MySQL搭建主从复制集群,实现读写分离
最佳答案 问答题库738位专家为你答疑解惑
目录
一、准备
二、配置
2.1 配置主库
修改配置文件/etc/my.cnf
重启服务
为主库再创建一个账户并授权
查看状态
2.2 配置从库
修改配置文件/etc/my.cnf
重启mysql服务
配置需要同步的主机
启动salve同步
查看是否同步
三、测试主从复制是否生效
四、读写分离案例
4.1 背景
4.2 Sharding-JDBC介绍
4.3 项目测试前期准备
数据库准备
导入依赖
配置文件
代码生成器
添加依赖
添加配置文件规则
4.4 验证
创建测试方法,包含增删改查
打上断点,以DEBUG的方式启动
发送请求测试
五、主从复制数据不同步的问题
一、准备
准备两台服务器,为每台都安装好mysql。
此时的两台服务器它们的mysql之间没有半毛钱关系,各自是独立的。
如果不会安装,后续我也会出一篇安装教程。请关注我的【编程环境安装】专栏。
二、配置
2.1 配置主库
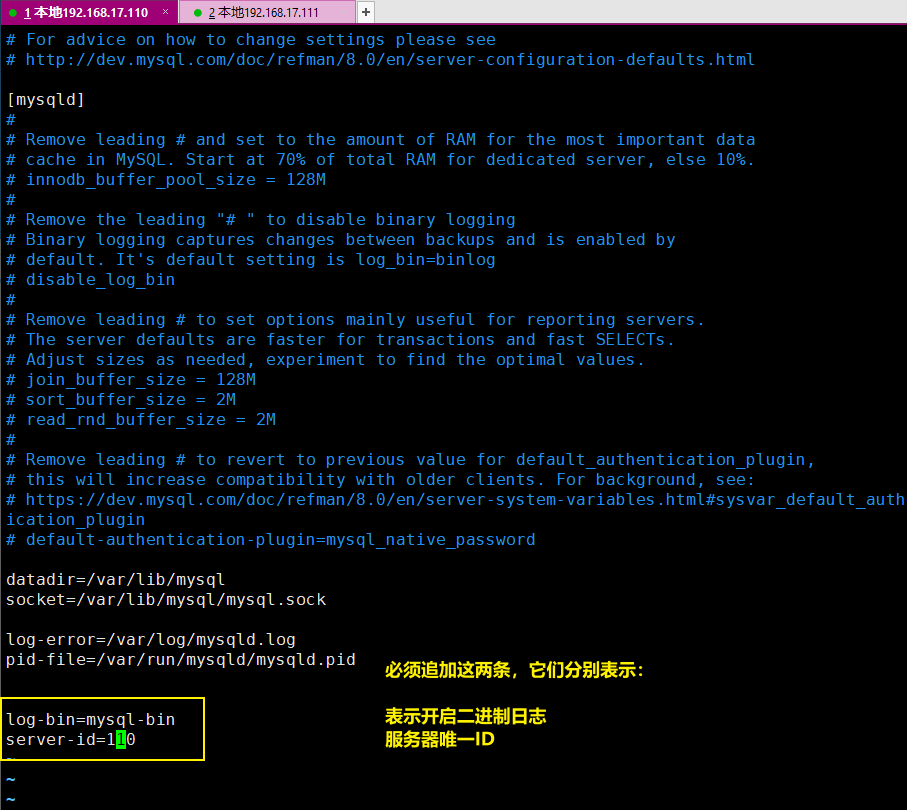
修改配置文件/etc/my.cnf
追加如下:
[mysqld]
log-bin=mysql-bin
server-id=110以后在进行增删改操作的时候,它都会进行记录日志。
重启服务
systemctl restart mysqld
为主库再创建一个账户并授权
CREATE USER '主库用户名'@'%' IDENTIFIED BY '主库用户名密码';
GRANT REPLICATION SLAVE ON *.* TO '主库名称'@'%';
