【JAVA】:万字长篇带你了解JAVA并发编程-并发集合【三】
最佳答案 问答题库598位专家为你答疑解惑
目录
- 【JAVA】:万字长篇带你了解JAVA并发编程-并发集合【三】
- 集合框架
- JUC
- 集合类的历史
- ConcurrentHashMap
- 基本方法
- CopyOnWriteArrayList
- CopyOnWriteArraySet
- ConcurrentSkipListMap
- 跳表
- 跳表的概念
- 跳表的特性有这么几点:
- 跳表的查找
- 跳表的插入
- 使用
- BlockingQueue
- 实现类
- ArrayBlockingQueue
- DelayQueue
- LinkedBlockingQueue
- PriorityBlockingQueue
- SynchronousQueue
- 使用
- ConcurrentLinkedQueue
- 设计思想
- 总结
- 扩展知识:迭代器的 fail-fast 与 fail-safe 机制
- fail-fast 机制
- fail-fast解决方案
- fail-safe机制
- 举例参考:
- 案例一:电商网站中记录一次活动下各个商品售卖的数量
- 案例二:在一次活动下,为每个用户记录浏览商品的历史和次数
- 案例三:在活动中,创建一个用户列表,记录冻结的用户。一旦冻结,不允许再下单抢购,但是可以浏览
个人主页: 【⭐️个人主页】
需要您的【💖 点赞+关注】支持 💯
【JAVA】:万字长篇带你了解JAVA并发编程-并发集合【三】
集合框架
JUC
JUC是java.util.concurrent包的简称,在Java5.0添加,目的就是为了更好的支持高并发任务。让开发者进行多线程编程时减少竞争条件和死锁的问题!
我们在面试过程中也会经常问到这类问题!
集合类的历史
演进过程:Vector和Hashtable
Vector和Hashtable 都是在方法上添加 synchronized 保证线程安全,并发性能差
前身:同步的HashMap和ArrayList
Collections 提供了同步的工具类,如:List list = Collections.synchronizedList(new ArrayList<>())
使用的也是 synchronized,只不过换成加在代码块,而不是加在方法上
现在,ConcurrentHashMap 和 CopyOnWriteArrayList 取代了历史的旧方法
ConcurrentHashMap
适用场景:
包括但不限于以下几种:
- 共享数据的线程安全:在多线程编程中,如果需要进行共享数据的读写,可以使用 ConcurrentHashMap 保证线程安全。
- 缓存:ConcurrentHashMap 的高并发性能和线程安全能力,使其成为一种很好的缓存实现方案。在多线程环境下,使用 ConcurrentHashMap 作为缓存的数据结构,能够提高程序的并发性能,同时保证数据的一致性。
对应的非并发容器:HashMap
