已解决
十、性能测试之数据库测试
来自网友在路上 173873提问 提问时间:2023-09-20 07:13:22阅读次数: 73
最佳答案 问答题库738位专家为你答疑解惑
性能测试之数据库测试
- 一、 数据库分类
- 二、 mysql安装及密码的修改
- 1、安装:数据库的版本 mysql5.7版
- 方法1:直接安装
- 方法2:使用rpm包安装
- 方法3:docker方式安装
- 2、修改数据库的密码
- 3、创建库
- 4、创建表
- 三、存储引擎
- 1、InnoDB
- 特点
- 2、MyISAM
- 特点
- 不同的引擎及其介绍
- 四、索引
- 1、简介
- 2、优势和弊端
- 3、分类
- 1、主键索引: id(有且只有一个)
- 2、唯一索引: 不可重复,只有NULL可以重复且可以有多个
- 3、复合索引: **多列**的名称一起建立一个索引,列的字段是有顺序
- 五、 数据库在磁盘的展示
- 六、B树索引
- B+树(balanceTree平衡树)的优点:
- 七、视图
- 1、概念
- 2、作用
- 3、用法
- 八、数据查询解析过程
- 1、数据库解析过程
- 九、影响数据库性能的因素总结
- 十、数据库的性能优化
- 1、操作系统优化
- 2、库的优化
- 数据库常用配置参数及其含义含义
- 十、性能优化实操
- 1、分析慢查询
- 2、数据库连接不够用
一、 数据库分类
- 1、关系型数据库:如mysql
- 2、非关系型数据库:如redis
二、 mysql安装及密码的修改
-
1、安装:数据库的版本 mysql5.7版
- 现在企业中mysql版本,大多在mysql5.7
方法1:直接安装
最简单, 但是因为网络的原因,要下载,可能时间会比较长
rpm -Uvh http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm# 安装mysql-server
yum install mysql-community-server -y# 启动数据库
systemctl restart mysqld# 配置开机自启动
systemctl enable mysqld
方法2:使用rpm包安装
速度很块,但是,包有先后顺序的依赖关系
方法3:docker方式安装
