已解决
日常学习之:如何基于 OpenAI 构建自己的向量数据库
来自网友在路上 159859提问 提问时间:2023-09-26 17:40:11阅读次数: 59
最佳答案 问答题库598位专家为你答疑解惑
文章目录
- 原理
- 前期准备
- 依赖安装
- Pinecone 数据库注册
- Index 创建(相当于传统数据库中的创建 table)
- 基于 pinecone 数据库的代码实现
- 尝试用 OpenAI 的 API 构建 embedding
- 将示例的数据 embedding 后写入你的 pinecode (构建向量数据库)
- 参考
- 构建查询 query
- 删除 Index (慎用)
- 基于 chroma 数据库的代码实现
- 原理介绍
- 依赖安装
- 代码
原理
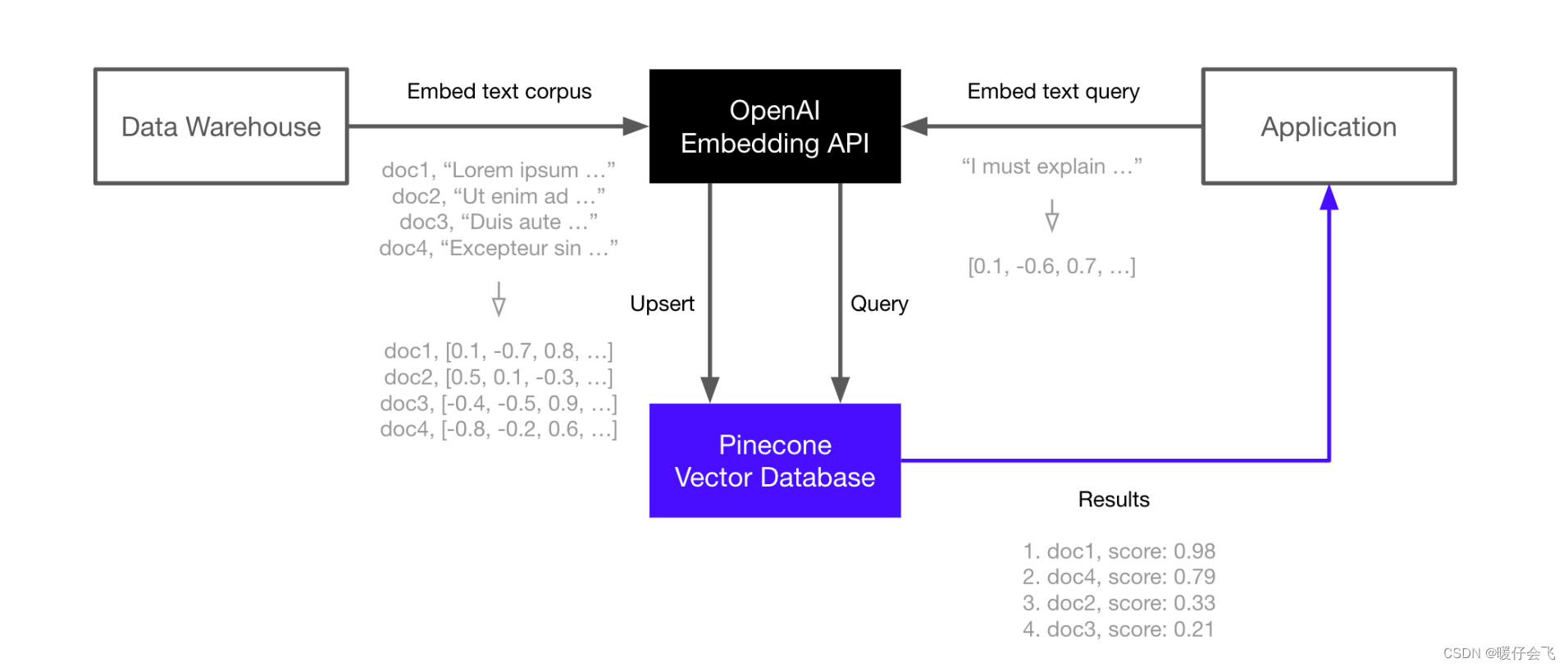
- 将数据集通过 OpenAI 的模型转换成 embedding 的向量
- 将这些向量存储到向量数据库
pinecone - 当构建一个应用的时候,给出一个查询的句子
query,依然通过 OpenAI 的模型进行 embedding 得到查询向量 query向量被拿来与pinecone中的每一个向量进行相似度匹配,最终返回相似度最高的topk
前期准备
依赖安装
# 如果你要基于 pinecone 来构建向量数据库就安装这些库
pip install -qU pinecone-client openai datasets
Pinecone 数据库注册
https://www.pinecone.io/
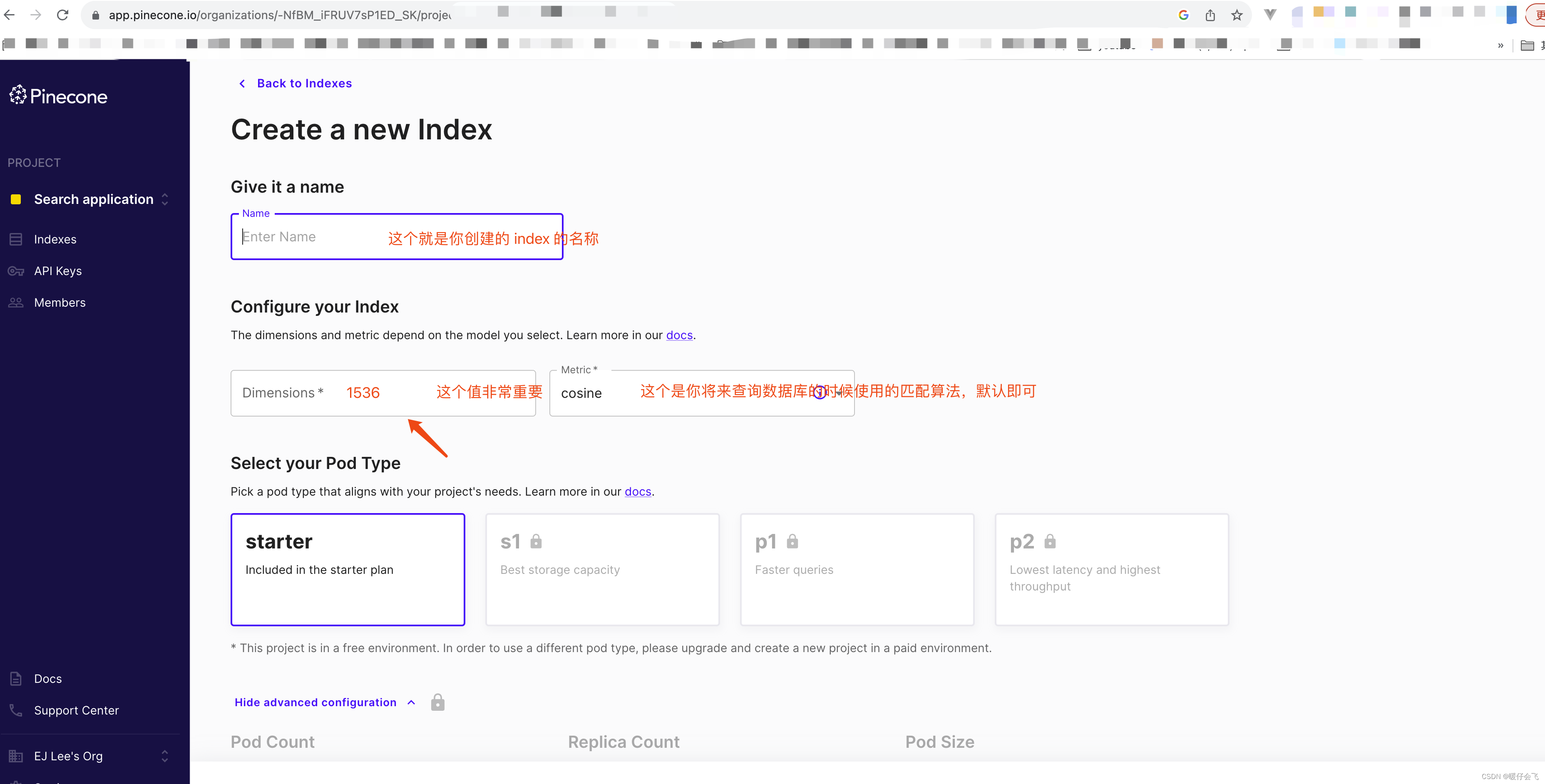
Index 创建(相当于传统数据库中的创建 table)
基于 pinecone 数据库的代码实现
尝试用 OpenAI 的 API 构建 embedding
"""@file: embedding_database.py@Time : 2023/9/25@Author : Peinuan qin"""
import openai
import osopenai.api_key = "[去 OPENAI 官网复制粘贴你自己的 API KEY]"
# get API key from top-right dropdown on OpenAI websiteMODEL = "text-embedding-ada-002"# 基于 text-embedding-ada-002 模型尝试一下将两个句子进行 embedding,默认会构建每个向量的维度是 1536,每个句子都会单独构建一个 embedding 向量
res = openai.Embedding.create(input=["Sample document text goes here","there will be several phrases in each batch"], engine=MODEL
)print(f"vector 0: {len(res['data'][0]['embedding'])}\nvector 1: {len(res['data'][1]['embedding'])}")embeds = [record['embedding'] for record in res['data']]