目标:代替Hashtable、synchronizedMap,支持复合操作
原理:
JDK6中采用一种更加细粒度的加锁机制Segment“分段锁”,JDK8中采用CAS无锁算法。
对于JDK1.7版本的实现,ConcurrentHashMap 为了提高本身的并发能力,在内部采用了一个叫做 Segment 的结构,一个 Segment 其实就是一个类 Hash Table 的结构,Segment 内部维护了一个链表数组,我们用下面这一幅图来看下 ConcurrentHashMap 的内部结构,从下面的结构我们可以了解到,ConcurrentHashMap 定位一个元素的过程需要进行两次Hash操作,第一次 Hash 定位到 Segment,第二次 Hash 定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是 Hash 的过程要比普通的 HashMap 要长,但是带来的好处是写操作的时候可以只对元素所在的 Segment 进行操作即可,不会影响到其他的 Segment,这样,在最理想的情况下,ConcurrentHashMap 可以最高同时支持 Segment 数量大小的写操作(刚好这些写操作都非常平均地分布在所有的 Segment上),所以,通过这一种结构,ConcurrentHashMap 的并发能力可以大大的提高。我们用下面这一幅图来看下ConcurrentHashMap的内部结构详情图,如下
为什么要用二次hash,主要原因是为了构造分离锁,使得对于map的修改不会锁住整个容器,提高并发能力。当然,没有一种东西是绝对完美的,二次hash带来的问题是整个hash的过程比hashmap单次hash要长,所以,如果不是并发情形,不要使concurrentHashmap。
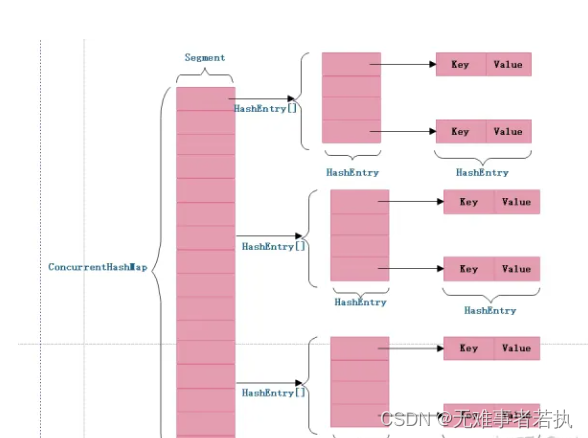
JAVA7之前ConcurrentHashMap主要采用锁机制,在对某个Segment进行操作时,将该Segment锁定,不允许对其进行非查询操作,而在JAVA8之后采用CAS无锁算法,这种乐观操作在完成前进行判断,如果符合预期结果才给予执行,对并发操作提供良好的优化.
基本方法
// 创建一个 ConcurrentHashMap 对象
ConcurrentHashMap<Object, Object> concurrentHashMap = new ConcurrentHashMap<>();
// 添加键值对
concurrentHashMap.put("key", "value");
// 添加一批键值对
concurrentHashMap.putAll(new HashMap());
// 使用指定的键获取值
concurrentHashMap.get("key");
// 判定是否为空
concurrentHashMap.isEmpty();
// 获取已经添加的键值对个数
concurrentHashMap.size();
// 获取已经添加的所有键的集合
concurrentHashMap.keys();