速度很快,但是,需要有docker的技能
# 安装dockeryum install -y yum-utils device-mapper-persistent-data lvm2curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyuncurl -sSL # 重启docker systemctl restart docker# 配置开机自启动systemctl enable docker# 安装mysql并配置相关信息docker run -itd --name mysql -p 3337:3306 -e MYSQL_ROOT_PASSOWORD=123456 mysql:5.7
-
2、修改数据库的密码
-
通过
grep "password" /var/log/mysqld.log可以找到密码,但是这个密码是高复杂度的密码,这个密码不好记忆 -
我们想要修改为低复杂度好记忆的密码
-
修改 mysql数据库的配置文件
/etc/my.cnf- 这个路径,是直接安装mysql数据库方式的 数据库的配置文件路径
- 在[mysqld]节点下
[mysqld]validate_password_policy=0 # 设置为 弱密码 validate_password=off # 关闭密码策略character_set_server=utf8 init_connect='SET NAMES utf8'重启动mysql:
systemctl restart mysqld进入mysql客户端
mysql -uroot -p回车# 修改密码alter user 'root'@'localhost' identified by '123456';# 赋权GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;# 刷新权限FLUSH PRIVILEGES;# 退出exit;mysql的默认端口 3306
-
3、创建库
-
4、创建表
-
三、存储引擎
-
1、InnoDB
- 在mysql5.5以后版本,默认存储引擎InnoDB
-
特点
- 事务优先型,行锁(每次锁定一行,只有锁被释放才能再次修改),索引使用的是B树
-
2、MyISAM
