需求而周期性更新,其目的是限制每个管道允许发送给 TC 3 的流量量。水位线在每个流量类别上限执行期间的开始时在子端口级别计算,并且相同的值在整个当前执行期间内被所有子端口成员管道使用。下图说明了水位线如何在每个期间开始时从子端口级别传播到所有子端口成员管道。

在当前执行期间的开始(与前一执行期间结束同时),水位线的值根据前一期间开始时分配给 TC 3 的带宽量进行调整,而该量在前一期间结束时未被子端口成员管道使用。
如果存在未使用的子端口 TC 3 带宽,当前期间水位线的值将增加,以鼓励子端口成员管道消耗更多带宽。否则,水位线的值将减少,以强制要求 TC 3 的带宽消耗在子端口成员管道之间平等。
水位线值的增加或减少以小幅度增量进行,因此可能需要多个执行周期才能达到平衡状态。这种状态可能随时发生变化,原因是子端口成员管道对 TC 3 的需求发生变化,例如需求增加时(需要降低水位线)或需求减少时(需要增加水位线)。
需求低时,水位线设置得较高,以防止其阻碍子端口成员管道消耗更多带宽。水位线的最高值是从子端口成员管道配置的最高速率中选择的。
表21.14:水位线从子端口级别传播到每个流量类别上限执行期间的成员管道开始时
管道级别:pipe_period_id = 02Credit update子端口级别:如果(时间 >= subport_tc_time){subport_wm = water_mark_update(); subport_tc_time = time + subport_tc_period; subport_period_id++;} 管道级别:如果(pipe_period_id != subport_period_id){pipe_ov_credits = subport_wm * pipe_weight; pipe_period_id = subport_period_id;}3Credit consumption (on packet scheduling)管道级别:pkt_credits = pk_len + frame_overhead; 如果(pipe_ov_credits >= pkt_credits){pipe_ov_credits -= pkt_credits;}
表 21.15:水印计算
21.2.5 性能最差情景
大量活跃队列但信用不足
调度器需要检查大量队列以选择一个包和信用时,其性能会降低。调度器维护活跃队列的位图,跳过非活跃队列,但为了检测特定管道是否有足够的信用,需要使用管道出队状态机深入探查管道,这会消耗周期,而不管调度结果如何(无包生成或至少生成一个包)。这种情况强调了对调度器性能的速度控制的重要性:如果管道没有足够的信用,其数据包应尽快被丢弃(在到达分层调度器之前),从而将管道队列渲染为非活跃状态,允许出队端跳过该管道而无需花费用于调查管道信用的周期,因为这将导致“信用不足”状态。
单个队列达到100%线速率
端口调度器的性能针对大量队列进行了优化。如果队列数较少,则相同活跃流量水平下,端口调度器的性能预计会比小型消息传递队列的性能差。
21.3 丢弃器
DPDK丢弃器的目的
DPDK丢弃器的目的是在分组调度器到达时丢弃分组,以避免拥塞。丢弃器支持随机早期检测(RED)、加权随机早期检测(WRED)和尾部丢弃算法。图21.7说明了丢弃器如何与调度器集成。目前DPDK不支持拥塞管理,因此丢弃器提供了唯一的拥塞避免方法。
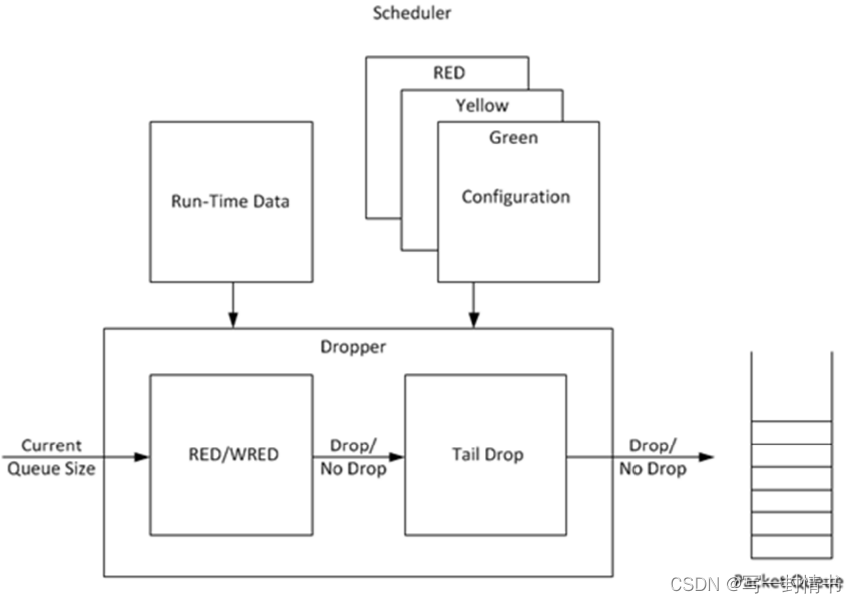
图 21.7:DPDK Dropper 的高级框图
丢弃器使用的拥塞避免算法
丢弃器使用文献中记录的随机早期检测(RED)拥塞避免算法。RED算法的目的是监视数据包队列,确定队列的当前拥塞水平,并决定是否应该将到达的数据包入队或丢弃。RED算法使用指数加权移动平均(EWMA)滤波器来计算平均队列大小,从而指示队列的当前拥塞水平。
对于每个入队操作,RED算法将平均队列大小与最小和最大阈值进行比较。根据平均队列大小是低于、高于还是介于这些阈值之间的情况,RED算法计算到达数据包应该被丢弃的概率,并基于这一概率进行随机决策。
丢弃器还通过允许调度器在运行时为同一个数据包队列选择不同的RED配置来支持加权随机早期检测(WRED)。在严重拥塞情况下,丢弃器会使用尾部丢弃。当数据包队列达到最大容量并且无法存储更多数据包时,就会发生尾部丢弃。在这种情况下,所有到达的数据包都会被丢弃。
丢弃器的数据流程如图21.8所示。首先执行RED/WRED算法,其次执行尾部丢弃。
丢弃器支持的使用案例有:
- 初始化配置数据
- 初始化运行时数据
- 入队(决定是将到达的数据包入队还是丢弃)
- 标记为空(记录数据包队列变为空的时间)
配置用例在"配置"中解释,入队操作在"入队操作"中解释,标记为空操作在"队列为空操作"中解释。
21.3.1 配置
RED配置包含表21.16中给出的参数。
表21.16:RED配置参数
这些参数的含义在后续章节中将会详细解释。这些参数按照其指定给丢弃器模块API的格式,对应于思科*在其RED实现中所使用的格式。最小和最大阈值参数以数据包数量的形式提供给丢弃器模块。标记概率参数以逆值指定,例如,标记概率参数值为10对应于标记概率为1/10(即,10个数据包中将丢弃1个)。EWMA滤波器权重参数以逆对数值指定,例如,滤波器权重参数值为9对应于滤波器权重为1/29。
21.3.2 入队操作
在图21.9中所示的示例中,q(实际队列大小)是输入值,avg(平均队列大小)和count(自上次丢弃以来的数据包数量)是运行时值,decision是输出值,其余数值为配置参数。
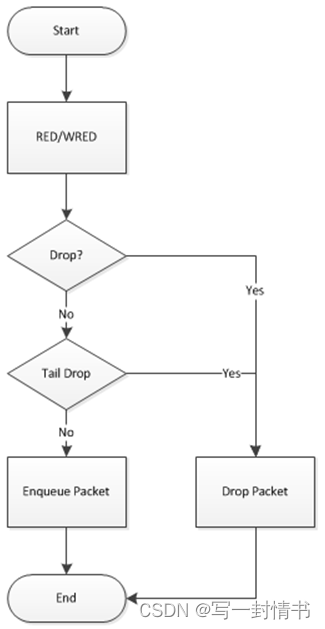
图 21.8:通过滴管的流量
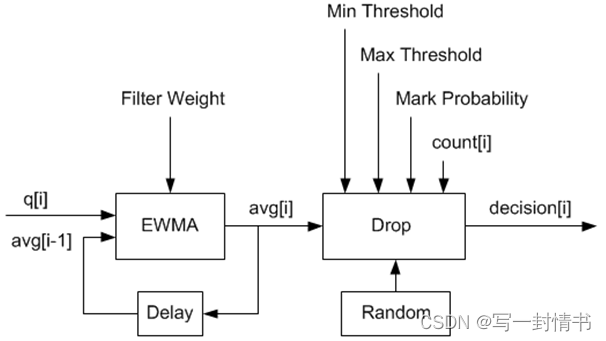
图 21.9:通过 Dropper 的数据流示例
EWMA滤波器微块
EWMA滤波器微块的目的是对队列大小值进行滤波,以平滑“突发”流量所导致的瞬态变化。输出值为平均队列大小,从而更稳定地反映了队列当前的拥塞水平。
EWMA滤波器具有一个配置参数,即滤波器权重,它决定了平均队列大小输出对实际队列大小变化的快慢响应。滤波器权重值越高,平均队列大小对实际队列大小的变化响应就越快。
队列非空时的平均队列大小计算
EWMA滤波器的定义如下方程所示:
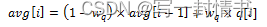
其中:
- avg = 平均队列大小
- wq = 滤波器权重
- q = 实际队列大小
- R = 固定整数,表示除法的位移量
队列为空时的平均队列大小计算
当队列为空时,EWMA滤波器不会读取时间戳,而是假定入队操作会相当定期地发生。当队列变为空时,需要进行特殊处理,因为队列可能短时间或长时间为空。队列变为空时,平均队列大小应该逐渐衰减到零,而不是突然降为零或停留在上次计算的值上。当在空队列上入队一个数据包时,平均队列大小使用以下公式计算:
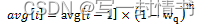
其中:
- m = 在队列为空时可能发生的入队操作数
在dropper模块中,m被定义为:
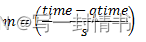
其中:
- time = 当前时间
- qtime = 队列变为空的时间
- s = 在该队列上连续入队操作之间的典型时间
时间参考以字节为单位,其中每个字节表示物理接口在传输介质上发送一个字节所需的时间(参见"内部时间参考"部分)。参数s在dropper模块中被定义为一个常数,其值为:s=2^22。这对应于在具有64K个叶节点的层次结构中,每个叶节点传输一个64字节数据包到传输介质上所需的时间,并代表了最坏情况。对于规模较小的调度器层次结构,可能需要减小参数s,在red头文件源文件(rte_red.h)中定义为:
#define RTE_RED_S
由于时间参考是以字节为单位的,因此端口速度被包含在表达式time-qtime中。dropper无需配置实际端口速度,它会自动适应低速和高速链路。
实现
采用数值方法来计算方程2中出现的(1-wq)^m因子。这个方法基于以下恒等式:
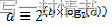
这使我们能够表达如下:
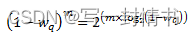
