【大数据开发技术】实验04-HDFS文件创建与写入
最佳答案 问答题库358位专家为你答疑解惑
文章目录
- 一、实验目标
- 二、实验要求
- 三、实验内容
- 四、实验步骤
一、实验目标
- 熟练掌握hadoop操作指令及HDFS命令行接口
- 掌握HDFS原理
- 熟练掌握HDFS的API使用方法
- 掌握单个本地文件写入到HDFS文件的方法
- 掌握多个本地文件批量写入到HDFS文件的方法
二、实验要求
- 给出主要实验步骤成功的效果截图。
- 要求分别在本地和集群测试,给出测试效果截图。
- 对本次实验工作进行全面的总结。
- 完成实验内容后,实验报告文件名显示学号姓名信息。
三、实验内容
-
使用FileSystem将单个本地文件写入到HDFS中当前不存在的文件,实现效果参考下图:
-
使用FileSystem将本地文件追加到HDFS中当前存在的文件中,实现效果参考下图:
四、实验步骤
- 使用FileSystem将单个本地文件写入到HDFS中当前不存在的文件
程序设计
package hadoop;import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;public class WJW {public static void main(String[] args) {// TODO Auto-generated method stubargs = new String[2];args[0] = "/home/zkpk/experiment/wjw01.txt";args[1] = "hdfs://master:9000/wjw02.txt";Configuration conf = new Configuration();BufferedInputStream in = null;FileSystem fs = null;FSDataOutputStream out = null;try{in = new BufferedInputStream(new FileInputStream(args[0]));fs = FileSystem.get(URI.create(args[1]), conf);out = fs.create(new Path(args[1]));IOUtils.copyBytes(in, out, 4096, false);}catch(FileNotFoundException e){e.printStackTrace();}catch(IOException e){e.printStackTrace();}finally{IOUtils.closeStream(in);IOUtils.closeStream(out);if(fs != null){try{fs.close();}catch(IOException e){e.printStackTrace();}}}}}
程序分析
该代码实现了将本地文件上传到Hadoop分布式文件系统HDFS中的功能。代码结构简单明了,主要包括以下几个步骤:
-
定义参数args,参数args[0]表示本地文件路径,参数args[1]表示HDFS文件路径。
-
创建Configuration对象,用于读取Hadoop配置信息。
-
创建BufferedInputStream流,读取本地文件。
-
使用FileSystem.get()方法获取Hadoop分布式文件系统实例。
-
调用fs.create()方法,创建HDFS文件,并返回FSDataOutputStream对象用于向HDFS文件写入数据。
-
调用IOUtils.copyBytes()方法,将本地文件数据复制到HDFS文件中。
-
关闭流和Hadoop分布式文件系统实例。
该代码主要涉及以下几个重要知识点:
-
Configuration对象:该对象用于读取Hadoop配置信息,如HDFS的地址、端口等信息。
-
FileSystem对象:该对象用于操作Hadoop分布式文件系统,如创建文件、删除文件、读取文件等操作。
-
BufferedInputStream流:该流用于读取本地文件数据。
-
FSDataOutputStream对象:该对象用于向HDFS文件写入数据。
-
IOUtils.copyBytes()方法:该方法用于将输入流中的数据复制到输出流中。
总体来说,该代码实现了将本地文件上传到HDFS的功能,但还有一些需要改进的地方。例如,可以添加参数校验功能,防止空指针异常;可以添加日志输出功能,方便查看程序运行情况。
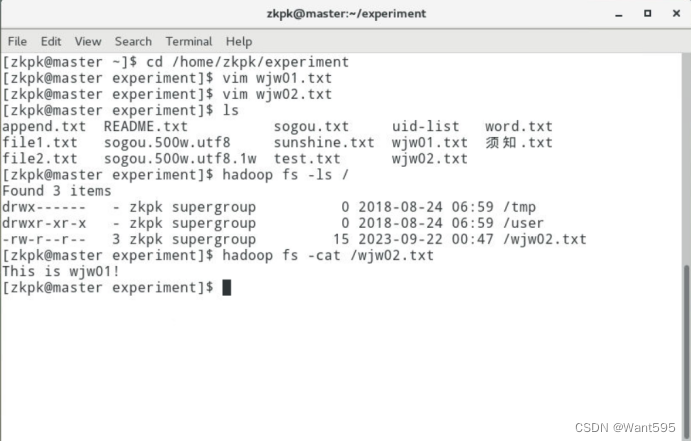