- 5.5以前是MyISAM[maiˈzæm]
-
特点
- 性能优先,表锁(每次锁定一张表),索引有B树、hash索引
- 不同的引擎,有不同的性能。所以我们在建表的时候,要合理的选择存储引擎。
-
不同的引擎及其介绍
-
-
-
建立好了表,表就会有多个字段,往里面写入数据。
- 一般不建议在关系型数据库表中,填加过多字段(一般推荐2,30个字段以内)
- 表列建立索引,主键,默认就是索引。
-
四、索引
-
1、简介
- 是一种数据结构,用于帮助我们在大量数据中快速定位我们要查找的问题
- 典型:汉语字典,书籍目录
- 建索引:使用时间换空间,索引有一定大小,占磁盘/内存空间,以此来换取时间更少
- 建立索引的目的,是加快数据查找速度。但在写入数据时,这一操作会使整个文件增大,导致修改速度变慢。
- 但是,在数据库的使用过程中,查找使用频率时远远高于修改频率,所以我们建表一般会建立索引。
-
2、优势和弊端
- 优势
- 1、降低IO,CPU使用率
- 2、索引列,可以保证行的唯一性
- 3、可以有效缩短数据检索时间
- 4、加快表与表之间的连接
- 弊端
- 1、索引本身很大,通常存在磁盘(也可以存在内存)
- 2、不是所有的情况都可以用索引:数据量少\列值频繁变更\列很少使用
- 3、索引会降低增删改效率,但是一般会提升查效率
- 优势
-
3、分类
- 索引分为主键索引(primary key)、唯一索引(unique index)、复合索引
-
1、主键索引: id(有且只有一个)
- SQL:
create index index_name on table_name(col_name); alter table table_name add index index_name(col_name); -
2、唯一索引: 不可重复,只有NULL可以重复且可以有多个
- SQL:
create unique index index_name on table_name(col_name) -
3、复合索引: 多列的名称一起建立一个索引,列的字段是有顺序
- SQL:
create index index_name on table_name(col_1,col_2......)- 复合索引,字段顺序非常关键,你在使用时,就一定要按照它的顺序来,如果不是按照它的顺序,那么你就没有使用这个复合索引