print(len(embeds))import pineconeindex_name = 'paper-semantic-search'# initialize connection to pinecone (get API key at app.pinecone.io)
pinecone.init(api_key="[去 Pinecone 注册一个账号,并且在你自己的账号下手动创建一个 index,然后将这个 index 的 API Key 拷贝到这里",environment="[这个也是系统默认的,当你复制 API_KEY 的时候就能看见,在同一个页面上]" # find next to api key in console
)# check if 'openai' index already exists (only create index if not)
if index_name not in pinecone.list_indexes():pinecone.create_index(index_name, dimension=len(embeds[0]))
# connect to index
index = pinecone.Index(index_name)将示例的数据 embedding 后写入你的 pinecode (构建向量数据库)
参考
- 基于 pinecone + OpenAI LLM 构建向量数据库视频
- 源码地址
from tqdm.auto import tqdmfrom datasets import load_dataset# load the first 1K rows of the TREC dataset
trec = load_dataset('trec', split='train[:1000]')
count = 0 # we'll use the count to create unique IDs# 设定 batch = 32
batch_size = 32 # process everything in batches of 32
for i in tqdm(range(0, len(trec['text']), batch_size)):# set end position of batchi_end = min(i+batch_size, len(trec['text']))# get batch of lines and IDs# 按照 trec 数据集中的数据的存放方式将每个句子的原文本提取出来, lines_batch 就是个字符串列表,每个列表中有 32 个字符串lines_batch = trec['text'][i: i+batch_size]# 给一个 batch 中的每个句子标号,例如这是第五个 batch,那么对应的编号应该是 160-192ids_batch = [str(n) for n in range(i, i_end)]# 为 batch 中的每个句子创建 embeddings, 