在dropper模块中,使用查找表来为dropper模块支持的每个wq值计算log2(1-wq)。然后,可以通过将表值乘以m并进行位移操作来获得(1-wq)m因子。为了避免乘法中的溢出,值m和查找表值都限制在16位。查找表的总大小为56字节。一旦使用这种方法获得了(1-wq)m因子,就可以从方程2中计算出平均队列大小。
替代方法
考虑了其他计算在队列为空时(方程2)计算平均队列大小所需的因子(1-wq)^m的方法。这些方法包括:
- 浮点数计算
- 使用小查找表(512B)和最多16次乘法的定点数计算(这是FreeBSD* ALTQ RED实现中使用的方法)
- 使用小查找表(512B)和16个SSE乘法的定点数计算(FreeBSD* ALTQ RED实现的SSE优化版本)
- 大查找表(76 KB)
最终选择的方法(在上面的“实现”部分中描述)在运行时性能和内存需求方面优于所有这些方法,并且在精度上也达到了与浮点数计算相当的水平。表17列出了这些替代方法相对于dropper使用的方法的性能。可以看到,浮点数实现性能最差。
表21.17:替代方法的相对性能
注意:
在这种情况下,由于性能是以在特定条件下执行操作所花费的时间来表示的,任何超过100%的相对性能值都比参考方法运行得更慢。
丢弃决策模块
丢弃决策模块:
- 比较平均队列大小与最小和最大阈值
- 计算丢包概率
- 随机决定是否对到达的数据包进行入队或丢弃
丢包概率的计算分为两个阶段。首先根据平均队列大小、最小和最大阈值以及标记概率计算初始丢包概率。然后,从初始丢包概率计算实际丢包概率。实际丢包概率考虑了计数的运行时值,因此随着自上次丢包以来到达队列的数据包越来越多,实际丢包概率也会增加。
初始数据包丢包概率
初始丢包概率使用以下方程计算:
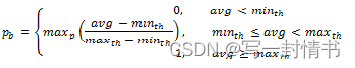
其中:
- maxp = 标记概率
- avg = 平均队列大小
- minth = 最小阈值
- maxth = 最大阈值
方程3中使用平均队列大小计算数据包丢失概率的过程如图21.10所示。如果平均队列大小低于最小阈值,则将到达的数据包入队。如果平均队列大小达到或超过最大阈值,则将到达的数据包丢弃。如果平均队列大小介于最小和最大阈值之间,则计算丢包概率以确定是否应将数据包入队或丢弃。
实际丢包概率
如果平均队列大小介于最小和最大阈值之间,则实际丢包概率由以下方程计算:
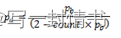
其中:
- Pb = 初始丢包概率(来自方程3)
- count = 自上次丢包以来到达的数据包数量
方程4中的常数2是与参考文档给出的丢包概率公式唯一的偏差,参考文档中使用了值1。需要注意的是,从计算得到的pa可能为负值或大于1。如果是这种情况,则应该使用值1。
图21.11显示了初始和实际丢包概率。实际丢包概率分别使用了参考文档中给出的公式(蓝色曲线)和dropper模块中实现的公式(红色曲线)。与用户指定的标记概率配置参数相比,参考文档中的公式导致了明显更高的丢包率。与参考文档的偏差只是一个设计决策,其他RED实现(例如FreeBSD* ALTQ RED)也做出了类似的选择。

图 21.10:给定 RED 配置的数据包丢弃概率
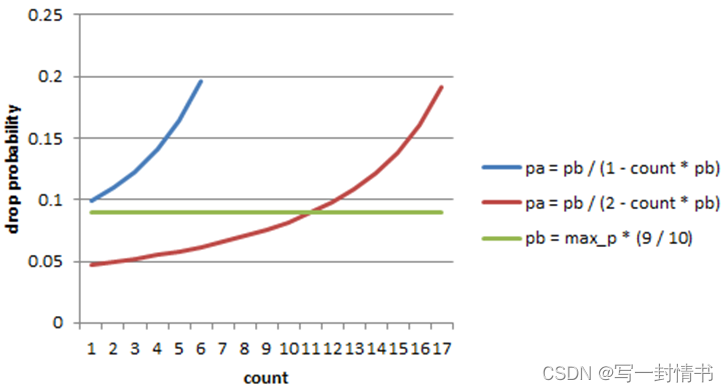
图 21.11:使用 a 计算的初始掉落概率 (pb)、实际掉落概率 (pa)
因子 1(蓝色曲线)和因子 2(红色曲线)
21.3.3 队列为空操作
记录数据包队列变为空的时间,并将其保存到RED运行时数据中,以便EWMA过滤器块在下一次入队操作时计算平均队列大小。通过API通知dropper模块队列已经变为空是调用应用程序的责任。
21.3.4 源文件位置
DPDK dropper的源文件位于:
- DPDK/lib/librte_sched/rte_red.h
- DPDK/lib/librte_sched/rte_red.c
21.3.5 与DPDK QoS调度器的集成
DPDK QoS调度器中的RED功能默认情况下是禁用的。要启用它,请使用DPDK配置参数:
CONFIG_RTE_SCHED_RED=y
必须将此参数设置为y。该参数位于DPDK/config目录中的构建配置文件中,例如,DPDK/config/common_linuxapp。在初始化过程中,RED配置参数在传递给调度器的rte_sched_port_params结构中的rte_red_params结构中进行指定。RED参数分别针对四个流量类别和三种数据包颜色(绿色、黄色和红色)进行指定,允许调度器实现加权随机早期检测(WRED)。
21.3.6 与DPDK QoS调度器示例应用程序的集成
DPDK QoS调度器应用程序在启动时读取一个配置文件。配置文件包括一个包含RED参数的部分。这些参数的格式在“配置”中有描述。下面是一个示例RED配置。在此示例中,队列大小为64个数据包。
注意:为了正确运行,应该在相同流量类别(tc)中的每种数据包颜色(绿色、黄色、红色)中使用相同的EWMA过滤器权重参数(wred weight)。
; RED params per traffic class and color (Green / Yellow / Red)
[red]
tc 0 wred min = 28 22 16
tc 0 wred max = 32 32 32
tc 0 wred inv prob = 10 10 10
tc 0 wred weight = 9 9 9
tc 1 wred min = 28 22 16
tc 1 wred max = 32 32 32
tc 1 wred inv prob = 10 10 10
tc 1 wred weight = 9 9 9
tc 2 wred min = 28 22 16
tc 2 wred max = 32 32 32
tc 2 wred inv prob = 10 10 10
tc 2 wred weight = 9 9 9
tc 3 wred min = 28 22 16
tc 3 wred max = 32 32 32
tc 3 wred inv prob = 10 10 10
tc 3 wred weight = 9 9 9
通过此配置文件,适用于绿色、黄色和红色数据包的 RED 配置
流量类别 0 的情况如表 18 所示。
表 21.18:与 RED 配置相对应的 RED 配置文件
21.3.7 应用程序编程接口(API)
Enqueue API
enqueue API 的语法如下:
int rte_red_enqueue(const struct rte_red_config *red_cfg,
struct rte_red *red,
const unsigned q,
const uint64_t time)
传递给 enqueue API 的参数包括配置数据、运行时数据、数据包队列的当前大小(以数据包为单位)以及表示当前时间的值。时间参考以字节为单位,其中一个字节表示物理接口在传输介质上发送一个字节所需的时间持续。(请参阅内部时间参考部分)。为了性能考虑,丢弃器重用调度器的时间戳。
Empty API
empty API 的语法如下:
void rte_red_mark_queue_empty(struct rte_red *red, const uint64_t time)
传递给 empty API 的参数包括运行时数据和以字节表示的当前时间。
21.4 交通计量
交通计量组件实现了由 IETF RFC 2697 和 2698 定义的单速率三色标记器(srTCM)和双速率三色标记器(trTCM)算法。这些算法根据预先为每个流量流定义的允许量来测量传入数据包流。因此,每个传入的数据包根据其所属流的监测消耗被标记为绿色、黄色或红色。
21.4.1 功能概述
srTCM 算法为每个流量流定义了两个令牌桶,这两个桶共享相同的令牌更新速率:
• 承诺(C)桶:以承诺信息速率(CIR)参数定义的速率提供令牌(以每秒 IP 数据包字节为单位)。C 桶的大小由承诺突发大小(CBS)参数定义(以字节为单位);
• 过剩(E)桶:以与 C 桶相同的速率提供令牌。E 桶的大小由过剩突发大小(EBS)参数定义(以字节为单位)。
trTCM 算法为每个流量流定义了两个令牌桶,这两个桶以独立的速率更新令牌:
• 承诺(C)桶:以承诺信息速率(CIR)参数定义的速率提供令牌(以每秒 IP 数据包字节为单位)。C 桶的大小由承诺突发大小(CBS)参数定义(以字节为单位);