ALTER USER '主库用户名'@'%' IDENDIFIED WITH mysql_native_password BY '主库用户名密码';
flush privileges;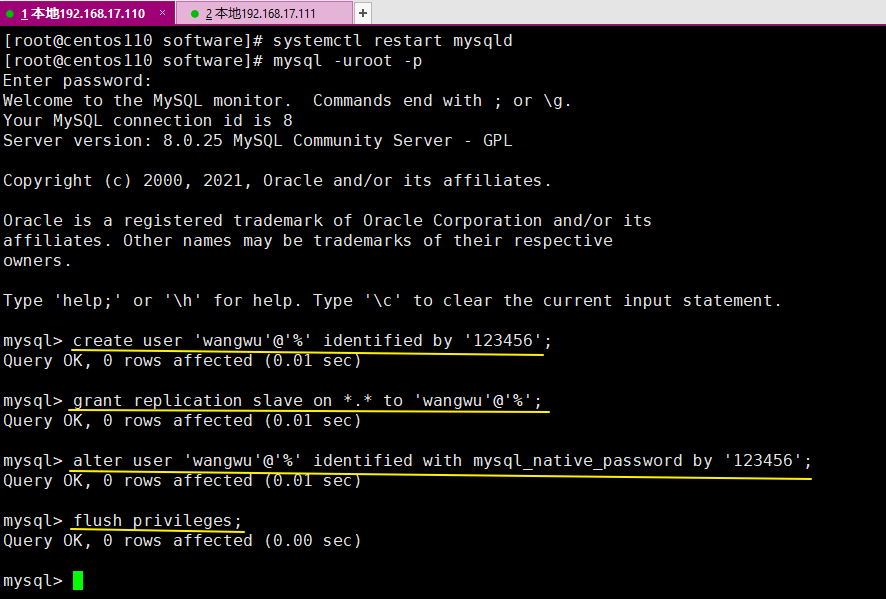
这一步是为主库创建一个用户,并为这个用户授予复制从库的权限。
查看状态
我们先记住这个File和Position的值

记得现在就不要再在主库操作了,否则这个位置就会发生变化。
2.2 配置从库
修改配置文件/etc/my.cnf
增加配置:服务器的唯一标识
server-id=111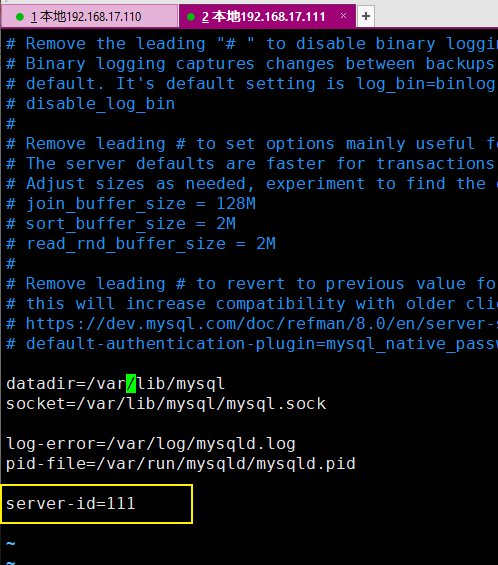
重启mysql服务
systemctl restart mysqld
配置需要同步的主机
CHANGE MASTER TO
MASTER_HOST='主机的ip地址',
MASTER_USER='主机刚才创建的用户名',
MASTER_PASSWORD='主机用户名的密码',
MASTER_LOG_FILE='主机上记录的File值',
MASTER_LOG_POS=主机上记录的Position值;
启动salve同步
start slave; 查看是否同步
查看是否同步
show slave status;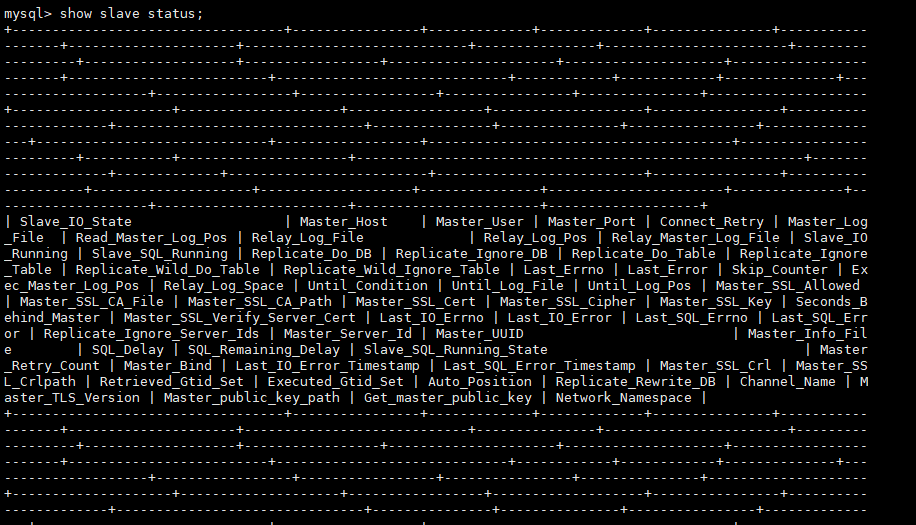 很乱啊,我们把它复制到文本编辑器上来看看
很乱啊,我们把它复制到文本编辑器上来看看

至此,主从复制集群就搭建完成了!