// 获取已经添加的所有值的集合
concurrentHashMap.values();
// 清空
concurrentHashMap.clear();
其他方法:
//如果 key 对应的 value 不存在,则 put 进去,返回 null。否则不 put,返回已存在的 value。
V putIfAbsent(K key, V value)
//如果 key 对应的值是 value,则移除 K-V,返回 true。否则不移除,返回 false。
boolean remove(Object key, Object value)
//如果 key 对应的当前值是 oldValue,则替换为 newValue,返回 true。否则不替换,返回 false。
boolean replace(K key, V oldValue, V newValue)
CopyOnWriteArrayList
适用场景:
读操作可以尽可能地快,而写即使慢一些也没有太大关系
读写规则:
读写锁规则的升级:
读取是完全不用加锁的,并且更厉害的是,写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待
对应的非并发容器:ArrayList
目标:代替Vector、synchronizedList
原理:
利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过
volatile保证其可见性,当然写操作的锁是必不可少的了。
CopyOnWriteArraySet
对应的非并发容器:HashSet
目标:代替synchronizedSet
原理:
基于CopyOnWriteArrayList实现,其唯一的不同是在add时调用的是CopyOnWriteArrayList的addIfAbsent方法,其遍历当前Object数组,如Object数组中已有了当前元素,则直接返回,如果没有则放入Object数组的尾部,并返回。
ConcurrentSkipListMap
适用场景:
需要高并发性能、支持有序性和区间查询的场景,能够有效地提高系统的性能和可扩展性。
对应的非并发容器:TreeMap
目标:代替synchronizedSortedMap(TreeMap)
原理:Skip list(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的。
ConcurrentSkipListMap 是 Java 中的一种线程安全、基于跳表实现的有序映射(Map)数据结构。它是对 TreeMap 的并发实现,支持高并发读写操作。
ConcurrentSkipListMap适用于需要高并发性能、支持有序性和区间查询的场景,能够有效地提高系统的性能和可扩展性。
跳表
跳表的概念
跳表是一种基于有序链表的数据结构,支持快速插入、删除、查找操作,其时间复杂度为O(log n),比普通链表的O(n)更高效。
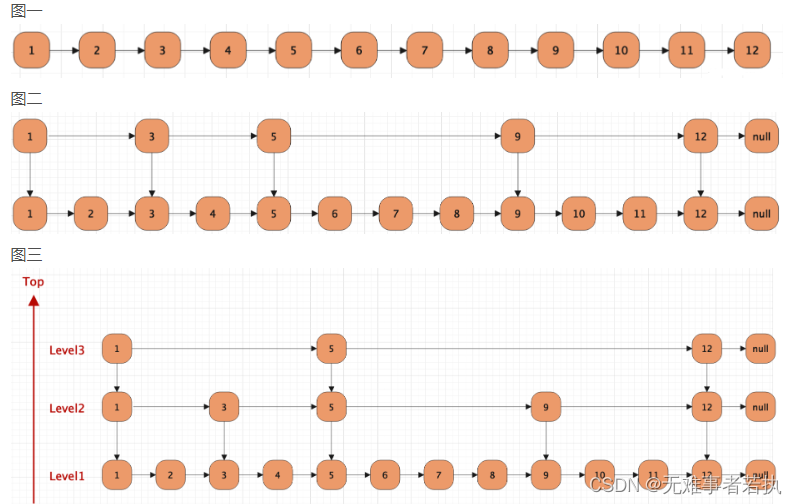