运行结果
- 使用FileSystem将本地文件追加到HDFS中当前存在的文件中
程序设计
package hadoop;import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;public class WJW01 {public static void main(String[] args) {// TODO Auto-generated method stubargs = new String[2];args[0] = "/home/zkpk/experiment/wjw01.txt";args[1] = "hdfs://master:9000/wjw02.txt";Configuration conf = new Configuration();conf.set("fs.client.block.write.replace-datanode-on-failure.enable", "true");conf.set("fs.client.block.write.replace-datanode-on-failure.policy", "Never");BufferedInputStream in = null;FileSystem fs = null;FSDataOutputStream out = null;try{in = new BufferedInputStream(new FileInputStream(args[0]));fs = FileSystem.get(URI.create(args[1]), conf);out = fs.append(new Path(args[1]));IOUtils.copyBytes(in, out, 4096, false);}catch(FileNotFoundException e){e.printStackTrace();}catch(IOException e){e.printStackTrace();}finally{IOUtils.closeStream(in);IOUtils.closeStream(out);if(fs != null){try{fs.close();}catch(IOException e){e.printStackTrace();}}}}}
程序分析
该代码实现了将本地文件追加上传到Hadoop分布式文件系统HDFS中的功能。代码结构与上传文件功能类似,主要包括以下几个步骤:
-
定义参数args,参数args[0]表示本地文件路径,参数args[1]表示HDFS文件路径。
-
创建Configuration对象,用于读取Hadoop配置信息。
-
设置配置信息:设置“fs.client.block.write.replace-datanode-on-failure.enable”为“true”,表示在数据节点故障时启用块写入数据节点更换机制;设置“fs.client.block.write.replace-datanode-on-failure.policy”为“Never”,表示块写入数据节点故障时不替换数据节点。
-
创建BufferedInputStream流,读取本地文件。
-
使用FileSystem.get()方法获取Hadoop分布式文件系统实例。
-
调用fs.append()方法,获取FSDataOutputStream对象用于向HDFS文件追加数据。
-
调用IOUtils.copyBytes()方法,将本地文件数据复制追加到HDFS文件中。
-
关闭流和Hadoop分布式文件系统实例。
需要注意的是,该代码使用了追加上传文件的方式,因此可以将本地文件的数据追加到HDFS文件的末尾,而不会影响原有的HDFS文件数据。同时,设置数据节点更换机制可以提高系统的可靠性和稳定性,避免数据节点故障导致数据丢失的情况。
总体来说,该代码实现了将本地文件追加上传到HDFS的功能,并且考虑了系统的可靠性和稳定性问题。但是,同样需要注意代码中的参数校验和日志输出等问题,以提高代码的健壮性和可维护性。
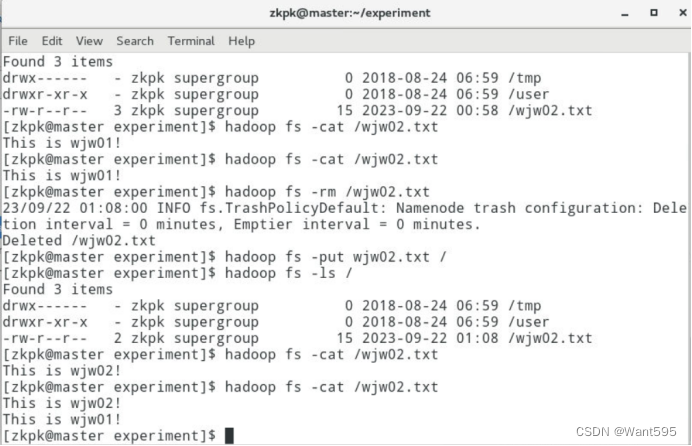
运行结果
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"【大数据开发技术】实验04-HDFS文件创建与写入":http://eshow365.cn/6-14560-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!