• 峰值(P)桶:以峰值信息速率(PIR)参数定义的速率提供令牌(以每秒 IP 数据包字节为单位)。P 桶的大小由峰值突发大小(PBS)参数定义(以字节为单位)。
请参阅 RFC 2697(用于 srTCM)和 RFC 2698(用于 trTCM)以获取有关如何从桶中消耗令牌以及确定数据包颜色的详细信息。
色盲和色感知模式
对于这两种算法,色盲模式在功能上等同于输入颜色设置为绿色的色感知模式。对于色感知模式,具有红色输入颜色的数据包只能获得红色输出颜色,而具有黄色输入颜色的数据包只能获得黄色或红色输出颜色。
色盲模式仍然与色感知模式有明显区别的原因是,与色感知模式相比,色盲模式可以用更少的操作来实现。
21.4.2 实现概述
对于每个输入数据包,srTCM / trTCM 算法的步骤如下:
• 更新 C 和 E / P 令牌桶。这是通过读取当前时间(从 CPU 时间戳计数器获取),识别自上次桶更新以来的时间量,并根据预先配置的桶速率计算关联的令牌数量来完成的。桶中的令牌数量受到预先配置的桶大小的限制;
• 根据 IP 数据包的大小和 C 和 E / P 令牌桶中当前可用的令牌数量,确定当前数据包的输出颜色;对于仅色感知模式,还考虑数据包的输入颜色。当输出颜色不为红色时,从 C 或 E / P 桶中减去与 IP 数据包长度相等的令牌数量,取决于算法和数据包的输出颜色。
POWER MANAGEMENT
DPDK 的电源管理功能允许用户空间应用程序通过动态调整 CPU 频率或进入不同的 C 状态来节省电力。
• 根据 RX 队列的利用率动态调整 CPU 频率。
• 根据自适应算法进入不同的深度 C 状态,用于猜测短暂的挂起应用程序的时间,如果未收到数据包。
用于调整操作 CPU 频率的接口位于电源管理库中。C 状态控制根据不同的使用情况在应用程序中实现。
22.1 CPU 频率调节
Linux 内核为每个逻辑核心提供了一个 cpufreq 模块用于 CPU 频率调节。例如,对于 cpuX,/sys/devices/system/cpu/cpuX/cpufreq/ 包含以下与频率调节相关的 sys 文件:
• affected_cpus
• bios_limit
• cpuinfo_cur_freq
• cpuinfo_max_freq
• cpuinfo_min_freq
• cpuinfo_transition_latency
• related_cpus
• scaling_available_frequencies
• scaling_available_governors
• scaling_cur_freq
• scaling_driver
• scaling_governor
• scaling_max_freq
• scaling_min_freq
• scaling_setspeed
在 DPDK 中,scaling_governor 在用户空间中配置。然后,用户空间应用程序可以通过写入 scaling_setspeed 来提示内核根据用户空间应用程序定义的策略调整 CPU 频率。
22.2 通过 C 状态对核心负载进行节流
当指定的逻辑核心没有任务时,核心状态可以通过猜测性的睡眠来改变。在 DPDK 中,如果轮询后未收到任何数据包,则可以根据用户空间应用程序定义的策略触发猜测性睡眠。
22.3 电源库的 API 概述
电源库导出的主要方法是用于 CPU 频率调节的,包括以下内容:
• Freq up:提示内核增加特定逻辑核心的频率。
• Freq down:提示内核降低特定逻辑核心的频率。
• Freq max:提示内核将特定逻辑核心的频率调至最大。
• Freq min:提示内核将特定逻辑核心的频率调至最小。
• Get available freqs:从 sys 文件中读取特定逻辑核心的可用频率。
• Freq get:获取特定逻辑核心的当前频率。
• Freq set:提示内核设置特定逻辑核心的频率。
22.4 用户案例
电源管理机制用于在执行 L3 转发时节省功耗。
22.5 参考资料
• l3fwd-power:DPDK 中执行带有电源管理的 L3 转发的示例应用程序。
• DPDK 示例应用程序用户指南中的“带有电源管理的 L3 转发示例应用程序”章节。
PACKET CLASSIFICATION AND ACCESS CONTROL
DPDK 提供了一个访问控制库,它具有基于一组分类规则对输入数据包进行分类的能力。
ACL 库用于在具有多个类别的一组规则上执行 N 元搜索,并为每个类别找到最佳匹配(最高优先级)。库 API 提供了以下基本操作:
• 创建新的访问控制(AC)上下文。
• 将规则添加到上下文中。
• 对上下文中的所有规则,构建执行数据包分类所需的运行时结构。
• 执行输入数据包的分类。
• 销毁 AC 上下文及其运行时结构,并释放相关内存。
23.1 概述
23.1.1 规则定义
当前实现允许用户为每个 AC 上下文指定其自己的规则(字段集),以执行数据包分类。尽管规则字段布局上有一些限制:
• 规则定义中的第一个字段必须是一个字节长。
• 所有后续字段必须分组为连续 4 个字节的集合。
这主要是出于性能考虑 - 搜索函数将第一个输入字节作为流程设置的一部分处理,然后搜索函数的内部循环展开为一次处理四个输入字节。
为定义 AC 规则内的每个字段,使用以下结构:
struct rte_acl_field_def {
uint8_t type; /*< type - ACL_FIELD_TYPE. */
uint8_t size; /*< size of field 1,2,4, or 8. */
uint8_t field_index; /*< index of field inside the rule. */
uint8_t input_index; /*< 0-N input index. */
uint32_t offset; /*< offset to start of field. */
};
• 类型:字段类型有三种选择之一:
– _MASK - 用于具有值和定义相关位数的掩码的字段,例如 IP 地址。
– _RANGE - 用于具有字段的下限和上限值的字段,例如端口。
– _BITMASK - 用于具有值和位掩码的协议标识符字段。
• 大小:大小参数定义字段的字节长度。允许的值为 1、2、4 或 8 字节。注意,由于输入字节的分组,1 或 2 字节字段必须定义为组成 4 个连续输入字节的连续字段。此外,最好将 8 字节或更多字节的字段定义为 4 字节字段,以便构建过程可以消除所有为通配符的字段。
• 字段索引:表示规则内字段位置的从零开始的值;对于 N 个字段,范围为 0 到 N-1。
• 输入索引:如上所述,除了第一个字段外,所有输入字段必须分组为 4 个连续字节。输入索引指定该字段属于哪个输入组。
• 偏移量:偏移字段定义字段的偏移量。这是从搜索的 buffer 参数开始的偏移量。
例如,要定义以下 IPv4 5-tuple 结构的分类:
struct ipv4_5tuple {
uint8_t proto;
uint32_t ip_src;
uint32_t ip_dst;
uint16_t port_src;
uint16_t port_dst;
};
可以使用以下字段定义数组:
#include <rte_acl.h> // 假设相关的头文件// 定义一个包含5个 rte_acl_field_def 结构的数组,用于 ACL 匹配