三、测试主从复制是否生效
我们通过navicat连接上这两个数据库,通过操作看看,它们的变化。
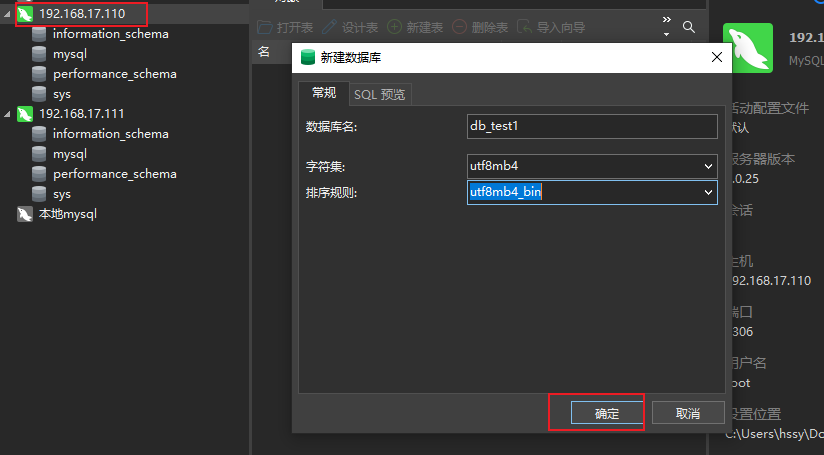
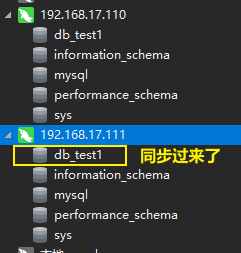
在主库创建一个数据库。

四、读写分离案例
4.1 背景
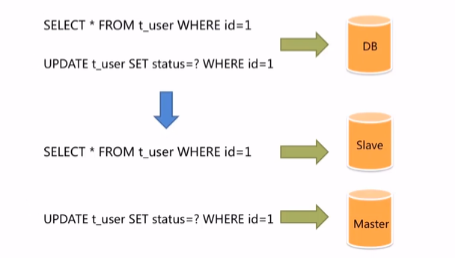
如果系统的访问量增大,既要查询又要写入,单台数据库已经不能满足访问压力了。
这个时候就可以考虑主从复制。将数据库拆分成主库和从库。主库主要负责处理事务性的增删改操作,从库负责处理查询操作。
但是我们的系统怎么知道,我们的操作是查询操作,还是增删改操作?又怎么根据操作的类型选择主库还是从库呢?
这个时候就用到了Sharding-JDBC!