- 举例:
- st_student (col1,col2,col3,col4,col5,col6)
- fhindex (col1, col3, col4)
- 顺序:
- col1 --> col3 —col4
- col1 —> col3
- col1
- 顺序:
- sql的where条件,就一定要按照fhindex的顺序
- where条件
- 1: col1=?,col2=? ×
- 2: col1=?,col3=? √
- 3: col1=?, col3=?, col4=? √
- 4: col1=? col4=?, col3=? ×
- 5: col3=?, col4=? ×
- 6: col1=?, col4=? ×
- 7: col1=? √
- 8: col3=? ×
- 9: col4=?, col3=? ×
- where条件
-
-
五、 数据库在磁盘的展示
建立了数据库和表之后,在
/var/lib/mysql路径下,就有数据库名称文件夹
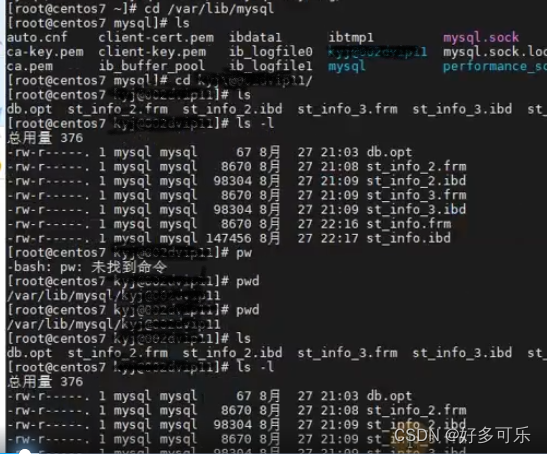
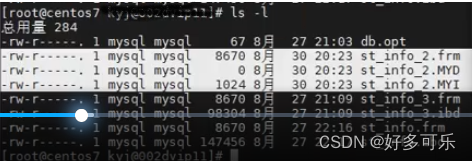
- 文件夹中,就有表名称的文件
- Innodb
- ibd文件,这个表是InnoDB存储引擎时, 数据文件
- frm文件,就是表结构文件
- MyISAM
- frm文件,表结构文件
- MYD文件,数据文件
- MYI文件,索引文件
六、B树索引
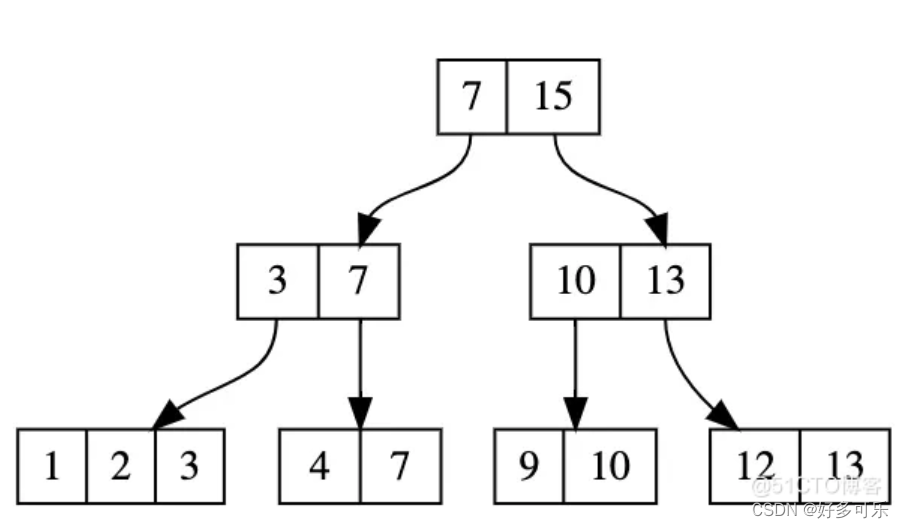
mysql数据库使用InnoDB存储引擎,默认使用B+树索引
- InnoDB存储引擎支持:B+树索引、全文索引、哈希索引,默认是B+树索引
- 可以理解为二叉树,进行旋转而建立一个立体的二叉树集
-
B+树(balanceTree平衡树)的优点:
- 树的层次更低,IO次数更少
- 每次查询的结果都是在叶子节点,查询性能稳定
- 叶子节点形成链表,范围查询方便
- 注意:与存储过程的区别
- 存储过程:是一组为了完成特定功能的sql语句集合,是一个可编辑的函数
- 存储引擎:数据库文件的存储机制,表的类型
-
七、视图
-
1、概念