struct rte_acl_field_def ipv4_defs[5] = {/* 第一个输入字段 - 总是一个字节长。 */{.type = RTE_ACL_FIELD_TYPE_BITMASK,.size = sizeof(uint8_t),.field_index = 0,.input_index = 0,.offset = offsetof(struct ipv4_5tuple, proto),},/* 下一个输入字段(IPv4 源地址)- 连续的4个字节。 */{.type = RTE_ACL_FIELD_TYPE_MASK,.size = sizeof(uint32_t),.field_index = 1,.input_index = 1,.offset = offsetof(struct ipv4_5tuple, ip_src),},/* 下一个输入字段(IPv4 目标地址)- 连续的4个字节。 */{.type = RTE_ACL_FIELD_TYPE_MASK,.size = sizeof(uint32_t),.field_index = 2,.input_index = 2,.offset = offsetof(struct ipv4_5tuple, ip_dst),},/** 接下来的2个字段(源和目标端口)共同占用4个连续字节。* 它们共享相同的输入索引。*/{.type = RTE_ACL_FIELD_TYPE_RANGE,.size = sizeof(uint16_t),.field_index = 3,.input_index = 3,.offset = offsetof(struct ipv4_5tuple, port_src),},{.type = RTE_ACL_FIELD_TYPE_RANGE,.size = sizeof(uint16_t),.field_index = 4,.input_index = 3,.offset = offsetof(struct ipv4_5tuple, port_dst),},
};这种 IPv4 5 元组规则的典型示例如下:
source addr/mask destination addr/mask source ports dest ports protocol/mask
192.168.1.0/24 192.168.2.31/32 0:65535 1234:1234 17/0xff
协议 ID 17 (UDP)、源地址 192.168.1.[0-255]、目标地址的任何 IPv4 数据包
地址192.168.2.31,源端口[0-65535]和目标端口1234与上面匹配规则。
要定义 IPv6 2 元组的分类:<协议,IPv6 源地址> 基于以下内容
IPv6 标头结构:
struct struct ipv6_hdr {
uint32_t vtc_flow; /* IP version, traffic class & flow label. */
uint16_t payload_len; /* IP packet length - includes sizeof(ip_header). */
uint8_t proto; /* Protocol, next header. */
uint8_t hop_limits; /* Hop limits. */
uint8_t src_addr[16]; /* IP address of source host. */
uint8_t dst_addr[16]; /* IP address of destination host(s). */
} __attribute__((__packed__));
可以使用以下字段定义数组:
#include <rte_acl.h> // 可能需要包含相关的头文件// 定义一个包含5个 rte_acl_field_def 结构的数组,用于 IPv6 两元组匹配
struct rte_acl_field_def ipv6_2tuple_defs[5] = {/* 第一个输入字段 - 总是一个字节长,用于IPv6协议类型。 */{.type = RTE_ACL_FIELD_TYPE_BITMASK,.size = sizeof(uint8_t),.field_index = 0,.input_index = 0,.offset = offsetof(struct ipv6_hdr, proto),},/* 下一个输入字段(IPv6源地址的前4个字节)。 */{.type = RTE_ACL_FIELD_TYPE_MASK,.size = sizeof(uint32_t),.field_index = 1,.input_index = 1,.offset = offsetof(struct ipv6_hdr, src_addr[0]),},/* 接下来的输入字段(IPv6源地址的第5至第8字节)。 */{.type = RTE_ACL_FIELD_TYPE_MASK,.size = sizeof(uint32_t),.field_index = 2,.input_index = 2,.offset = offsetof(struct ipv6_hdr, src_addr[4]),},/* 后续的输入字段(IPv6源地址的第9至第12字节)。 */{.type = RTE_ACL_FIELD_TYPE_MASK,.size = sizeof(uint32_t),.field_index = 3,.input_index = 3,.offset = offsetof(struct ipv6_hdr, src_addr[8]),},/* 最后的输入字段(IPv6源地址的第13至第16字节)。 */{.type = RTE_ACL_FIELD_TYPE_MASK,.size = sizeof(uint32_t),.field_index = 4,.input_index = 4,.offset = offsetof(struct ipv6_hdr, src_addr[12]),},
};这种 IPv6 2 元组规则的典型示例如下:
source addr/mask protocol/mask
2001:db8:1234:0000:0000:0000:0000:0000/48 6/0xff
任何 IPv6 数据包的协议 ID 为 6(TCP),且源地址位于范围 [2001:db8🔢0000:0000:0000:0000:0000 - 2001:db8🔢ffff:ffff:ffff:ffff:ffff] 内,都符合上述规则。
在创建一组规则时,对于每个规则,还必须提供额外的信息:
• 优先级:用于衡量规则优先级的权重(值越高越好)。如果输入元组匹配多个规则,则返回优先级较高的规则。请注意,如果输入元组匹配多个具有相同优先级的规则,则未定义将返回哪个规则作为匹配。建议为每个规则分配唯一的优先级。
• 类别掩码:每个规则使用位掩码值来选择规则的相关类别。当执行查找时,将为每个类别返回结果。这有效地通过使单个搜索能够返回多个结果来提供“并行查找”,例如,如果有四个不同的 ACL 规则集,一个用于访问控制,一个用于路由等。每个集合可以分配其自己的类别,并通过将它们合并为单个数据库,使单个查找返回每个集合的结果。
• 用户数据:一个用户定义的字段,可以是除零之外的任何值。对于每个类别,成功匹配将返回具有最高优先级的匹配规则的 userdata 字段。
注意:将新规则添加到 ACL 上下文时,所有字段必须是主机字节顺序(LSB)。当对输入元组执行搜索时,元组中的所有字段必须是网络字节顺序(MSB)。
23.1.2 RT 内存大小限制
构建阶段(rte_acl_build())为给定规则集创建用于进一步运行时遍历的内部结构。使用当前实现,它是一组多位 Trie(stride == 8)。根据规则集,这可能会消耗大量内存。为了节省一些空间,ACL 构建过程尝试将给定的规则集拆分为几个不相交的子集,并为每个子集构建单独的 Trie。根据规则集,这可能会减少 RT 内存需求,但可能会增加分类时间。在构建时,可以为给定 AC 上下文的内部 RT 结构指定最大内存限制。可以通过 rte_acl_config 结构的 max_size 字段来完成。将其设置为大于零的值,指示 rte_acl_build():
• 尝试最小化 RT 表中 Trie 的数量,但
• 确保 RT 表的大小不超过给定值。
将其设置为零会使 rte_acl_build() 使用默认行为:尝试最小化 RT 结构的大小,但不会施加任何硬限制。
这使用户能够自行决定性能/空间折衷的方案。例如:
#include <rte_acl.h> // 可能需要包含相关的头文件struct rte_acl_ctx *acx; // 定义指向 ACL 上下文的指针
struct rte_acl_config cfg; // 定义 ACL 配置结构体
int ret; // 定义用于存储函数返回值的变量/** 假设 acx 指向已创建并填充了规则的 ACL 上下文,* 并且 cfg 被正确填充。*//* 尝试构建 ACL 上下文,RT 结构小于 8MB。*/
cfg.max_size = 0x800000; // 设置最大大小为 8MB