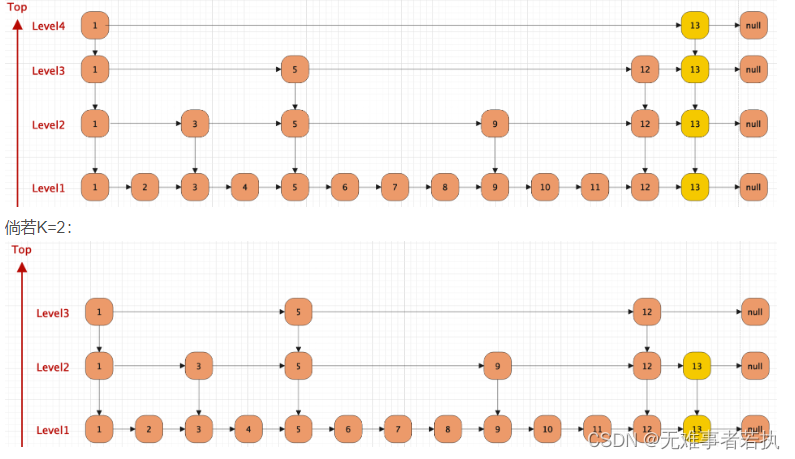
跳表的特性有这么几点:
- 一个跳表结构由很多层数据结构组成。
- 每一层都是一个有序的链表,默认是升序。也可以自定义排序方法。
- 最底层链表(图中所示Level1)包含了所有的元素。
- 如果每一个元素出现在LevelN的链表中(N>1),那么这个元素必定在下层链表出现。
- 每一个节点都包含了两个指针,一个指向同一级链表中的下一个元素,一个指向下一层级别链表中的相同值元素。
跳表的查找
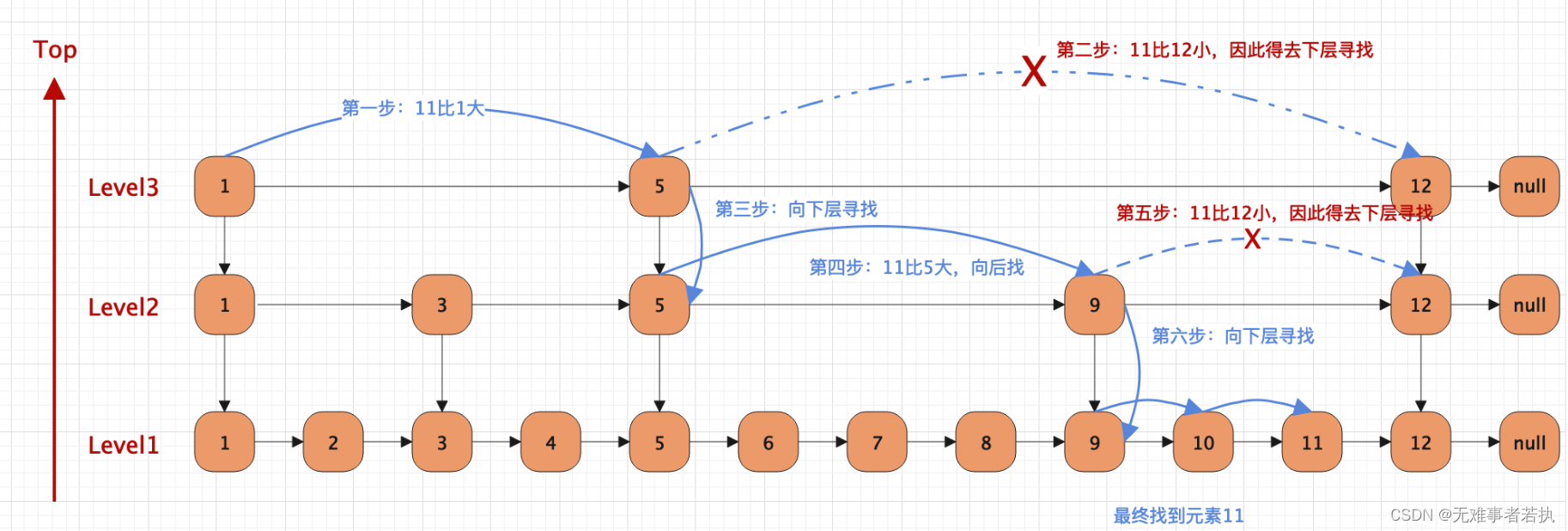
跳表的插入
跳表插入数据的流程如下:
- 找到元素适合的插入层级K,这里K采用随机的方式。若K大于跳表的总层级,那么开辟新的一层,否则在对应的层级插入。
- 申请新的节点。
- 调整对应的指针。
假设我要插入元素13,原有的层级是3级,假设K=4
使用
public class ConcurrentSkipListMapDemo {public static void main(String[] args) {ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();// 添加元素map.put(1, "a");map.put(3, "c");map.put(2, "b");map.put(4, "d");// 获取元素String value1 = map.get(2);System.out.println(value1); // 输出:b// 遍历元素for (Integer key : map.keySet()) {String value = map.get(key);System.out.println(key + " : " + value);}// 删除元素String value2 = map.remove(3);System.out.println(value2); // 输出:c}
}BlockingQueue
阻塞队列 (BlockingQueue)是JUC Java util.concurrent包下重要的数据结构,BlockingQueue提供了线程安全的队列访问方式:当阻塞队列进行插入数据时,如果队列已满,线程将会阻塞等待直到队列非满;从阻塞队列取数据时,如果队列已空,线程将会阻塞等待直到队列非空。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。
并发包下很多高级同步类的实现都是基于BlockingQueue实现的。
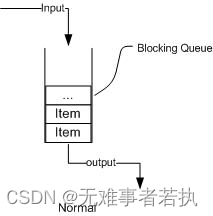
核心方法
offer(E e): //将给定的元素设置到队列中,如果设置成功返回true, 否则返回false. e的值不能为空,否则抛出空指针异常。
offer(E e, long timeout, TimeUnit unit): //将给定元素在给定的时间内设置到队列中,如果设置成功返回true, 否则返回false.