使用的模型是 "text-embedding-ada-002"res = openai.Embedding.create(input=lines_batch, engine=MODEL)# OpenAI 返回的结果中不只是包含 embedding 的值,而是为每个 sentence 都创建了一个 json 的形式,因此,利用列表表达式提取出这些 embedding 的值embeds = [record['embedding'] for record in res['data']]# 保留所有的 text 的内容当做元数据(metadata),保留元数据的目的是为了当你在 query pinecone 数据库得到最相似的向量之后,我们可以直接拿到他的文本数据,而不用将这一个最匹配的 embedding 再用 openai 的 api 解码。# 每个 embedding 都对应了一个 json 结构体可以存放他们的元数据,可以存放很多字段meta = [{'text': line} for line in lines_batch]# 最终将他们的 id,embedding 数据和 metadata 打包,放到 pinecode 数据库中存储to_upsert = zip(ids_batch, embeds, meta)# upsert to Pineconeindex.upsert(vectors=list(to_upsert))
构建查询 query
# 查询语句
query = "What caused the 1929 Great Depression?"# 将查询语句进行 embedding
xq = openai.Embedding.create(input=query, engine=MODEL)['data'][0]['embedding']# 使用查询语句的 embedding 从数据库中索引出 cosine 相似度最高的 5 个结果,同时返回这些 embedding 的 metadata
res = index.query([xq], top_k=5, include_metadata=True)# 将这些结果循环打印出来
for match in res['matches']:print(f"{match['score']:.2f}: {match['metadata']['text']}")
删除 Index (慎用)
pinecone.delete_index(index_name)
基于 chroma 数据库的代码实现
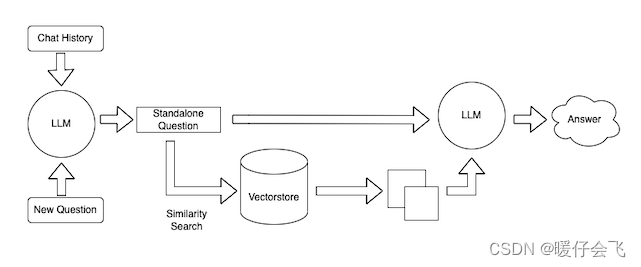
原理介绍
下图来源于博客
依赖安装
pip install langchain
pip install tiktoken
pip install chromadb
pip install unstructured
pip install "unstructured[md]"代码
"""@file: retrival.py@Time : 2023/9/25@Author : Peinuan qin"""
import os
import openai
