C++(模板进阶)
最佳答案 问答题库818位专家为你答疑解惑
目录
前言:
本章学习目标:
1.非类型模版参数
1.1使用方法
1.2注意事项
1.3 实际引用
2.模版特化
2.1概念
2.2函数模板特化
2.3类模板特化
2.3.1全特化
2.3.2偏特化
3.模版分离编译
编辑 3.1失败原因
编辑 3.2解决方案
4 总结
前言:
本章节是在学习完STL之后,对高阶模版进行的总结,模板给泛型编程注入了灵魂,模板提高了程序的灵活性,模板包括:非类型模版参数、全特化、偏特化等,同时本文还会对模板声明和定义不能分离的问题做出介绍。
本章学习目标:
1.非类型模版参数
模板参数分类 :类型形参与非类型形参。
类型形参即: 出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参: 就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
1.1使用方法
非类型模版参数 既然是使用常量作为参数,那么浮点数、类对象以及字符串是不允许作为非类型模版参数的, 非类型模版参数必须在编译期就能确认结果。
利用非类型模版参数创建一个可以自由调整大小的整形数组代码如下:
#include <assert.h>
using namespace std;template <size_t N>
class arr
{
public:int& operator[](size_t pos){assert(pos >= 0 && pos < N);return _arr[pos];}size_t size() const{return N;}private:int _arr[N];
};
int main()
{arr<5> a1;arr<10> a2;arr<15> a3;cout <<a1.size() << endl;cout << a2.size() << endl;cout << a3.size() << endl;return 0;
}定义一个模板类型的静态数组
template <class T ,size_t N>
class arr
{
public:T& operator[](size_t pos){assert(pos >= 0 && pos < N);return _arr[pos];}size_t size() const{return N;}private:int _arr[N];
};
int main()
{arr<int,5> a1;arr<double,10> a2;arr<char,15> a3;cout <<a1.size()<< typeid(a1).name() << endl;cout << a2.size() << typeid(a2).name()<< endl;cout << a3.size() << typeid(a3).name()<< endl;return 0;
}1.2注意事项
非类型模板参数要求类型为 整型家族,其他类型是不被编译器通过的,如果我们使用非整形的家族成员就会报错,代码如下:
//浮点型,非标准
template<class T, double N>
class arr
{/*……*/
};
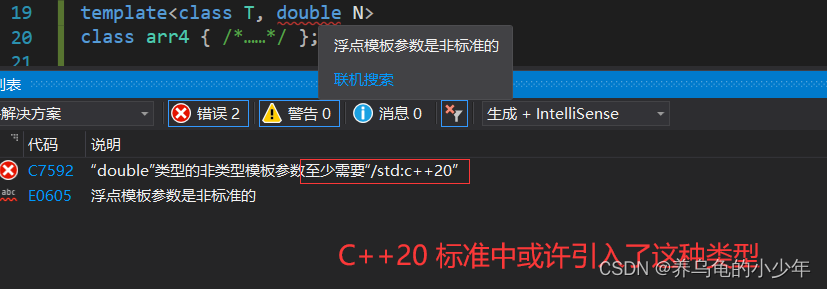
整形家族:char short int bool long longlong
1.3 实际引用
在 C++11 标准中,引入了一个新容器 array,它就使用了 非类型模板参数,为一个真正意义上的 泛型数组,这个数组是用来对标传统数组的。
注意: 部分老编译器可能不支持使用此容器
 新引入arry非类型模版参数的代码 如下:
新引入arry非类型模版参数的代码 如下:
#include <iostream>