add(E e): //将给定元素设置到队列中,如果设置成功返回true, 否则抛出异常。如果是往限定了长度的队列中设置值,推荐使用offer()方法。put(E e): //将元素设置到队列中,如果队列中没有多余的空间,该方法会一直阻塞,直到队列中有多余的空间。
take(): //从队列中获取值,如果队列中没有值,线程会一直阻塞,直到队列中有值,并且该方法取得了该值。
poll(long timeout, TimeUnit unit): //获取并移除此队列的头元素,可以在指定的等待时间前等待可用的元素,timeout表明放弃之前要等待的时间长度,用 unit 的时间单位表示,如果在元素可用前超过了指定的等待时间,则返回null,当等待时可以被中断
remainingCapacity()://获取队列中剩余的空间。
remove(Object o): //从队列中移除指定的值。
contains(Object o): //判断队列中是否拥有该值。
drainTo(Collection c): //将队列中值,全部移除,并发设置到给定的集合中。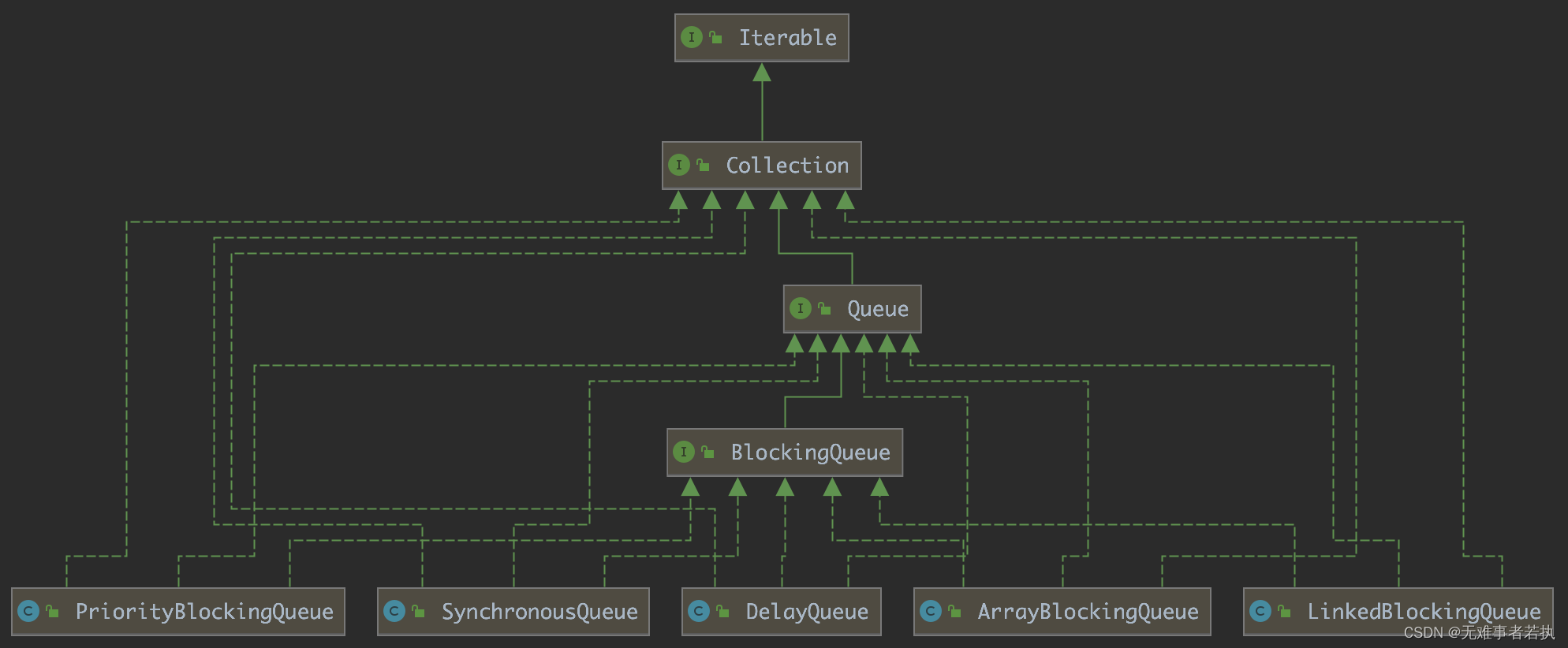
实现类
BlockingQueue 是个接口,你需要使用它的实现之一来使用BlockingQueue,Java.util.concurrent包下具有以下 BlockingQueue 接口的实现类:
ArrayBlockingQueue
ArrayBlockingQueue 是一个有界的阻塞队列,其内部实现是将对象放到一个数组里。有界也就意味着,它不能够存储无限多数量的元素。它有一个同一时间能够存储元素数量的上限。你可以在对其初始化的时候设定这个上限,但之后就无法对这个上限进行修改了(译者注:因为它是基于数组实现的,也就具有数组的特性:一旦初始化,大小就无法修改)。
DelayQueue
DelayQueue 对元素进行持有直到一个特定的延迟到期。注入其中的元素必须实现
java.util.concurrent.Delayed接口。
LinkedBlockingQueue
LinkedBlockingQueue 内部以一个链式结构(链接节点)对其元素进行存储。如果需要的话,这一链式结构可以选择一个上限。如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限。
PriorityBlockingQueue
PriorityBlockingQueue 是一个无界的并发队列。它使用了和类
java.util.PriorityQueue一样的排序规则。你无法向这个队列中插入null值。所有插入到PriorityBlockingQueue的元素必须实现java.lang.Comparable接口。因此该队列中元素的排序就取决于你自己的Comparable实现。
SynchronousQueue
SynchronousQueue 是一个特殊的队列,它的内部同时只能够容纳单个元素。如果该队列已有一元素的话,试图向队列中插入一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走。同样,如果该队列为空,试图向队列中抽取一个元素的线程将会阻塞,直到另一个线程向队列中插入了一条新的元素。据此,把这个类称作一个队列显然是夸大其词了。它更多像是一个汇合点