ret = rte_acl_build(acx, &cfg); // 尝试构建 ACL 上下文/** 如果给定上下文的 RT 结构超出了 8MB。* 尝试构建时不暴露任何硬限制。*/
if (ret == -ERANGE) {cfg.max_size = 0; // 设置最大大小为 0,不暴露硬限制ret = rte_acl_build(acx, &cfg); // 再次尝试构建 ACL 上下文
}23.1.3 分类方法
在给定的 AC 上下文上成功完成 rte_acl_build() 后,可以用于执行分类 - 在输入数据上搜索具有最高优先级的规则。有几种分类算法的实现:
• RTE_ACL_CLASSIFY_SCALAR:通用实现,不需要任何特定的硬件支持。
• RTE_ACL_CLASSIFY_SSE:矢量实现,可以并行处理多达 8 个流。需要 SSE 4.1 支持。
• RTE_ACL_CLASSIFY_AVX2:矢量实现,可以并行处理多达 16 个流。需要 AVX2 支持。
纯粹是一个运行时的决策选择哪种方法,没有构建时的差异。所有实现都在相同的内部 RT 结构上操作,并使用类似的原理。主要区别在于矢量实现可以手动利用 IA SIMD 指令,并并行处理多个输入数据流。在启动时,ACL 库确定给定平台的最高可用分类方法,并将其设置为默认方法。尽管用户可以覆盖给定 ACL 上下文的默认分类器函数或使用非默认的分类方法执行特定搜索。在这种情况下,用户有责任确保给定平台支持所选的分类实现。
23.2 应用程序编程接口(API)使用
注意:有关访问控制 API 的更多详细信息,请参阅 DPDK API 参考。
以下示例更详细地演示了上述定义的带有多个类别的 IPv4 5-tuple 分类规则的示例。
23.2.1 多类别分类
#include <rte_acl.h> // 可能需要包含相关的头文件struct rte_acl_ctx *acx; // 定义指向 ACL 上下文的指针
struct rte_acl_config cfg; // 定义 ACL 配置结构体
int ret; // 用于存储函数返回值的变量/* 定义一个包含多达5个字段的规则结构。*/
RTE_ACL_RULE_DEF(acl_ipv4_rule, RTE_DIM(ipv4_defs));/* AC 上下文创建参数。*/
struct rte_acl_param prm = {.name = "ACL_example", // ACL 上下文的名称.socket_id = SOCKET_ID_ANY, // 指定的套接字 ID.rule_size = RTE_ACL_RULE_SZ(RTE_DIM(ipv4_defs)), // 每个规则的大小.max_rule_num = 8, // AC 上下文中规则的最大数量
};/* 定义 ACL 规则数组。*/
struct acl_ipv4_rule acl_rules[] = {/* 匹配前往 192.168.0.0/16 的所有数据包,适用于类别:0,1 */{.data = {.userdata = 1, .category_mask = 3, .priority = 1},/* 目标 IPv4 */.field[2] = {.value.u32 = IPv4(192,168,0,0), .mask_range.u32 = 16,},/* 源端口 */.field[3] = {.value.u16 = 0, .mask_range.u16 = 0xffff,},/* 目标端口 */.field[4] = {.value.u16 = 0, .mask_range.u16 = 0xffff,},},// 其他规则...// 依次添加更多规则...
};/* 创建一个空的 AC 上下文 */
if ((acx = rte_acl_create(&prm)) == NULL) {/* 处理上下文创建失败的情况。*/
}/* 向上下文中添加规则 */
ret = rte_acl_add_rules(acx, acl_rules, RTE_DIM(acl_rules));
if (ret != 0) {/* 处理添加 ACL 规则时的错误。*/
}/* 准备 AC 构建配置。*/
cfg.num_categories = 2; // 规定的类别数量
cfg.num_fields = RTE_DIM(ipv4_defs); // 规则中字段的数量
memcpy(cfg.defs, ipv4_defs, sizeof(ipv4_defs)); // 复制字段定义/* 构建已添加规则的运行时结构,使用2个类别。 */
ret = rte_acl_build(acx, &cfg);
if (ret != 0) {/* 处理为 ACL 上下文构建运行时结构时的错误。*/
}对于源 IP 地址:10.1.1.1 和目标 IP 地址:192.168.1.15 的元组,一次
执行以下几行:
uint32_t results[4]; /* make classify for 4 categories. */
rte_acl_classify(acx, data, results, 1, 4);
那么 results[] 数组包含:
results[4] = {2, 3, 0, 0};
• 对于类别 0,规则 1 和规则 2 都匹配,但规则 2 优先级更高,因此 results[0] 包含规则 2 的 userdata。
• 对于类别 1,规则 1 和规则 3 都匹配,但规则 3 优先级更高,因此 results[1] 包含规则 3 的 userdata。
• 对于类别 2 和 3,没有匹配,因此 results[2] 和 results[3] 包含零,表示这些类别没有匹配项。
对于源 IP 地址为 192.168.1.1 和目标 IP 地址为 192.168.2.11 的元组,
一旦执行以下行:
uint32_t results[4]; /* make classify by 4 categories. */
rte_acl_classify(acx, data, results, 1, 4);
the results[] array contains:
results[4] = {1, 1, 0, 0};
• 对于类别 0 和 1,只有规则 1 匹配。
• 对于类别 2 和 3,没有匹配项。
对于源 IP 地址为 10.1.1.1 和目标 IP 地址为 201.212.111.12 的元组,
一旦执行以下行:
uint32_t results[4]; /* make classify by 4 categories. */
rte_acl_classify(acx, data, results, 1, 4);
the results[] array contains:
results[4] = {0, 3, 0, 0};
• 对于类别 1,只有规则 3 匹配。
• 对于类别 0、2 和 3,没有匹配项。
24.1 设计目标
DPDK 数据包框架的主要设计目标包括:
• 提供标准方法来构建复杂的数据包处理流水线。为常用的流水线功能模块提供可重用和可扩展的模板;
• 允许在同一个流水线功能模块中切换纯软件和硬件加速的实现方式;
• 在灵活性和性能之间寻求最佳平衡。硬编码的流水线通常提供最佳性能,但不灵活,而开发灵活的框架通常不成问题,但性能通常较低;
• 提供一个在逻辑上类似于 Open Flow 的框架。
24.2 概述
数据包处理应用通常被构建为多个阶段的流水线,每个阶段的逻辑都围绕着查找表进行。对于每个传入的数据包,该表定义了要应用于数据包的一组操作,以及发送数据包到下一个阶段的逻辑。
DPDK 数据包框架通过定义流水线开发的标准方法以及提供可重用模板库,最大限度地减少了构建数据包处理流水线所需的开发工作量。
流水线通过将一组输入端口与一组输出端口通过一组表连接在树状拓扑中构建。作为当前数据包在当前表中查找操作的结果,表的一个条目(查找命中时)或默认表条目(查找未命中时)提供了应用于当前数据包的一组操作,以及数据包的下一跳,可以是另一个表、一个输出端口或数据包丢弃。
数据包处理流水线的示例如图 24.1 所示:
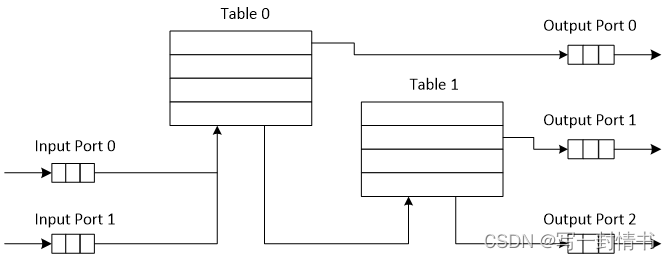 图 24.1:连接输入端口 0 和 1 的数据包处理管道示例
图 24.1:连接输入端口 0 和 1 的数据包处理管道示例
具有输出端口 0、1 和 2 至表 0 和 1