#include <cassert>
#include <array> //引入头文件using namespace std;int main()
{int arrOld[10] = { 0 }; //传统数组array<int, 10> arrNew; //新标准中的数组//与传统数组一样,新数组并没有进行初始化//新数组对于越界读、写检查更为严格 优点arrOld[15]; //老数组越界读,未报错arrNew[15]; //新数组则会报错arrOld[12] = 0; //老数组越界写,不报错,出现严重的内存问题arrNew[12] = 10; //新数组严格检查return 0;
}
array 是泛型编程思想中的产物,支持了许多 STL 容器的功能,比如 迭代器 和 运算符重载 等实用功能,最主要的改进是 严格检查越界行为。
需要提醒的是:arry能做到严格的越界检查 得益于 []的重载,对下标进行了严格检查。
2.模版特化
2.1概念
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理,比如:使用 日期类对象指针 构建优先级队列后,若不编写对应的仿函数,则比较结果会变为未定义 代码如下:
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}
int main()
{cout << Less(1, 2) << endl; // 可以比较,结果正确Date d1(2022, 7, 7);Date d2(2022, 7, 8);cout << Less(d1, d2) << endl; // 可以比较,结果正确Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl; // 可以比较,结果错误return 0;
}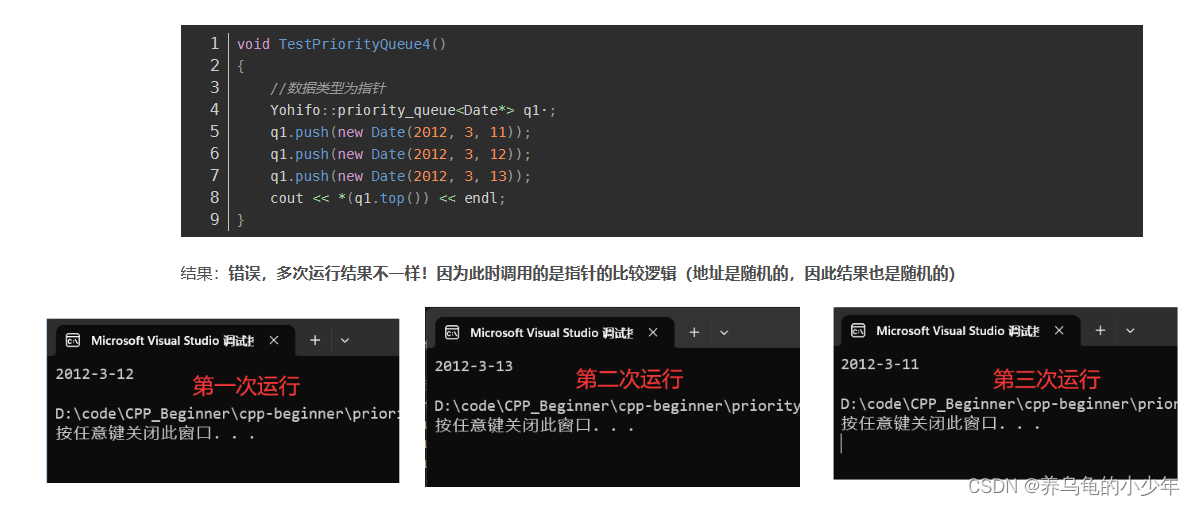
造成每次结果不一样是因为 我们每次都日期类对象比较的时候 系统每次分配的地址都是随机的,我们对地址进行比较是不符合实际情况的。
2.2函数模板特化
1. 必须要先有一个基础的函数模板
2. 关键字template后面接一对空的尖括号<>
3. 函数名后跟一对尖括号,尖括号中指定需要特化的类型
4. 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
上述日期进行比较的函数模版进行特化之后,代码如下:
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}
// 对Less函数模板进行特化
template<>
bool Less<Date*>(Date* left, Date* right)
{return *left < *right;
}
int main()
{cout << Less(1, 2) << endl;Date d1(2022, 7, 7);Date d2(2022, 7, 8);cout << Less(d1, d2) << endl;Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl; // 调用特化之后的版本,而不走模板生成了return 0;
}2.3类模板特化
模板特化主要用在类模板中,它可以在泛型思想之上解决大部分特殊问题,并且类模板特化还可以分为:全特化和偏特化,适用于不同场景
后面用的日期类举例比较多,先把日期类放出来
class Date
{
public:Date(int year = 1970, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}private:int _year;int _month;int _day;
};2.3.1全特化