4.2 Sharding-JDBC介绍
Sharding-JDBC定位为轻量级的Java框架,在Java的jdbc层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可以理解为增强版的jdbc驱动,完全兼容jdbc和各种orm框架。
-
适用于任何基于JDBC的ORM框架,如:JPA,Hibernate,Mybatis,Spring JDBC Template或直接使用JDBC。
-
支持任何第三方的数据库连接池,如:DBCP,C3P0,Druid,HikariCP等。
-
支持任意实现JDBC规范的数据库。目前支持Mysql,Oracle,SQL server,PostgreSQL以及任何遵顼SQL92标准的数据库。
4.3 项目测试前期准备
在使用分库分表之前,先要搭建好主从复制的数据库。
然后我们先创建一个web项目:
数据库准备
CREATE TABLE `user` (`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '姓名',`age` tinyint DEFAULT NULL COMMENT '年龄',`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '住址',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='用户'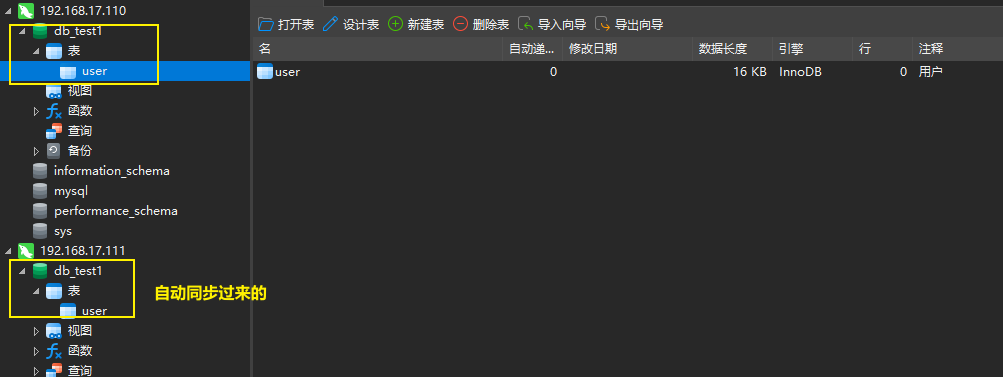
导入依赖
作为web项目基本的一些依赖,没什么好讲的。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.76</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-generator</artifactId><version>3.5.1</version></dependency><dependency><groupId>org.apache.velocity</groupId><artifactId>velocity-engine-core</artifactId><version>2.1</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.12</version></dependency>配置文件
目前只配置了端口号和mybatisplus的相关配置
连数据源连接我们都没有配置,这是因为后面要使用sharding-jdbc
server.port=8080mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus.global-config.db-config.logic-delete-value=1