24.3 端口库设计
24.3.1 端口类型
表 19 是可以使用数据包框架实现的端口的非详尽列表。
表 24.1:端口类型
24.3.2 端口接口
每个端口是单向的,即输入端口或输出端口。每个输入/输出端口都需要实现一个抽象接口,该接口定义了端口的初始化和运行时操作。端口的抽象接口描述如下。
表 24.2: 20 端口抽象接口
24.4 表格库设计
24.4.1 表格类型
表 21 是一个非详尽列举的可使用 Packet Framework 实现的表格类型列表。
表 24.3: 表格类型
24.4.2 表格接口
每个表格都需要实现一个抽象接口,该接口定义了表格的初始化和运行时操作。表格的抽象接口描述在表 29 中。
表 24.4: 表格抽象接口
24.4.3 哈希表设计
哈希表概述
哈希表很重要,因为键查找操作被优化为速度:不需要通过表中的所有键进行线性搜索查找键,而是仅限于在单个表桶中存储的键。
关联数组
关联数组是一个可以指定为一组(键、值)对的函数,每个键最多出现一次。对于给定的关联数组,可能的操作有:
- 添加(键,值):当键当前未关联任何值时,创建(键,值)关联。当键已与值 value0 关联时,删除(键,value0)关联并创建(键,value)关联;
- 删除键:当键当前未关联任何值时,此操作不起作用。当键已与值关联时,删除(键,值)关联;
- 查找键:当键当前未关联任何值时,此操作返回空值(查找未命中)。当键与值关联时,此操作返回值。不更改(键,值)关联。
用于比较输入键与关联数组中的键的匹配标准是精确匹配,因为键的大小(字节数)和键值(字节数组)必须与比较中的两个键完全匹配。
哈希函数
哈希函数将可变长度(键)的数据确定性地映射到固定大小的数据(哈希值或键签名)。通常,键的大小大于键签名的大小。哈希函数基本上将长键压缩为短签名。多个键可以共享相同的签名(碰撞)。
高质量的哈希函数具有均匀的分布。对于大量的键,将签名值空间划分为固定数量的相等间隔(桶)时,希望键签名均匀分布在这些间隔之间(均匀分布),而不是大多数签名只进入少数间隔,其余间隔基本上未使用(非均匀分布)。
哈希表
哈希表是使用哈希函数进行操作的关联数组。使用哈希函数的原因是通过最小化与输入键进行比较的表键数量来优化查找操作的性能。
哈希表不是将(键,值)对存储在单个列表中,而是维护多个列表(桶)。对于任何给定的键,存在一个单独的桶,其中该键可能存在,并且该桶基于键签名是唯一标识的。一旦计算了键签名并标识了哈希表桶,要么键位于此桶中,要么根本不在哈希表中,因此键搜索可以从当前表中所有键的完整集合缩小为仅位于识别的表桶中的键集合。
只要表键均匀分布在哈希表桶中,哈希表查找操作的性能就会大大提高,这可以通过使用具有均匀分布的哈希函数来实现。将键映射到其桶的规则可以简单地使用键签名(对表桶数量取模)作为表桶ID:
bucket_id = f_hash(key) % n_buckets;
通过选择桶的数量为2的幂,取模运算符可以被位与逻辑运算符取代:
bucket_id = f_hash(key) & (n_buckets - 1);
考虑到 n_bits 为 bucket_mask = n_buckets - 1 中设置的位数,这意味着所有最终位于相同哈希表桶中的键都具有其签名的较低 n_bits 相同。为了减少相同桶中键的数量(碰撞),需要增加哈希表桶的数量。
在数据包处理上下文中,哈希表操作涉及的操作序列在图 24.2 中描述:

图 24.2:数据包处理上下文中哈希表操作的步骤序列
哈希表用例
流分类
描述:对每个输入数据包至少执行一次流分类。此操作将每个传入数据包映射到流数据库中的已知流量流之一,流数据库通常包含数百万个流。
哈希表名称:流分类表
键数:数百万
键格式:唯一标识流量流/连接的数据包字段的 n 元组。例如:DiffServ 的 5 元组(源 IP 地址、目标 IP 地址、L4 协议、L4 协议源端口、L4 协议目标端口)。对于 IPv4 协议和 TCP、UDP 或 SCTP 等 L4 协议,DiffServ 5 元组的大小为 13 字节,而对于 IPv6 则为 37 字节。
键值(键数据):描述当前流量流数据包要应用的处理的操作和操作元数据。与每个流量流相关的数据大小可从 8 字节到千字节不等。
地址解析协议(ARP)
描述:一旦为 IP 数据包确定了路由(因此知道了输出接口和下一跳站点的 IP 地址),则需要下一跳站点的 MAC 地址,以便将该数据包发送到其目的地的旅程的下一段(由其目标 IP 地址标识)。下一跳站点的 MAC 地址成为出站以太网帧的目的地 MAC 地址。
哈希表名称:ARP 表
键数:数千个
键格式:输出接口和下一跳 IP 地址的一对(Typically 5 字节用于 IPv4,17 字节用于 IPv6)。
键值(键数据):下一跳站点的 MAC 地址(6 字节)。
哈希表类型
表 22 列出了所有不同哈希表类型共享的哈希表配置参数。
表 24.5:所有哈希表类型共有的配置参数
桶满问题
在初始化时,每个哈希表桶为确切地分配了 4 个键的空间。随着键被添加到表中,当需要向某个桶中添加新键时,可能发生这样的情况:该桶已经有 4 个键了。可能的选项有:
- 最近最少使用(LRU)哈希表。桶中的现有键之一被删除,并在其位置添加新键。每个桶中的键数量永远不会超过 4。选择要从桶中删除的键的逻辑是 LRU。哈希表查找操作维护相同桶中的键被命中的顺序,因此每次键被命中时,它都成为新的最近使用(MRU)键,即下一个可能被删除的键。当将键添加到桶时,它也成为新的 MRU 键。当需要选择并删除键时,始终选择第一个被命中的键,即当前的 LRU 键。LRU 逻辑要求为每个桶单独维护特定的数据结构。
- 可扩展桶哈希表。桶被扩展,为其增加了 4 个键的空间。这是通过在表初始化时分配额外内存来实现的,用于创建一组空闲键(此池的大小可配置,始终是 4 的倍数)。在添加键操作中,只有在空闲键的限制范围内才能成功地分配一组 4 个键,否则添加键操作将失败。在删除键操作中,当要删除的键是其组内唯一使用的键时,一组 4 个键将释放回空闲键池中。在键查找操作中,如果当前桶处于扩展状态且在第一组 4 个键中找不到匹配项,则搜索将继续超出第一组 4 个键,潜在地直到检查此桶中的所有键。可扩展桶逻辑要求为每个表和每个桶单独维护特定的数据结构。
表 24.6:可扩展桶哈希表特定的配置参数
签名计算
用于键签名计算的可能选项包括:
- 预先计算的键签名。键查找操作在两个 CPU 核心之间进行分割。第一个 CPU 核心(通常是执行数据包 RX 的 CPU 核心)从输入数据包中提取键,计算键签名,并将键和键签名保存在数据包缓冲区中作为数据包元数据。第二个 CPU 核心从数据包元数据中读取键和键签名,并执行键查找操作的桶搜索步骤。
- 查找时计算键签名(“do-sig” 版本)。同一个 CPU 核心从数据包元数据中读取键,用它计算键签名,并执行键查找操作的桶搜索步骤。
表 24.7:预先计算的键签名哈希表特定的配置参数
键大小优化的哈希表
对于特定键大小,键查找操作的数据结构和算法可以进行专门设计以进一步提高性能,因此有以下选项:
- 支持可配置键大小的实现。
- 支持单个键大小的实现。典型的键大小为 8 字节和 16 字节。
适用于可配置键大小哈希表的桶搜索逻辑
桶搜索逻辑的性能是影响键查找操作性能的主要因素之一。数据结构和算法旨在充分利用英特尔 CPU 架构资源,例如:缓存内存空间、缓存内存带宽、外部内存带宽、多个并行工作的执行单元、乱序指令执行、特殊 CPU 指令等。
桶搜索逻辑并行处理多个输入数据包。它构建为几个阶段的流水线(3 或 4 阶段),每个流水线阶段处理来自输入数据包突发的两个不同数据包。在每个流水线迭代中,数据包被推送到下一个流水线阶段:对于 4 阶段流水线,两个刚完成第 3 阶段的数据包退出流水线,正在执行第 3 阶段的两个数据包,正在执行第 2 阶段的两个数据包,正在执行第 1 阶段的两个数据包以及进入流水线以执行第 0 阶段的下两个数据包(从输入数据包突发中读取的下两个数据包)。流水线迭代将继续,直到来自输入数据包突发的所有数据包执行了流水线的最后一个阶段。
桶搜索逻辑在下一个内存访问边界处分为流水线阶段。每个流水线阶段使用的数据结构通常存储在当前 CPU 核心的 L1 或 L2 缓存内存中(高概率),并在下一个算法所需的内存访问之前中断。当前流水线阶段通过预取下一个流水线阶段所需的数据结构来结束,从而为预取完成提供足够的时间。因此,当下一个流水线阶段最终对相同数据包执行时,它将从 L1 或 L2 缓存内存中读取它所需的数据结构,并避免因 L2 或 L3 缓存缺失而产生的重大性能损失。