from langchain.document_loaders import TextLoader, DirectoryLoader
from langchain.indexes import VectorstoreIndexCreatoros.environ['OPENAI_API_KEY'] = "[去 OPENAI 官网复制粘贴你自己的 API KEY]"
query = "[给一个你自己想要的 query]"# 构建 loader 从某个文本文件中建立 index
loader = TextLoader("./data/test.txt")# 也可以直接从目录中构建
# loader = DirectoryLoader("./papers", glob='*.md') # 从一个目录文件夹中将所有扩展名为 md 的文件进行构建 index,但是这需要安装单独的依赖 pip install "unstructure[md]"# 构建基于 chromadb 的索引
index = VectorstoreIndexCreator().from_loaders([loader])llm = ChatOpenAI()
llm.model_name = 'gpt-4'
while True:query = input(">")# 这里的 llm 参数可以不给,当给了 llm 参数之后,系统不仅会在你构建的数据库中进行索引,还会根据 llm 模型对你的答案进行进一步的扩展 print(index.query(query, llm=llm))- 当然还涉及到一些 chromadb 持久化的操作,或者使用原生的 chromadb 进行存储而不是使用 langchain 封装的 chromadb 的方式,可以参考
查看全文
99%的人还看了
相似问题
- 23. 深度学习 - 多维向量自动求导
- 【腾讯云云上实验室-向量数据库】探索腾讯云向量数据库:全方位管理与高效利用多维向量数据的引领者
- 分类预测 | Matlab实现基于DBN-SVM深度置信网络-支持向量机的数据分类预测
- 【VRTK】【VR开发】【Unity】7-配置交互能力和向量追踪
- 【腾讯云云上实验室-向量数据库】TAI时代的数据枢纽-向量数据库 VectorDB
- 计算两个向量的叉积numpy.cross()
- LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索Indexes for information retrieve
- 《向量数据库指南》——什么是 向量数据库Milvus Cloud的Range Search?
- 《向量数据库指南》——亚马逊云科技向量数据库揭秘:点亮数据未来!
- 亚马逊云Amazon OpenSearch Serverless“利刃在手,‘向量’八方“
猜你感兴趣
版权申明
本文"日常学习之:如何基于 OpenAI 构建自己的向量数据库":http://eshow365.cn/6-14075-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 2022年统计用区划代码表SQL 01
- 下一篇: SkyWalking内置MQE语法