- 虚拟表,从一个表或多个表中查询出来的表,作用和真实表一样,包含一系列带有行和列的数据。视图中,用户可以使用SELECT语句查询数据,也可以使用INSERT,UPDATE,DELETE修改记录,视图可以使用户操作方便,并保障数据库系统安全
-
2、作用
- 缩减脚本复杂度,提升性能
-
3、用法
- 比如这张表长这样
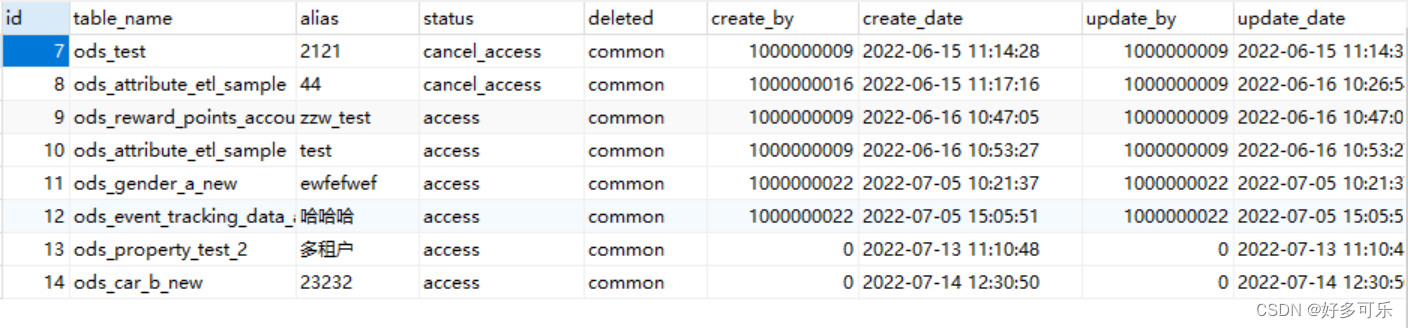
- 新建报表:
CREATE VIEW t_access_dataset_view AS SELECT *FROM t_access_dataset WHERE STATUS = "access";(也可以指定具体字段,后面的查询的那个跟普通的sql语句写法一样的) - 关闭该数据库然后重新进入以后在报表那边可以看到
- 打开表
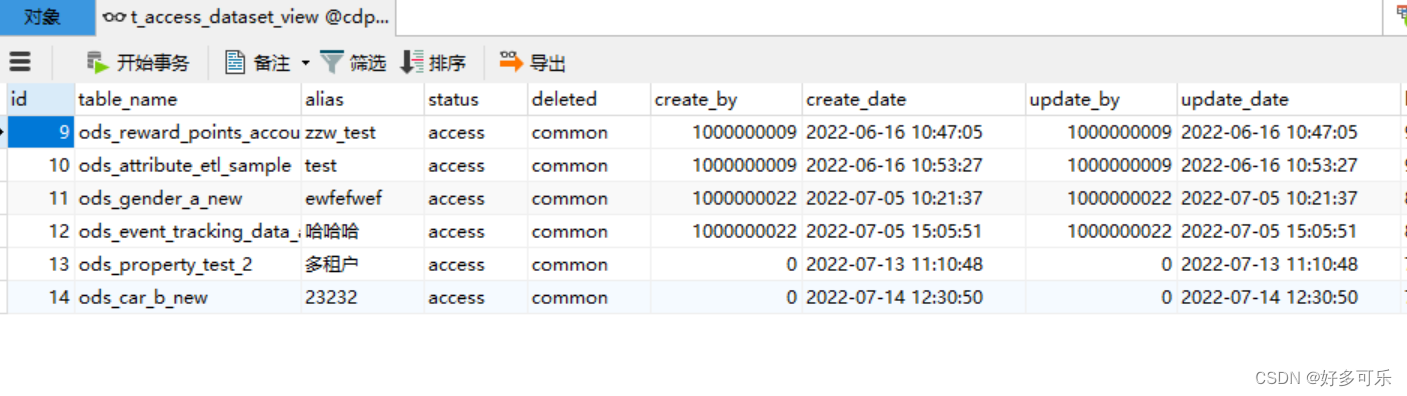
- 后续如果需要在这个的基础上进行过滤,直接查询这个视图就好啦

- 而且如果原表数据更新了,这边的视图也会更新哦,比如原表新增了这个
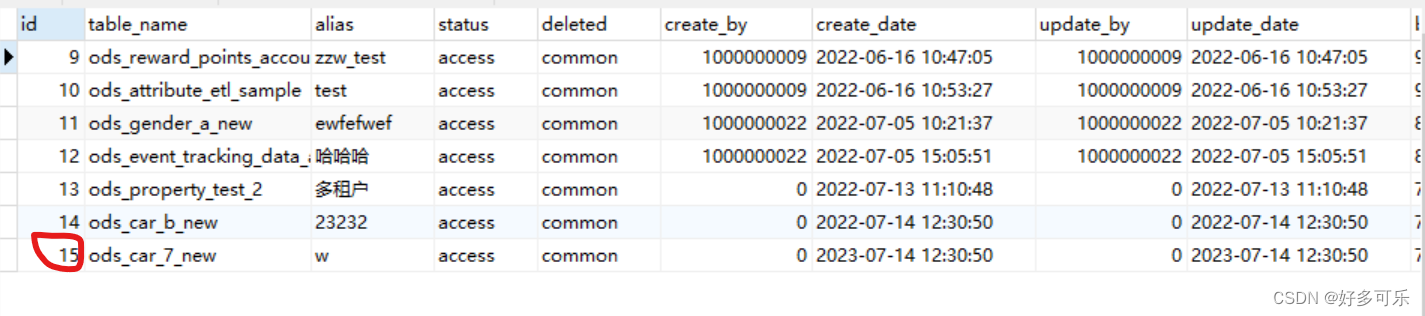
- 我们刷新下视图
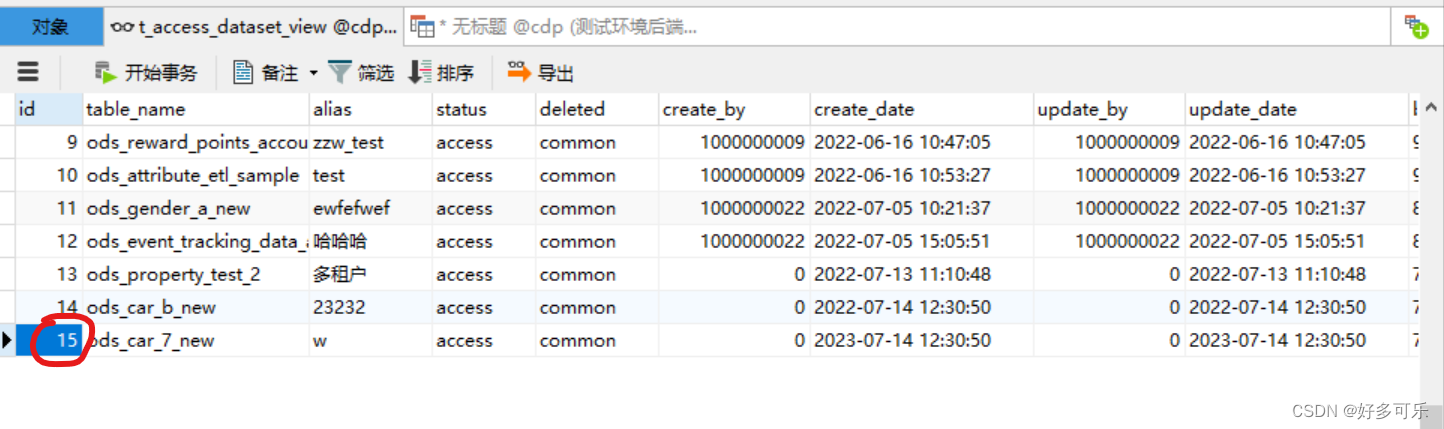
- 比如这张表长这样
八、数据查询解析过程
-
1、数据库解析过程
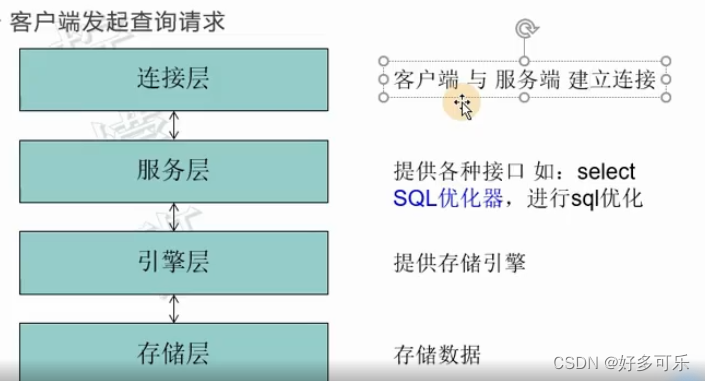
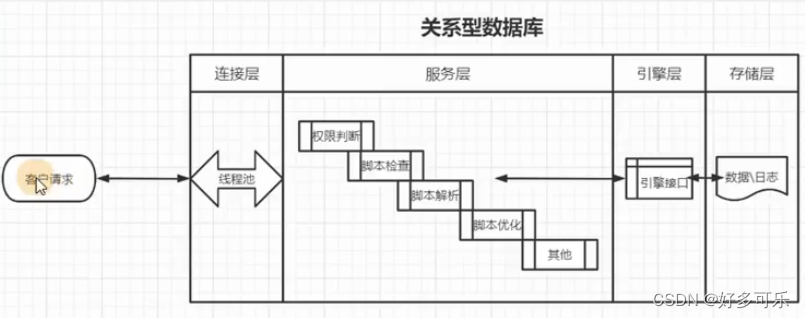
-
- 查询语句的解析过程:
- from 表
- where 条件 过滤数据 --> 条件,影响性能
- group by 查询结果条件来分组 -->列没有变化
- having <expression> 过滤分组 -->在上一步基础上进行过滤
- select 字段 -->这一步的时候,列的数量才会变化
- order by 字段 --> 排序。如果order by的字段不在目前现有的字段里面,会产生一个临时表,是非常消耗性能的,不推荐(回表查询)
- limit 数量限制
-
九、影响数据库性能的因素总结
- 1、表的存储引擎
- 2、表的字段(字段越多性能越差)
- 3、表的索引
- 4、sql语句,where条件