通过提前预取下一个流水线阶段所需的数据结构(在实际使用之前),并切换到执行不同数据包的另一个流水线阶段,大大减少了 L2 或 L3 缓存缺失的数量,这是性能改进的主要原因之一。这是因为由于指令之间的数据依赖性,由于 CPU 执行单元必须等待从 L3 缓存或外部 DRAM 内存完成读取操作,因此内存读取访问的 L2/L3 缓存缺失成本较高。
通过将处理分成几个在不同数据包上执行的阶段(输入突发的数据包交错使用),可以创建足够的工作量,以使预取指令成功完成(在实际访问预取的数据结构之前),并减少指令之间的数据依赖性。例如,对于 4 阶段流水线,阶段 0 在数据包 0 和 1 上执行,然后在使用相同数据包 0 和 1(即在数据包 0 和 1 上执行阶段 1 之前)之前,使用不同数据包:数据包 2 和 3(执行阶段 1),数据包 4 和 5(执行阶段 2)以及数据包 6 和 7(执行阶段 3)。通过在将数据结构引入 L1 或 L2 缓存内存时执行有用的工作,隐藏了读取内存访问的延迟。通过增加对同一数据结构的两次连续访问之间的间隔,放宽了指令之间的数据依赖性;这允许充分利用超标量和乱序执行的 CPU 架构,因为活动的 CPU 核心执行单元数量被最大化(而不是由于指令之间的数据依赖性约束而处于空闲或停滞状态)。
桶搜索逻辑还实现为不使用任何分支指令。这避免了在每次分支错误预测时刷新 CPU 核心执行流水线所产生的重要成本。
可配置键大小哈希表
图 24.3、表 25 和表 26 详细说明了用于实现可配置键大小哈希表(LRU 或可扩展桶,以及预先计算签名或“do-sig”)的主要数据结构。
Figure 24.3: Data Structures for Configurable Key Size Hash Tables
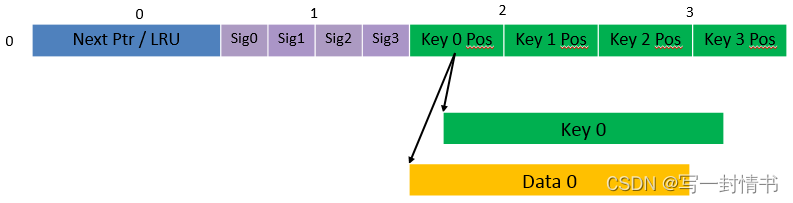
表 24.8:用于可配置键大小哈希表的主要大型数据结构(数组)
表 24.9:桶数组条目的字段描述(可配置键大小哈希表)
图 24.4 和表 27 详细说明了桶搜索流水线阶段(LRU 或可扩展桶,以及预先计算签名或“do-sig”)。对于每个流水线阶段,所描述的操作应用于该阶段处理的两个数据包中的每一个。

Figure 24.4: Bucket Search Pipeline for Key Lookup Operation (Configurable Key Size Hash
Tables)
表 24.10:桶搜索流水线阶段描述(可配置键大小哈希表)
额外注意事项:
- 桶搜索算法的流水线版本仅在输入数据包突发中至少有 7 个数据包时执行。如果输入数据包突发中的数据包少于 7 个,则执行非优化版本的桶搜索算法。
- 一旦针对输入数据包突发中的所有数据包执行了桶搜索算法的流水线版本,还将针对未产生查找命中但设置了 match_many 标志的任何数据包执行桶搜索算法的非优化版本。执行非优化版本的结果可能导致其中一些数据包产生查找命中或查找未命中。这不会影响键查找操作的性能,因为在相同的 4 个键组中匹配超过一个签名或具有扩展状态的桶的概率(仅适用于可扩展桶哈希表)相对较小。
键签名比较逻辑在表 28 中描述。
表 24.11:用于匹配、Match_Many 和 Match_Pos 的查找表
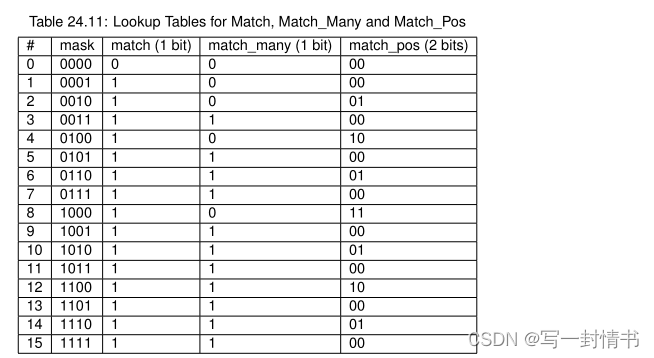
如果输入签名等于存储桶签名 X,则输入掩码哈希位 X (X = 0 … 3) 设置为 1
否则设置为 0。 输出 match、match_many 和 match_pos 分别为 1 位、1 位和 2
位的大小及其含义已在上面解释过。
如表 29 所示,match 和 match_many 的查找表可以折叠为
单个 32 位值和 match_pos 的查找表可以折叠为 64 位值。
给定输入掩码,match、match_many 和 match_pos 的值可以通过以下方式获得
对各自的位数组进行索引,以无分支方式分别提取 1 位、1 位和 2 位
逻辑。
表 24.12:Match、Match_Many 和 Match_Pos 的折叠查找表

match、match_many 和 match_pos 的伪代码是:
match = (0xFFFELLU >> mask) & 1;
match_many = (0xFEE8LLU >> mask) & 1;
match_pos = (0x12131210LLU >> (mask << 1)) & 3;
单键大小哈希表
图 24.5、图 24.6、表 30 和表 31 详细说明了用于实现 8 字节和 16 字节键哈希表(LRU 或可扩展桶,以及预先计算签名或“do-sig”)的主要数据结构。

图 24.5:8 字节密钥哈希表的数据结构

图 24.6:16 字节密钥哈希表的数据结构
表 24.13:用于 8 字节和 16 字节键大小哈希表的主要大型数据结构(数组)
16字节键大小:128 + 4 x entry_size散列表的桶。Bucket extensions arrayn_buckets_ext8字节键大小:64 + 4 x entry_size
16字节键大小:128 + 4 x entry_size仅为可扩展桶表创建的数组。
表 24.14:桶数组条目的字段描述(8 字节和 16 字节键哈希表),
以及用于实现 8 字节和 16 字节键哈希表的桶搜索流水线细节(LRU 或可扩展桶,以及预先计算签名或“do-sig”)。对于每个流水线阶段,所描述的操作应用于该阶段处理的两个数据包中的每一个。

图 24.7:用于键查找操作的存储桶搜索管道(单键大小哈希表)
表 24.15:桶搜索流水线阶段描述(8 字节和 16 字节键哈希表)
额外注意事项:
- 桶搜索算法的流水线版本仅在输入数据包突发中至少有 5 个数据包时执行。如果输入数据包突发中的数据包少于 5 个,则执行非优化版本的桶搜索算法。
- 仅适用于可扩展桶哈希表,在针对输入数据包突发中的所有数据包执行了桶搜索算法的流水线版本后,还将针对未产生查找命中但具有扩展状态桶的任何数据包执行桶搜索算法的非优化版本。执行非优化版本的结果可能导致其中一些数据包产生查找命中或查找未命中。这不会影响键查找操作的性能,因为具有扩展状态桶的概率相对较小。
24.5 流水线库设计
流水线由以下内容定义:
- 输入端口集合;
- 输出端口集合;
- 表集合;
- 动作集合。
通过相互连接的表的树状拓扑,输入端口与输出端口相连。表项包含定义对输入数据包执行的操作以及流水线内的数据包流动的动作。
24.5.1 端口和表的连接性
为了避免对流水线元素创建顺序的任何依赖性,在创建所有流水线输入端口、输出端口和表之后定义流水线元素的连接性。
常规连接性规则:
- 每个输入端口连接到一个表。不应保留任何未连接的输入端口;
- 表连接到其他表或输出端口由每个表条目的下一跳动作和默认表条目规定。表的连接性是流动的,因为表条目和默认表条目可以在运行时更新。
- 表可以具有连接到同一输出端口的多个条目(包括默认条目)。表可以具有连接到不同输出端口的不同条目。不同的表可以具有连接到相同输出端口的条目(包括默认表条目)。
- 表可以具有连接到另一个表的多个条目(包括默认条目),在这种情况下,所有这些条目都必须指向同一个表。此约束由 API 强制执行,并防止创建树状拓扑结构(仅允许表链),旨在简化流水线运行时执行引擎的实现。
24.5.2 端口动作
端口动作处理器
可以为每个输入/输出端口分配一个动作处理器,以定义在接收到端口的每个输入数据包上执行的动作。为特定的输入/输出端口定义动作处理器是可选的(即,可以禁用动作处理器)。
对于输入端口,动作处理器在 RX 功能之后执行。对于输出端口,动作处理器在 TX 功能之前执行。
动作处理器可以决定丢弃数据包。
24.5.3 表动作
表动作处理器
可以为每个表分配一个在每个输入数据包上执行的动作处理器。为特定表定义动作处理器是可选的(即,可以禁用动作处理器)。
动作处理器在执行表查找操作并确定与每个输入数据包关联的表项之后执行。动作处理器只能处理用户定义的动作,而保留动作(例如,下一跳动作)由 Packet Framework 处理。动作处理器可以决定丢弃输入数据包。
保留动作