全特化指 将所有的模板参数特化为具体类型,将模板全特化后,调用时,会优先选择更为匹配的模板类
//原模板
template<class T1, class T2>
class Test
{
public:Test(const T1& t1, const T2& t2):_t1(t1),_t2(t2){cout << "template<class T1, class T2>" << endl;}private:T1 _t1;T2 _t2;
};//全特化后的模板
template<>
class Test<int, char>
{
public:Test(const int& t1, const char& t2):_t1(t1), _t2(t2){cout << "template<>" << endl;}private:int _t1;char _t2;
};int main()
{Test<int, int> T1(1, 2);Test<int, char> T2(20, 'c');return 0;
}

对模板进行全特化处理后,实际调用时,会优先选择已经特化并且类型符合的模板。
2.3.2偏特化
偏特化,指 将泛型范围进一步限制,可以限制为某种类型的指针,也可以限制为具体类型
//原模板---两个模板参数
template<class T1, class T2>
class Test
{
public:Test(){cout << "class Test" << endl;}
};//偏特化之一:限制为某种类型
template<class T1>
class Test<T1, int>
{
public:Test(){cout << "class Test<T, int>" << endl;}
};//偏特化之二:限制为不同的具体类型
template<class T>
class Test<T*, T*>
{
public:Test(){cout << "class Test<T*, T*>" << endl;}
};int main()
{Test<double, double> t1;Test<char, int> t2;Test<Date*, Date*> t3;return 0;
}
偏特化(尤其是限制为某种类型)在 泛型思想 和 特殊情况 之间做了折中处理,使得 限制范围式的偏特化 也可以实现 泛型
- 比如偏特化为
T*,那么传int*、char*、Date*都是可行的
应用实例:
有如下专门用来按照小于比较的类模板 :Less
#include<vector>
#include <algorithm>
template<class T>
struct Less
{bool operator()(const T& x, const T& y) const{return x < y;}
};
int main()
{Date d1(2022, 7, 7);Date d2(2022, 7, 6);Date d3(2022, 7, 8);vector<Date> v1;v1.push_back(d1);
v1.push_back(d2);v1.push_back(d3);// 可以直接排序,结果是日期升序sort(v1.begin(), v1.end(), Less<Date>());vector<Date*> v2;v2.push_back(&d1);v2.push_back(&d2);v2.push_back(&d3);// 可以直接排序,结果错误日期还不是升序,而v2中放的地址是升序// 此处需要在排序过程中,让sort比较v2中存放地址指向的日期对象// 但是走Less模板,sort在排序时实际比较的是v2中指针的地址,因此无法达到预期sort(v2.begin(), v2.end(), Less<Date*>());return 0;