- 5、sql语句,order by
-
十、数据库的性能优化
- 数据库的优化,两个方向: 操作系统+库的优化, 表+sql的优化
- 数据库是用来存储数据的,必然有服务器磁盘操作,磁盘的读写速度也会影响性能。所以数据库的服务器,一般选择IO性能比较高,空间比较大的磁盘进行数据存储
- 操作系统: 操作系统受打开文件数量(一般企业有个16000够用了)和缓存的限制很大
-
1、操作系统优化
- ulimit,可以看到这个只有1024就太小了,(临时修改,还必须重启)
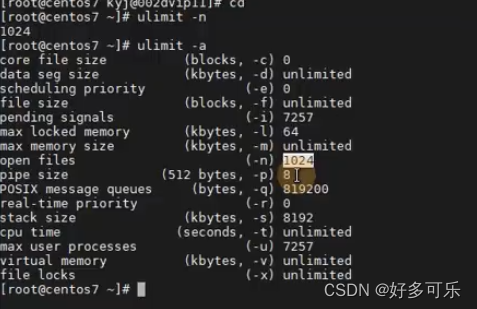
- ulimit,可以看到这个只有1024就太小了,(临时修改,还必须重启)
-
2、库的优化
- show variables: 查看系统相关参数的配置,大概有500+个配置
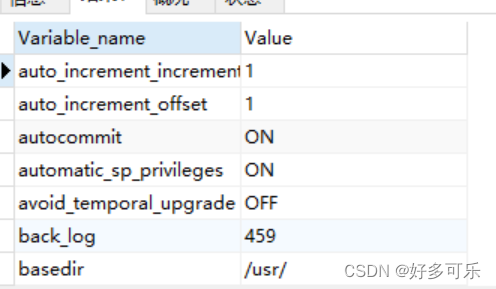
- show variables: 查看系统相关参数的配置,大概有500+个配置
-
数据库常用配置参数及其含义含义
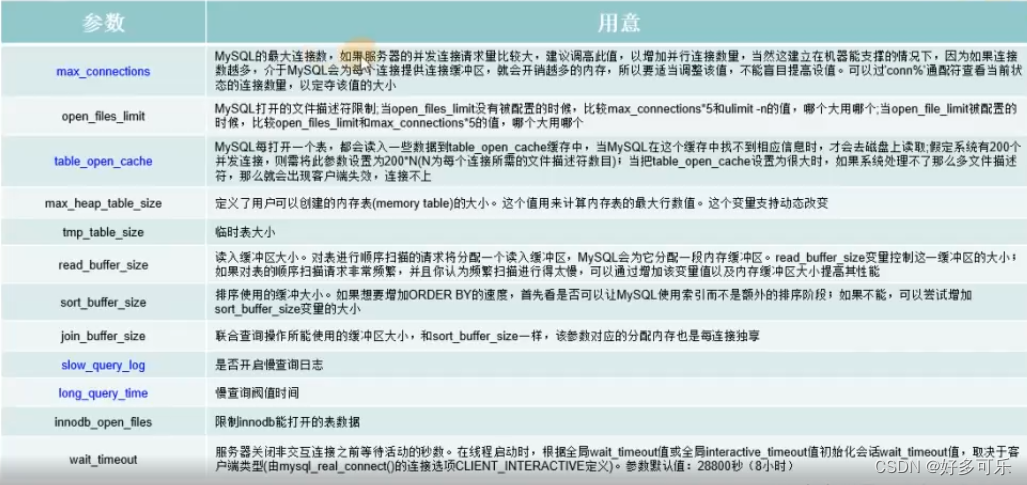
-
-
下面我们对常用参数进行说明:
- 1、table_open_cache 数据表缓存
- 数据库缓存有两种:
- 数据库本身的缓存: 库本身 cache、buff
- 缓存数据库: redis
- 数据库本身的缓存大小是可以被配置,配置的越大,数据库要用的内存也就越大
- 数据库缓存有两种:
- 2、max_heap_table_size 是说 memory存储引擎表的大小为多少 默认16M
- 3、slow_query_log 慢查询的开关
- 4、slow_query_log_file 慢查询开关开启启,慢查询脚本会自动写入文件
- 5、long_query_time 慢查询时间的阈值, 当sql的执行时间超过这个设定时间,就是慢查询。单位: 秒
- 如何获取到慢查询脚本?
- 生产环境中,默认是不会写慢查询日志的。
- slow_query_log 这个开关默认是关闭的,就要开启这个开关
- 开关开启之后,日志就根据long_query_time的时间去判断,超过这个时间,那么就会写入slow_query_log_file文件中去。
- 如何获取到慢查询脚本?
