已解决
Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (二)
来自网友在路上 160860提问 提问时间:2023-10-28 03:40:32阅读次数: 60
最佳答案 问答题库608位专家为你答疑解惑
这是继上一篇文章 “Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (一)” 的续篇。在这篇文章中,我主要来讲述 ElasticVectorSearch 的使用。

我们的设置和之前的那篇文章是一样的,只不过,在这里我们使用 ElasticVectorSearch 而不是 ElasticKnnSearch。
创建应用并展示
安装包
#!pip3 install langchain导入包
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import ElasticKnnSearch
from langchain.text_splitter import CharacterTextSplitter
from urllib.request import urlopen
import os, jsonload_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")
elastic_index_name='elastic-vector-search'将文档分成段落
import json# Load data into a JSON object
with open('workplace-docs.json') as f:workplace_docs = json.load(f)print(f"Successfully loaded {len(workplace_docs)} documents")metadata = []
content = []for doc in workplace_docs:content.append(doc["content"])metadata.append({"name": doc["name"],"summary": doc["summary"],"rolePermissions":doc["rolePermissions"]})text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
docs = text_splitter.create_documents(content, metadatas=metadata)
把数据写入到 Elasticsearch
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"ssl_verify = {"verify_certs": True,"basic_auth": (elastic_user, elastic_password),"ca_certs": "./http_ca.crt"
}es = ElasticVectorSearch.from_documents( docs,embedding = embeddings, elasticsearch_url = url, index_name = elastic_index_name, ssl_verify = ssl_verify)
如上所示,ElasticVectorSearch 在未来的发布中将被移除。
运行完上面的代码后,我们可以到 Kibana 中进行查看:

展示结果
def showResults(output):print("Total results: ", len(output))for index in range(len(output)):print(output[index])Similarity / Vector Search (KNN Search)
query = "work from home policy"
result = es.similarity_search(query=query)showResults(result)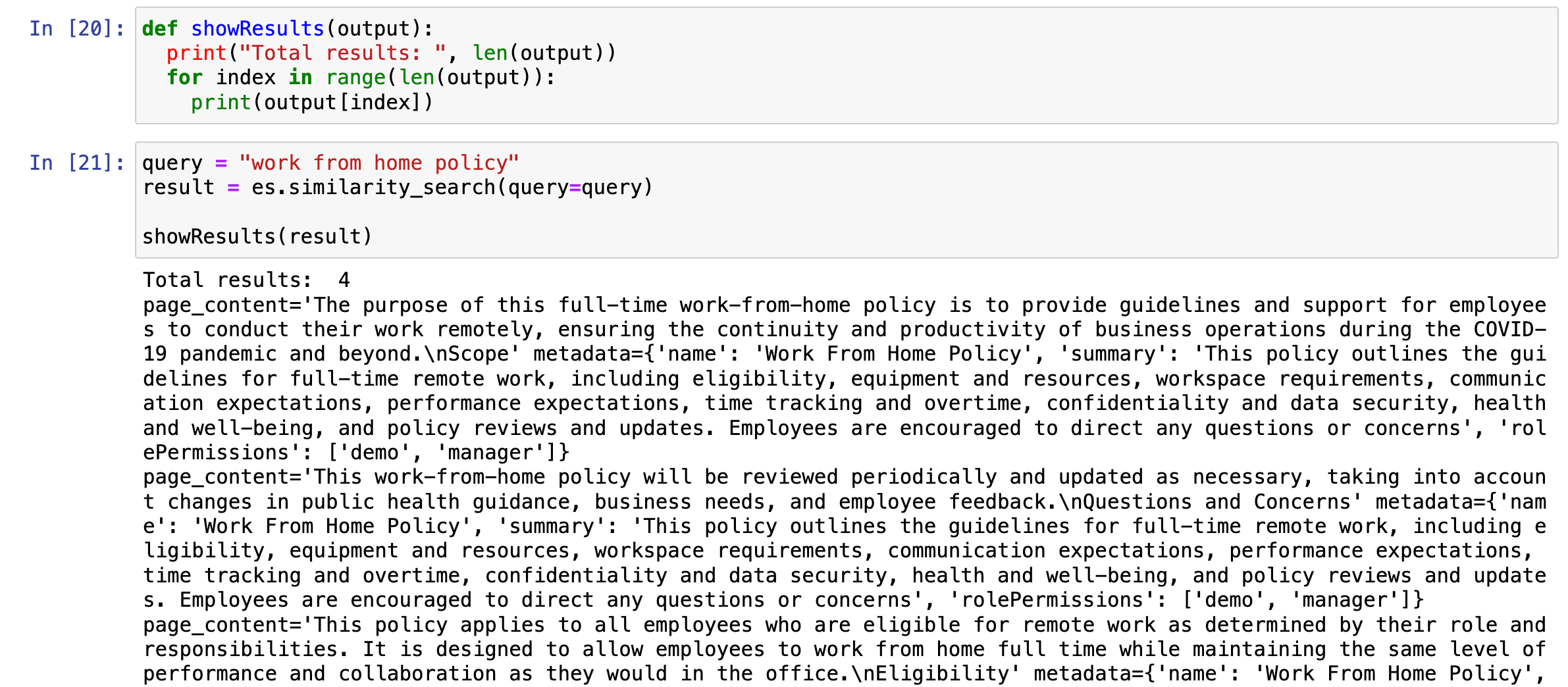
我们上面实现的代码可以在地址 https://github.com/liu-xiao-guo/semantic_search_es/blob/main/ElasticVectorSearch.ipynb 进行下载。
查看全文
99%的人还看了
相似问题
- Hyper-V系列:微软官方文章
- 全网最全jmeter接口测试/接口自动化测试看这篇文章就够了:跨线程组传递jmeter变量及cookie的处理
- 前端新手Vue3+Vite+Ts+Pinia+Sass项目指北系列文章 —— 第五章 Element-Plus组件库安装和使用
- Markdown使用emoji图标【美化你的文章】
- 前端新手Vue3+Vite+Ts+Pinia+Sass项目指北系列文章 —— 第二章 环境部署
- java基础练习缺少项目?看这篇文章就够了(上)!
- 前端新手Vue3+Vite+Ts+Pinia+Sass项目指北系列文章 —— 第一章 技术栈简介
- 批量替换WordPress文章内图片链接
- PMCW体制雷达系列文章(4) – PMCW雷达之抗干扰
- 新增文章分类
猜你感兴趣
版权申明
本文"Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (二)":http://eshow365.cn/6-26525-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 性能测试工具:Jmeter介绍
- 下一篇: 简单8位CPU设计verilog微处理器,源码/视频