保留动作由 Packet Framework 直接处理,用户无法通过表动作处理器配置更改其含义。保留动作的一种特殊类别由下一跳动作表示,它调节流水线中输入端口、表和输出端口之间的数据包流动。表 33 列出了下一跳动作。
表 24.16:下一跳动作(保留)
用户动作
对于每个表,用户动作的含义通过表动作处理器的配置来定义。可以使用不同的表动作处理器配置不同的表,因此用户动作及其关联的元数据的含义是私有的。在同一个表中,所有表项(包括表的默认表项)共享用户动作和它们关联的元数据的相同定义,每个表项都有自己的启用用户动作集合和动作元数据副本。表 34 包含了一些用户动作示例。
表 24.17:用户动作示例
24.6 多核扩展
一个复杂的应用程序通常分布在多个核心上,核心之间通过软件队列进行通信。由于硬件约束(如:可用 CPU 周期、缓存内存大小、缓存传输带宽、内存传输带宽等),同一个 CPU 核心上可以容纳的表查找和操作数量通常存在性能限制。
随着应用程序分布在多个 CPU 核心上,Packet Framework 促进了多个流水线的创建,并将每个流水线分配给不同的 CPU 核心,并将所有 CPU 核心级流水线连接到单个应用程序级别的复杂流水线中。例如,如果将 CPU 核心 A 分配给运行流水线 P1,将 CPU 核心 B 分配给流水线 P2,则通过将相同的软件队列集作为流水线 P1 的输出端口和流水线 P2 的输入端口来实现 P1 与 P2 的互连。
这种方法支持使用流水线、完成运行(集群)或混合模型进行应用程序开发。
同一个核心允许运行多个流水线,但不允许多个核心运行相同的流水线。
24.6.1 共享数据结构
执行表查找的线程实际上是表写入器,而不仅仅是读取器。即使特定的表查找算法对于多个读取者是线程安全的(例如,只读访问搜索算法数据结构就足以进行查找操作),但一旦确定了当前数据包的表项,通常预期线程会更新存储在表项中的动作元数据(例如,增加跟踪命中该表项的数据包数量的计数器),从而修改表项。在此线程访问此表项的时间段内(写入或读取;持续时间是应用程序特定的),为了数据一致性原因,不允许其他线程(执行表查找或表项添加/删除操作的线程)修改此表项。
共享相同表项的机制:
- 多个写入线程。线程需要使用同步原语,如信号量(每个表项一个不同的信号量)或原子指令。即使信号量是空闲的,信号量的成本通常也很高。原子指令的成本通常高于常规指令的成本。
- 多个写入线程,单个线程执行表查找操作,多个线程执行表项添加/删除操作。执行表项添加/删除操作的线程向读取者发送表更新请求(通常通过消息传递队列),读取者进行实际的表更新,然后将响应发送回请求发起者。
- 单个写入线程执行表项添加/删除操作,多个读取线程执行表查找操作,只读访问表项。读取线程使用主表副本,而写入者正在更新镜像副本。一旦写入者完成更新,写入者可以向读取者发出信号,并忙等待,直到所有读取者在主副本和镜像副本之间进行交换(镜像副本现在成为主副本,主副本现在成为镜像副本)。
24.7 与加速器的接口
加速器的存在通常在初始化阶段通过检查系统中的硬件设备(例如,通过 PCI 总线枚举)来检测。具有加速功能的典型设备有:
- 内联加速器:网卡、交换机、FPGA 等;
- 独立加速器:芯片组、FPGA 等。
通常,为了支持特定的功能块,必须为每个加速器提供 Packet Framework 表和/或端口和/或动作的特定实现,所有这些实现共享相同的 API:纯软件实现(无加速)、使用加速器 A 的实现、使用加速器 B 的实现等。在系统中选择这些实现可以在构建时或运行时(推荐)进行,基于系统中存在的加速器,而无需进行应用程序更改。
VHOST库
VHOST库实现了用户空间的vhost驱动程序。它支持vhost-cuse(cuse:用户空间字符设备)和vhost-user(用户空间套接字服务器)。它还为客户端中对应的virtio设备创建、管理和销毁vhost设备。vHost支持的vSwitch可以向该库注册回调函数,在客户端虚拟机激活或停用vhost设备时将调用这些回调函数。
25.1 Vhost API概览
- Vhost驱动程序注册
rte_vhost_driver_register将vhost驱动程序注册到系统中。对于vhost-cuse,字符设备文件将被创建在/dev目录下。字符设备名称由参数指定。对于vhost-user,将创建一个Unix域套接字服务器,并使用参数作为本地套接字路径。
- Vhost会话启动
rte_vhost_driver_session_start启动vhost会话循环。Vhost会话是一个无限阻塞的循环。将该会话放入专用的DPDK线程中。
- 回调函数注册
- Vhost支持的vSwitch可以调用
rte_vhost_driver_callback_register来注册两个回调函数new_destory和destroy_device。当客户端虚拟机激活或停用virtio设备时,将调用这些回调函数,然后vSwitch可以通过在设备标志上设置或取消VIRTIO_DEV_RUNNING来将设备放入数据核心或从数据核心移除。
- Vhost支持的vSwitch可以调用
- 从/向客户端虚拟机读写数据包
rte_vhost_enqueue_burst将主机数据包传输到客户端。rte_vhost_dequeue_burst从客户端接收数据包。
- 功能启用/禁用
- 现在vhost中一个可协商的功能是可合并的。vSwitch可以为了性能考虑启用/禁用此功能。
25.2 Vhost实现
25.2.1 Vhost cuse实现
当vSwitch注册vhost驱动程序时,它将在系统中注册一个cuse设备驱动程序并创建一个字符设备文件。该cuse驱动程序将从QEMU模拟器接收vhost的打开/释放/IOCTL消息。
- 当收到打开调用时,vhost驱动程序将为客户端虚拟机中的virtio设备创建一个vhost设备。
- 当收到
VHOST_SET_MEM_TABLE IOCTL时,vhost会搜索内存区域,找到映射客户端虚拟机内存的起始用户空间虚拟地址。通过此虚拟地址和QEMU进程ID,vhost可以找到QEMU用于映射客户端内存的文件。vhost将此文件映射到其地址空间,从而可以完全访问客户端物理内存,这意味着vhost可以访问共享的virtio环和环条目中指定的客户端物理地址。 - 客户端虚拟机通过
VHOST_NET_SET_BACKEND消息告诉vhost virtio设备是否准备好进行处理或已停用。将调用来自vSwitch的注册回调函数。
当释放调用被释放时,vhost将销毁设备。
25.2.2 Vhost user实现
当vSwitch注册vhost驱动程序时,它将在系统中创建一个Unix域套接字服务器。该服务器将侦听连接并处理来自QEMU模拟器的vhost消息。
- 当有新的套接字连接时,意味着客户端虚拟机中已创建了一个新的virtio设备,并且vhost驱动程序将为此virtio设备创建一个vhost设备。
- 对于带有文件描述符的消息,文件描述符可以直接在vhost进程中使用,因为它已经通过Unix域套接字安装。
VHOST_SET_MEM_TABLEVHOST_SET_VRING_KICKVHOST_SET_VRING_CALLVHOST_SET_LOG_FDVHOST_SET_VRING_ERR
对于 VHOST_SET_MEM_TABLE 消息,QEMU将在消息的辅助数据中为每个内存区域和其文件描述符发送信息。文件描述符用于映射该区域。
与vhost cuse不同,没有 VHOST_NET_SET_BACKEND 消息来告知我们virtio设备是否准备好或应该停止。 VHOST_SET_VRING_KICK 用作将vhost设备放入数据平面的信号。 VHOST_GET_VRING_BASE 用作将vhost设备从数据平面中移除的信号。
当套接字连接关闭时,vhost将销毁设备。
25.3 Vhost支持的vSwitch参考
有关更多关于vhost的细节以及如何在vSwitch中支持vhost,请参阅DPDK示例应用程序指南中的vhost示例。
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"五、程序员指南:数据平面开发套件":http://eshow365.cn/6-42179-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!