-
可以试着查看下(这里不建议前面加
%,这样性能不太好)
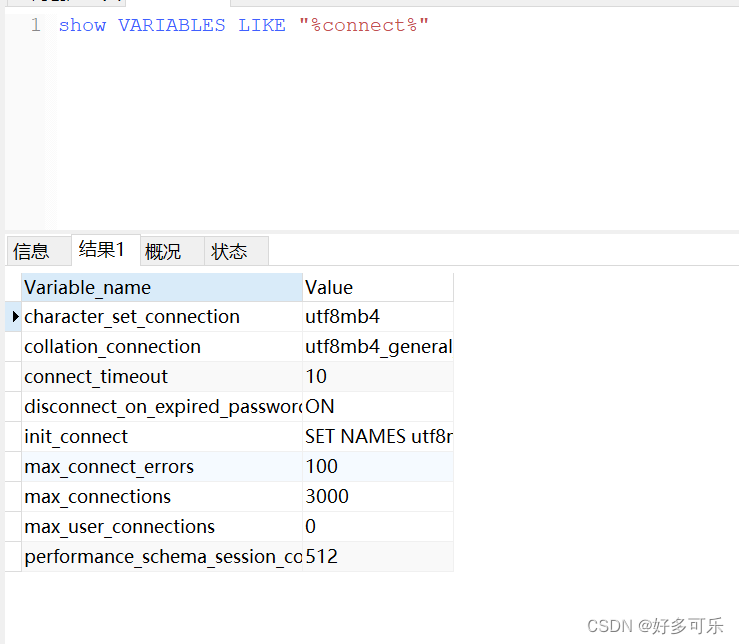
- 配置文件:
/etc/my.cnf - 修改配置:
- 1、
set global var_name=var_value; - 2、修改配置文件
- 1、
- 配置文件:
- 1、table_open_cache 数据表缓存
十、性能优化实操
1、分析慢查询
- 慢查询日志
- 慢查询日志,用来记录mysql中执行时间超过指定时间的查询语句,通过这个日志,可以看出哪些语句执行效率低下,需要优化。但是,开启该日志,会影响数据库性能,所以一般关闭
- 慢查询日志,只是用于定义定位慢查询sql,并不是优化sql
- 查看状态
- show variables like ‘slow_query%’;
- show_query_log 慢查询开启状态
- show_query_log_file 慢查询日志存放位置
- show variables like ‘long_query_time’;
- long_query_file 慢查询的阈值,单位秒 阈值 阈值
- show variables like ‘slow_query%’;
- 开始实战
- 首先我们进入
/etc/my.cnf,在mysqld下面然后修改,加上开启慢查询的语句,然后保存,重启数据库(systemctl restart mysqld;)。或者我们可以修改数据库的配置文件set global variable slow_query_log=ON/OFF; set global variable long_query_time=0.2;进行设置
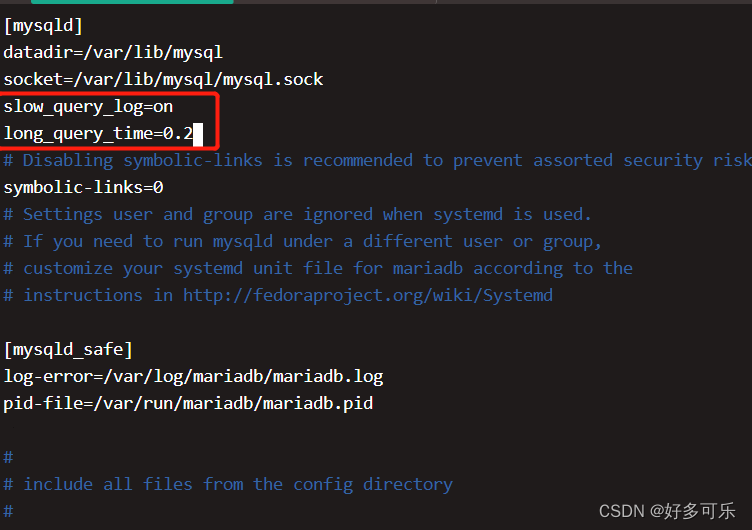
- 然后我们就运行脚本产生慢sql。只有响应时间超过 long_query_time这个设置的时间,才可能出现慢sql
- 在出现慢查询的日志后,我们可以到对应文件去查看(show VARIABLES like ‘%slow_query%’;可以看到对应文件夹)
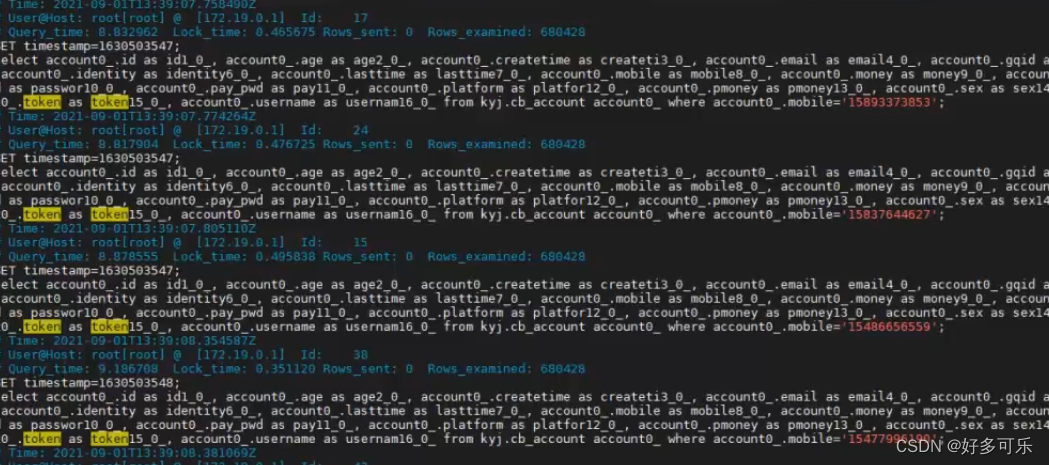
- 首先我们进入
2、数据库连接不够用
- 常见错误
- mysql:ERROR 1040: Too many connections
- 简单定位:可以拿一个navicat试一下,连不上就是连接数不够用
- 定位:
- show variables like ‘max_connections%’; --查看系统配置的最大连接数
- show global status like ‘Max_used_connections’; --查看当前用户已经建立的连接数