mybatis-plus.global-config.db-config.logic-not-delete-value=0
mybatis-plus.configuration.map-underscore-to-camel-case=true
mybatis-plus.global-config.db-config.id-type=assign_id代码生成器
使用代码生成器,快速生成刚才创建的表的controller、entity、service、mapper等文件。
这些做好以后,下面开始使用到sharding-jdbc!
添加依赖
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version>
</dependency>添加配置文件规则
# 定义数据源的名字,有几个填写几个,通过.隔开,名字随便取,但是后面配置主从数据源需要根据此名字进行设置
spring.shardingsphere.datasource.names=master-haha,slave-haha
# 数据源1
spring.shardingsphere.datasource.master-haha.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master-haha.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master-haha.url=jdbc:mysql://192.168.17.110:3306/db_test1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.master-haha.username=root
spring.shardingsphere.datasource.master-haha.password=123456
# 数据源2
spring.shardingsphere.datasource.slave-haha.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave-haha.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave-haha.url=jdbc:mysql://192.168.17.111:3306/db_test1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.slave-haha.username=root
spring.shardingsphere.datasource.slave-haha.password=123456# 配置从库负载均衡策略:轮询。就是说从库实际不一定只有一台,当每次查询操作进来的时候,轮询去查每台从库。
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