使用
//生产者public static class Producer implements Runnable{private final BlockingQueue<Integer> blockingQueue;private Random random;public Producer(BlockingQueue<Integer> blockingQueue) {this.blockingQueue = blockingQueue;random=new Random();}public void run() {while(!flag){int info=random.nextInt(100);try {blockingQueue.put(info);Thread.sleep(50);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();} }}//消费者public static class Consumer implements Runnable{private final BlockingQueue<Integer> blockingQueue;public Consumer(BlockingQueue<Integer> blockingQueue) {this.blockingQueue = blockingQueue;}public void run() {while(!flag){int info;try {info = blockingQueue.take();Thread.sleep(50);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();} }}}
ConcurrentLinkedQueue
非阻塞算法实现的队列
在并发编程中我们有时候需要使用线程安全的队列。如果我们要实现一个线程安全的队列有两种实现方式一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现,而非阻塞的实现方式则可以使用循环CAS的方式来实现,下面我们一起来研究下Doug Lea是如何使用非阻塞的方式来实现线程安全队列ConcurrentLinkedQueue的。
设计思想
- 延迟更新首尾节点
在查看实现原理前,我们先来说说ConcurrentLinkedQueue的设计思想,否则实现原理可能会看不懂
ConcurrentLinkedQueue写场景中采用乐观锁的思想,使用CAS+失败重试来保证操作的原子性
为了避免CAS开销过大,ConcurrentLinkedQueue采用延迟更新首尾节点的思想,来减少CAS次数
也就是说ConcurrentLinkedQueue中的首尾节点并不一定是最新的首尾节点
- 哨兵节点
ConcurrentLinkedQueue的设计中使用哨兵节点
什么是哨兵节点?