- 性能优化提升
- 1、数据库配置连接数不够,修改max_connections值 set global max_connections=512;或者在配置文件中
/etc/my.cnf修改。但是这边也不会调的过大,比如现在设置是151不够用,我们一般会设置为200,最多调到1000,要不然会导致内存消耗过多,效果也不大。调的时候可以参考innodb_open_file_limit和open_file_limit的数量。或者找运维和开发确认下 - 2、程序性能上不去,修改程序配置文件
- 服务器性能上不去,数据库连接足够用,此时,修改程序中数据库连接配置
- 1、数据库配置连接数不够,修改max_connections值 set global max_connections=512;或者在配置文件中
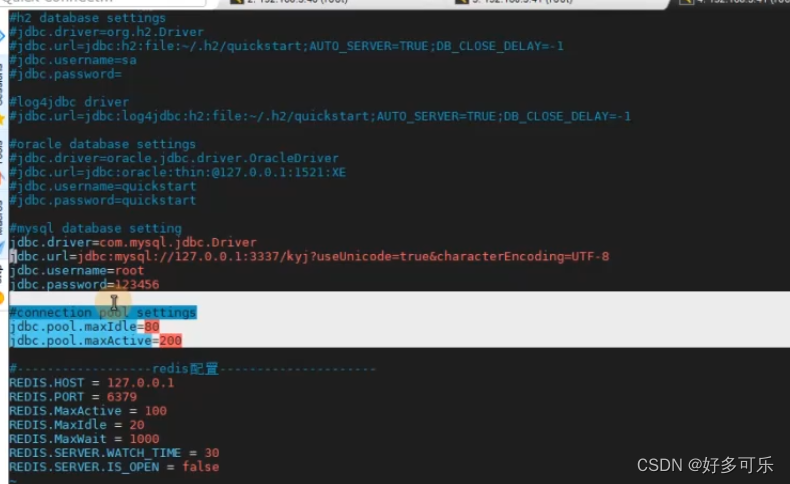
-
但是这块数据通常是开发写在代码里,我们拿不到,我们只能通过应用服务器和数据服务器之间的网络连接数有多少来进行判断,具体脚本如下:
-
配置文件
-
netstat -ano|grep 数据库端口 |grep ESTABLISHED |wc -l
这个命令,在数据库机器中执行 看数据库当前总共有多少的连接数 -
netstat -ano|grep 数据库端口 |grep 应用程序ip |grep ESTABLISHED |wc -l
这个命令,在数据库机器中执行后,就可以看到应用程序xxx与数据库建立连接数有多少
-
-
-
然后再找开发要上图的配置文件进行对比,看看配置文件的参数配置是否太小,需要适当进行调整
查看全文
99%的人还看了
相似问题
- MySQL数据库:开源且强大的关系型数据库管理系统
- 【腾讯云云上实验室-向量数据库】探索腾讯云向量数据库:全方位管理与高效利用多维向量数据的引领者
- 【史上最细教程】服务器MySQL数据库完成主从复制
- 字符串结尾空格比较相关参数BLANK_PAD_MODE(DM8:达梦数据库)
- 缓存雪崩、击穿、穿透及解决方案_保证缓存和数据库一致性
- Redis 与其他数据库的不同之处 | Navicat
- 多协议数据库管理软件 Navicat Premium 16 mac中文版功能
- (数据库管理系统)DBMS与(数据库系统)DBS的区别
- duplicate复制数据库单个数据文件复制失败报错rman-03009 ora-03113
- 数据库课后习题加真题
猜你感兴趣
版权申明
本文"十、性能测试之数据库测试":http://eshow365.cn/6-9855-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!