# 设置最终数据源的名称 其实就是spring中bean对象的名称
spring.shardingsphere.masterslave.name=dataSource
# 指定主库数据源名称
spring.shardingsphere.masterslave.master-data-source-name=master-haha
# 指定从库数据源名称 从库如果有多个,通过逗号隔开
spring.shardingsphere.masterslave.slave-data-source-names=slave-haha
# 开启控制台的sql显示,默认是false
spring.shardingsphere.props.sql.show=true以上规则定义好了,它查询就会去从库(每台从库轮询查),增删改去主库。
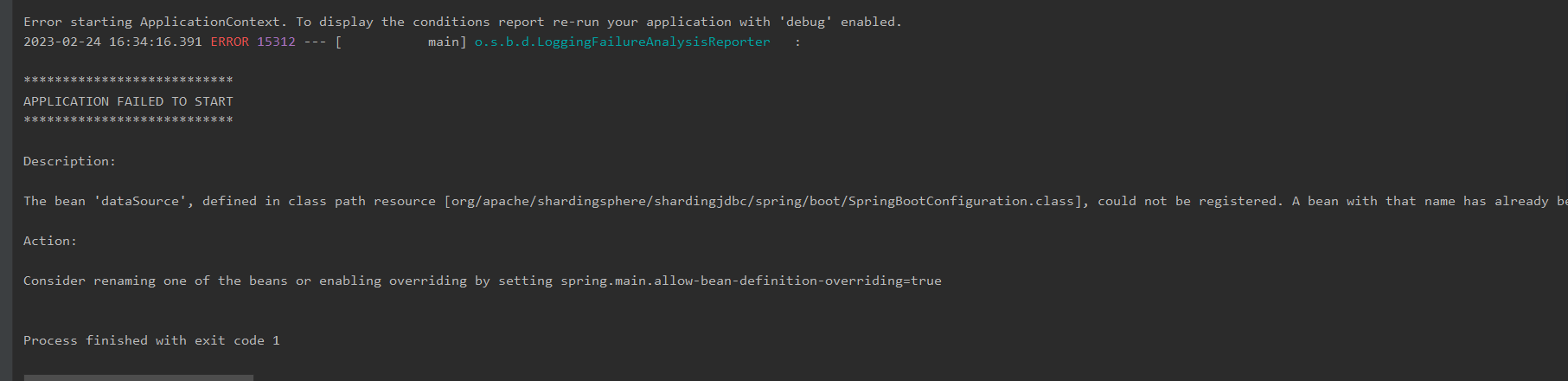
但是,最后还需要修改一下spring的bean覆盖策略,默认是不允许同名bean的。
为什么要修改呢?因为我们定义的bean的名称和druid中定义的bean的名字重复了。
而spring中默认不允许同名的bean的。
所以需要在配置文件中再加上一段配置
# 允许bean定义覆盖,后创建的bean会覆盖前面的同名bean对象
spring.main.allow-bean-definition-overriding=true否则启动项目会报错
 ok,下面我们创建一些测试方法来验证一下。
ok,下面我们创建一些测试方法来验证一下。
4.4 验证
创建测试方法,包含增删改查
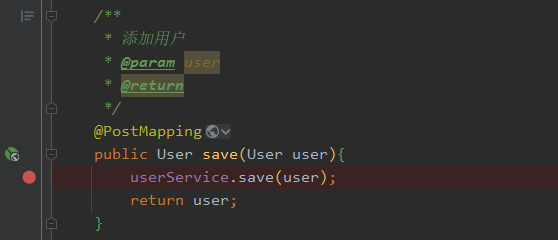
注意这里引入了一个DataSource对象,虽然实际业务代码并没有使用到,但是我们只是想看看它到底是谁。
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {@Autowiredprivate DataSource dataSource;@Autowiredprivate UserService userService;@PostMappingpublic User save(User user){userService.save(user);return user;}@DeleteMapping("/{id}")public void delete(@PathVariable Long id){userService.removeById(id);}@PutMappingpublic User update(User user){userService.updateById(user);return user;}@GetMapping("/{id}")public User getById(@PathVariable Long id){User user = userService.getById(id);return