哨兵节点又称虚拟节点,哨兵节点常使用在链表这种数据结构中
单向链表中如果要添加或者删除某个节点时,一定要获得这个节点的前驱节点再去进行操作
当操作的是第一个节点时,如果在第一个节点前面加个虚拟节点(哨兵节点),那么就不用特殊处理
换而言之使用哨兵节点可以减少代码复杂度,相信刷过链表相关算法的同学深有体会
哨兵节点还能够在只有一个节点时减少并发冲突
总结
-
ConcurrentLinkedQueue基于单向链表实现,使用volatile保证可见性,使得在读场景下不需要使用其他同步机制;使用乐观锁CAS+失败重试保证写场景下操作的原子性 -
ConcurrentLinkedQueue使用
延迟更新首尾节点的思想,大大减少CAS次数,提升并发性能;使用哨兵节点,降低代码复杂度,避免一个节点时的竞争 -
在
入队操作时,会在循环中找到真正的尾节点,使用CAS添加新节点,再判断是否CAS更新尾节点tail -
在
入队操作的循环期间一般情况下是向后遍历节点,由于出队操作会构建哨兵节点,当判断为哨兵节点(next指向自己)时,根据情况定位到尾节点或头节点(“跳出”) -
在
出队操作时,也是在循环中找到真正的头节点,使用CAS将真正头节点的数据设置为空,再判断是否CAS更新头节点,然后让旧的头节点next指向它自己构建成哨兵节点,方便GC -
在
出队操作的循环期间一般情况下也是向后遍历节点,由于出队会构建哨兵节点,当检测到当前是哨兵节点时,也要跳过本次循环 -
ConcurrentLinkedQueue基于
哨兵节点、延迟CAS更新首尾节点、volatile保证可见性等特点,拥有非常高的性能,相对于CopyOnWriteArrayList来说适用于数据量大、并发高、频繁读写、操作队头、队尾的场景
源码原理:请学习:
https://blog.csdn.net/qq_38293564/article/details/80798310
https://zhuanlan.zhihu.com/p/657694373
扩展知识:迭代器的 fail-fast 与 fail-safe 机制
在 Java 中,迭代器(Iterator)在迭代的过程中,如果底层的集合被修改(添加或删除元素),不同的迭代器对此的表现行为是不一样的,可分为两类:Fail-Fast(快速失败)和 Fail-Safe(安全失败)。
fail-fast 机制
fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。
例如:当某一个线程A通过 iterator 去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生 fail-fast 事件。
在java.util包中的集合,如 ArrayList、HashMap 等,它们的迭代器默认都是采用 Fail-Fast 机制。

fail-fast解决方案
- 方案一:在遍历过程中所有涉及到改变modCount 值的地方全部加上synchronized 或者直接使用 Collection#synchronizedList,这样就可以解决问题,但是不推荐,因为增删造成的同步锁可能会阻塞遍历操作。
- 方案二:使用
CopyOnWriteArrayList替换ArrayList,推荐使用该方案(即fail-safe)。
fail-safe机制
任何对集合结构的修改都会在一个复制的集合上进行,因此不会抛出ConcurrentModificationException。在
java.util.concurrent包中的集合,如CopyOnWriteArrayList、ConcurrentHashMap等,它们的迭代器一般都是采用Fail-Safe机制。
缺点:
- 采用 Fail-Safe 机制的集合类都是线程安全的,但是它们无法保证数据的实时一致性,它们只能保证数据的最终一致性。在迭代过程中,如果集合被修改了,可能读取到的仍然是旧的数据。
- Fail-Safe 机制还存在另外一个问题,就是内存占用。由于这类集合一般都是通过复制来实现读写分离的,因此它们会创建出更多的对象,导致占用更多的内存,甚至可能引起频繁的垃圾回收,严重影响性能。