}
// 对Less类模板按照指针方式特化
template<>
struct Less<Date*>
{bool operator()(Date* x, Date* y) const{return *x < *y;}
};3.模版分离编译
早在 模板初阶 中,我们就已经知道了 模板不能进行分离编译,会引发链接问题
 3.1失败原因
3.1失败原因
声明与定义分离后,在进行链接时,无法在符号表中找到目标地址进行跳转,因此链接错误
下面是 模板声明与定义写在同一个文件中时,具体的汇编代码执行步骤
test.h
#pragma once//声明
template<class T>
T add(const T x, const T y);//定义
template<class T>
T add(const T x, const T y)
{return x + y;
}
main.cpp
#include <iostream>
#include "Test.h"using namespace std;int main()
{add(1, 2);return 0;
}
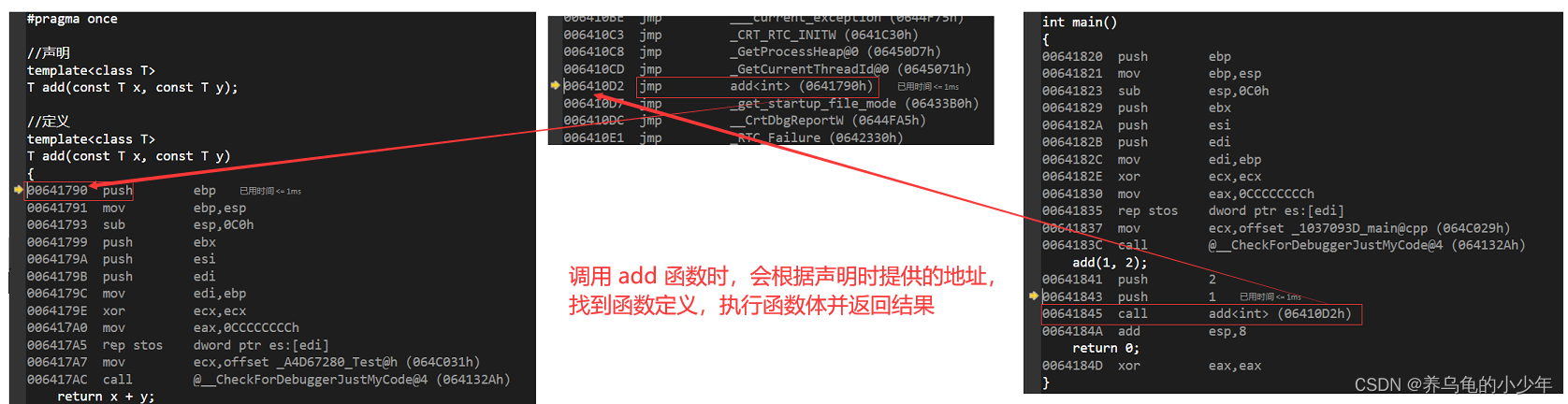
声明与定义在同一个文件中时,可以直接找到函数的地址
编译器 生成可执行文件的四个步骤:
- 预处理:头文件展开、宏替换、条件编译、删除注释,生成纯净的C代码
- 编译:语法 / 词法 / 语义 分析、符号汇总,生成汇编代码
- 汇编:生成符号表,生成二进制指令
- 链接:合并段表,将符号表进行合并和重定位,生成可执行程序
当模板的 声明 与 定义 分离时,因为是 【泛型】,所以编译器无法确定函数原型,即 无法生成函数,也就无法获得函数地址,在符号表中进行函数链接时,必然失败
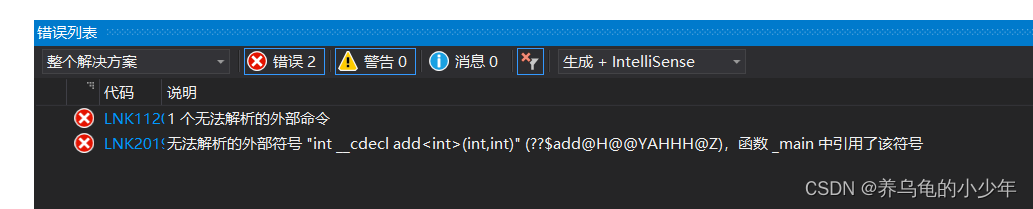 3.2解决方案
3.2解决方案
解决方法有两种:
- 在函数定义时进行模板特化,编译时生成地址以进行链接
- 模板的声明和定义不要分离,直接写在同一个文件中
//定义
//解决方法一:模板特化(不推荐,如果类型多的话,需要特化很多份)
template<>
int add(const int x, const int y)
{return x + y;
}
//定义
//解决方法二:声明和定义写在同一个文件中
template<class T>
T add(const T x, const T y)
{return x + y;
}
这也就解释了为什么涉及 模板 的类,其中的函数声明和定义会写在同一个文件中 (.h),著名的 STL 库中的代码的声明和定义都是在一个 .h 文件中
为了让别人一眼就看出来头文件中包含了 声明 与 定义,可以将头文件后缀改为
.hpp,著名的Boost库中就有这样的命名方式
4 总结
模板是 STL 的基础支撑,假若没有模板、没有泛型编程思想,那么恐怕 "STL" 会变得非常大
模板的优点:
模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
增强了代码的灵活性
模板的缺点:
模板会导致代码膨胀问题,也会导致编译时间变长
出现模板编译错误时,错误信息非常凌乱,不易定位错误位置
总之,模板 是一把双刃剑,既有优点,也有缺点,只有把它用好了,才能使代码 更灵活、更优雅
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"C++(模板进阶)":http://eshow365.cn/6-42042-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: maven打包可执行jar含依赖lib
- 下一篇: YAML 深入解析:从语法到最佳实践