user;}@GetMapping("/list")public List<User> list(User user){LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.eq(user.getId() != null,User::getId,user.getId());queryWrapper.eq(user.getName() != null,User::getName,user.getName());List<User> list = userService.list(queryWrapper);return list;}
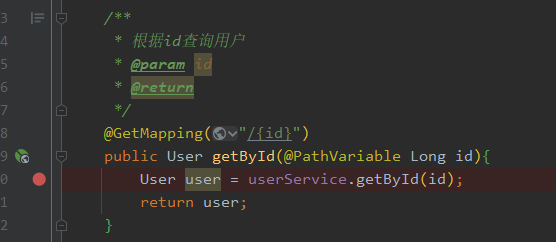
}打上断点,以DEBUG的方式启动
断点的位置我们如图
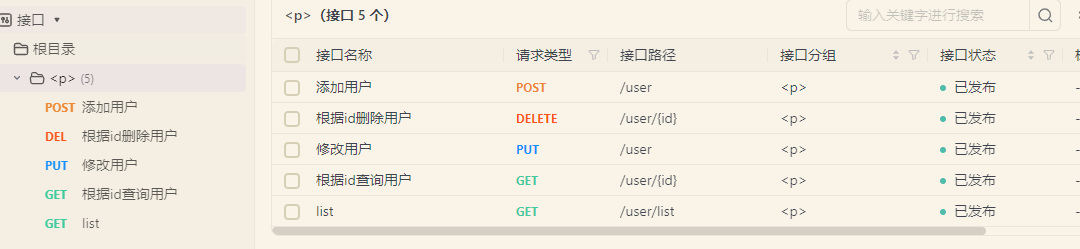
发送请求测试
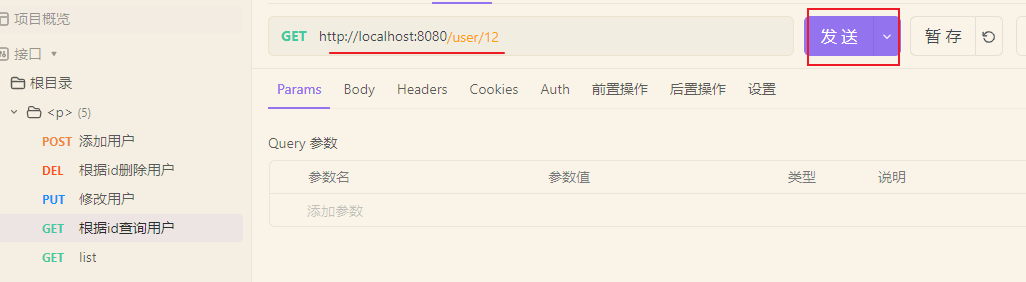
我们可以通过postman来发送请求试试,我这里使用apifox来测试。
先来查询一下
我们发现这个datasource是shardingjdbc提供的

接着放行该请求
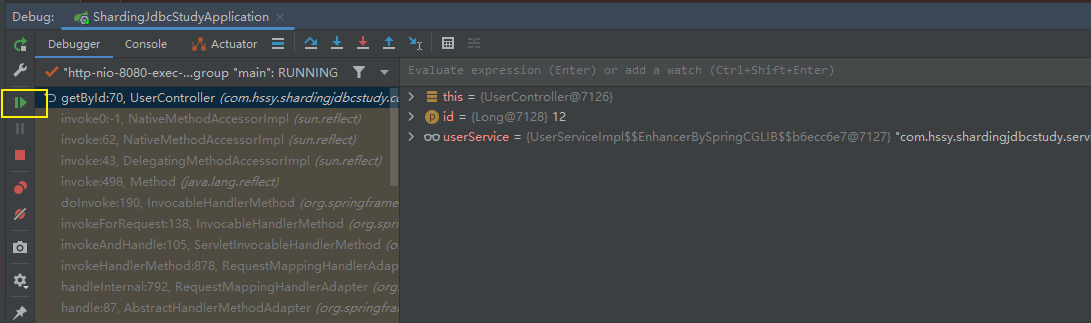
我们通过控制台看到,这条sql是从库去查询的!
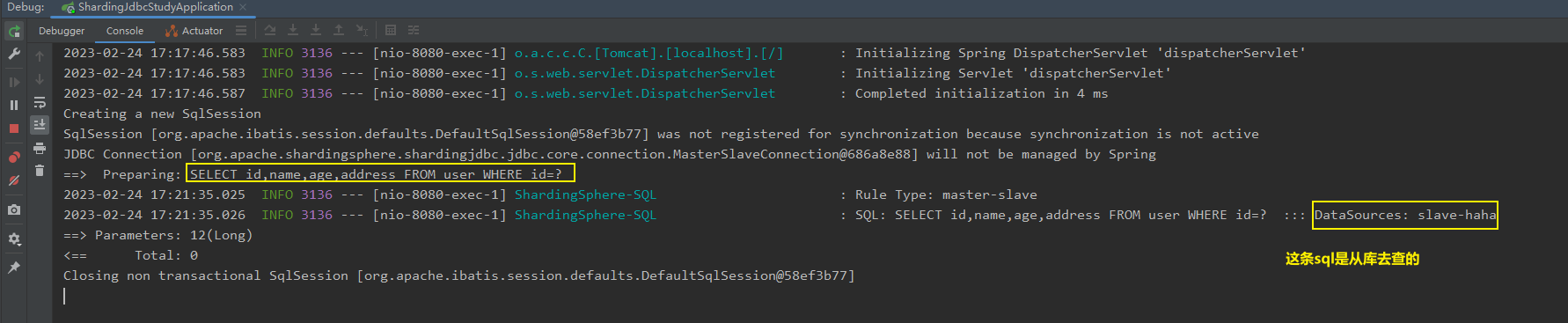
ok,再发送添加请求试试。
我们直接放行,发现添加操作是主库执行的。
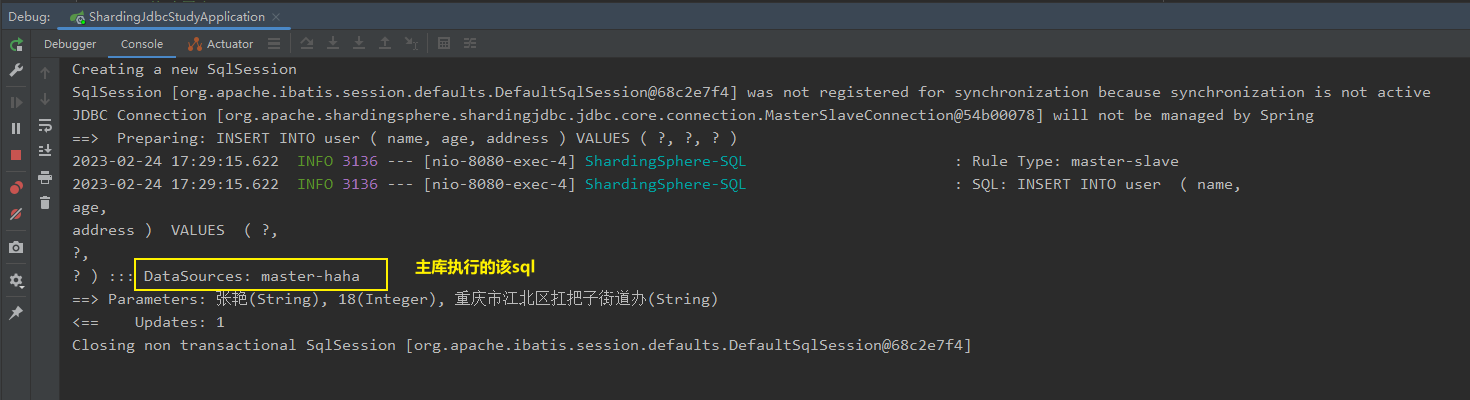
ok,下面我们再检查一下数据库

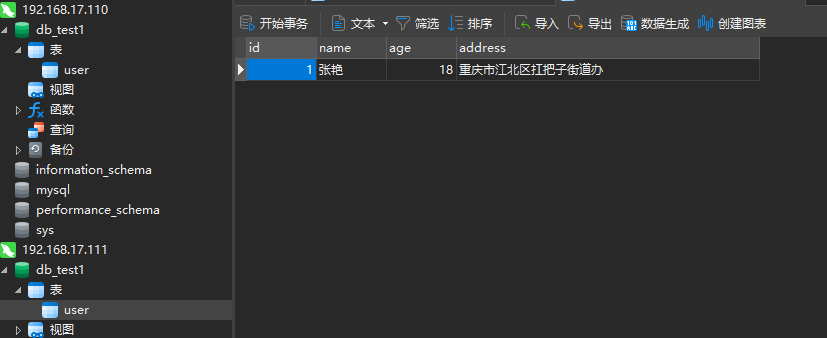
ok,主库也同步到了从库了。
五、主从复制数据不同步的问题
案例:误操作向从库添加了数据。
我通过navicat向从库的user表中生成假数据1w条,这肯定不会同步到主库的。
因为是主库写,从库读。不能乱来。
这就导致从库出现问题。我们通过show slave status;命令查看从库是否同步,发现sql转储线程停掉了。那肯定就不能继续同步数据了。
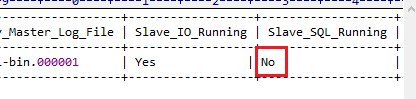
这个时候解决办法就是重新同步。具体方法时间关系就不再赘述了。附上思维导图:
MySQL主从复制那些事儿| ProcessOn免费在线作图,在线流程图,在线思维导图
文章花费了我大量心血和时间,
吃水不忘挖井人,如果对你有帮助,别忘了三连,点赞收藏评论 ~
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"MySQL搭建主从复制集群,实现读写分离":http://eshow365.cn/6-9487-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!