举例参考:
电商场景中并发容器的选择
案例一:电商网站中记录一次活动下各个商品售卖的数量
场景分析:需要频繁按商品id做get和set,但是商品id(key)的数量相对稳定不会频繁增删
初级方案:选用HashMap,key为商品id,value为商品购买的次数。每次下单取出次数,增加后再写入
问题:HashMap线程不安全!在多次商品id写入后,如果发生扩容,在JDK1.7 之前,在并发场景下HashMap 会出现死循环,从而导致CPU 使用率居高不下。JDK1.8 中修复了HashMap 扩容导致的死循环问题,但在高并发场景下,依然会有数据丢失以及不准确的情况出现。
选型:Hashtable 不推荐,锁太重,选ConcurrentHashMap 确保高并发下多线程的安全性
案例二:在一次活动下,为每个用户记录浏览商品的历史和次数
场景分析:每个用户各自浏览的商品量级非常大,并且每次访问都要更新次数,频繁读写
初级方案:为确保线程安全,采用上面的思路,ConcurrentHashMap
问题:ConcurrentHashMap 内部机制在数据量大时,会把链表转换为红黑树。而红黑树在高并发情况下,删除和插入过程中有个平衡的过程,会牵涉到大量节点,因此竞争锁资源的代价相对比较高
选型:用跳表,ConcurrentSkipListMap将key值分层,逐个切段,增删效率高于ConcurrentHashMap
结论:如果对数据有强一致要求,则需使用Hashtable;在大部分场景通常都是弱一致性的情况下,使用ConcurrentHashMap 即可;如果数据量级很高,且存在大量增删改操作,则可以考虑使用ConcurrentSkipListMap。
案例三:在活动中,创建一个用户列表,记录冻结的用户。一旦冻结,不允许再下单抢购,但是可以浏览
场景分析:违规被冻结的用户不会太多,但是绝大多数非冻结用户每次抢单都要去查一下这个列表。低频写,高频读。
初级方案:ArrayList记录要冻结的用户id
问题:ArrayList对冻结用户id的插入和读取操作在高并发时,线程不安全。Vector可以做到线程安全,但并发性能差,锁太重。
选型:综合业务场景,选CopyOnWriteArrayList,会占空间,但是也仅仅发生在添加新冻结用户的时候。绝大多数的访问在非冻结用户的读取和比对上,不会阻塞。
参考学习文章:
https://blog.csdn.net/weixin_43888181/article/details/116546374
⭐️ https://blog.csdn.net/a250029634/article/details/131631986
https://zhuanlan.zhihu.com/p/349801217
https://blog.csdn.net/qq_38293564/article/details/80798310
99%的人还看了
相似问题
- 〖大前端 - 基础入门三大核心之JS篇㊲〗- DOM改变元素节点的css样式、HTML属性
- Java 算法篇-链表的经典算法:判断回文链表、判断环链表与寻找环入口节点(“龟兔赛跑“算法实现)
- 代码随想录二刷 | 链表 | 删除链表的倒数第N个节点
- 节点导纳矩阵
- bhosts 显示节点 “unreach“ 状态
- 电子电器架构 —— 车载网关边缘节点总线转换
- 〖大前端 - 基础入门三大核心之JS篇㊳〗- DOM访问元素节点
- 第四天||24. 两两交换链表中的节点 ● 19.删除链表的倒数第N个节点 ● 面试题 02.07. 链表相交 ● 142.环形链表II
- CS224W5.1——消息传递和节点分类
- Vue报错解决Error in v-on handler: “Error: 无效的节点选择器:#div1“
猜你感兴趣
版权申明
本文"【JAVA】:万字长篇带你了解JAVA并发编程-并发集合【三】":http://eshow365.cn/6-31294-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: Linux 远程桌面软件
- 下一篇: CN考研真题知识点二轮归纳(5)