C++:利用哈希表对unordered系列容器模拟实现
最佳答案 问答题库1038位专家为你答疑解惑
文章目录
- unordered容器使用
- [在长度 2N 的数组中找出重复 N 次的元素](https://leetcode.cn/problems/n-repeated-element-in-size-2n-array/description/)
- 底层结构
- 初步改造哈希表
- 基本逻辑的实现
- 最终实现
本篇主要总结unordered系列容器和其底层结构
unordered容器使用
从使用的角度来讲,不管是unordered_map还是unordered_set,本质上就是把内容不再有序,而是采用无序的方式进行存储,对于其实现细节在后续会进行封装
在长度 2N 的数组中找出重复 N 次的元素

对于之前的方法,大多使用一种类似于计数排序的方法来解决问题
class Solution
{
public:int repeatedNTimes(vector<int>& nums) {int hash[10001] = {0};for(auto e : nums){hash[e]++;}for(auto e : nums){if(hash[e] != 1)return e;}return -1;}
};
而利用unordered_set,可以更方便的解决问题
class Solution {
public:int repeatedNTimes(vector<int>& nums) {unordered_set<int> found;for (int num: nums) {if (found.count(num)) {return num;}found.insert(num);}// 不可能的情况return -1;}
};
底层结构
unordered系列的关联式容器,在进行查找等的效率比较高,究其原因是因为使用了哈希的结构,那么下面就利用哈希表,来对这两个容器进行封装
首先搭建出主体框架
// set
#pragma once
#include "HashTable.h"
namespace myset
{template<class K>class unordered_set{struct SetKeyOfT{K& operator()(K& key){return key;}};public:bool insert(const K& key){return _table.insert(key);}void print(){_table.print();}private:opened_hashing::HashTable<K, K, SetKeyOfT> _table;};
}// map
#pragma once#include "HashTable.h"namespace mymap
{template<class K, class V>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& key){return key.first;}};public:bool insert(const pair<K, V>& key){return _table.insert(key);}void print(){_table.print();}private:opened_hashing::HashTable<K, pair<K, V>, MapKeyOfT> _table;};
}// 测试函数
// 最基础的测试
void test_set1()
{myset::unordered_set<int> st;st.insert(1);st.insert(2);st.insert(60);st.insert(50);st.print();
}void test_map1()
{mymap::unordered_map<int, int> dict;dict.insert(make_pair(1, 1));dict.insert(make_pair(2, 2));dict.insert(make_pair(3, 3));dict.insert(make_pair(4, 4));
}
此时运行会报错
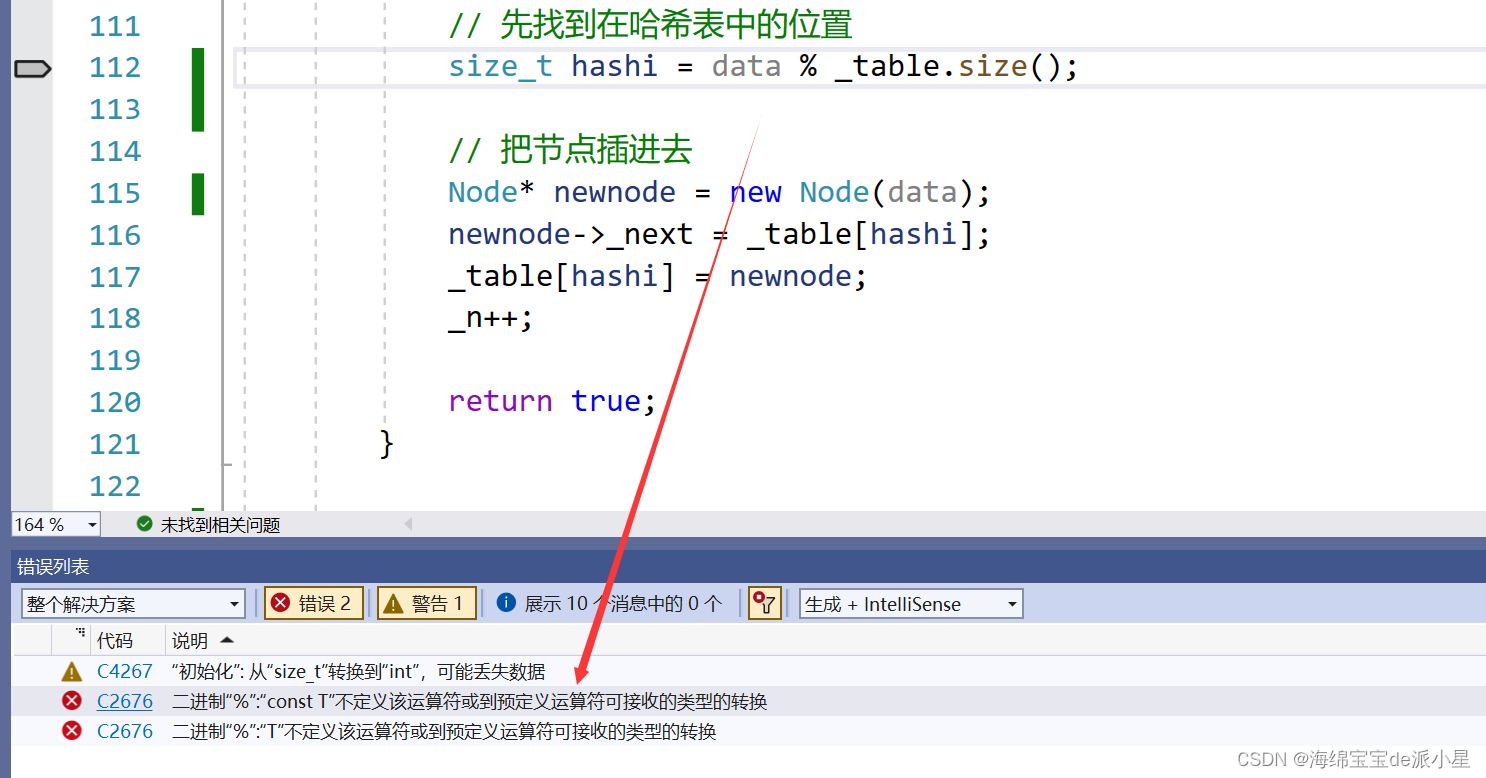
报错的原因是因为,对于map来说Value传递的是键值对,键值对不可以直接进行运算,因此要引入KeyOfT的概念,这里借助这个仿函数找到Key值

下面实现迭代器的内容:
对于哈希表来说,迭代器内部包含的就是一个一个节点的地址:
实现++
对于哈希表来说,实现++的逻辑可以看成,看当前节点的下一个还有没有值,如果没有就说明走到最后了,要找下一个哈希桶里面的内容,如果后面还有值,那就是下一个内容
那么如何记录所在的桶,可以通过对哈希表的位置进行定位来获取现在属于哪一桶,进而去寻找下一个桶
初步改造哈希表
#pragma once
#include <iostream>
#include <vector>
using namespace std;namespace opened_hashing
{template<class T>struct _Convert{T& operator()(T& key){return key;}};template<>struct _Convert<string>{size_t& operator()(const string& key){size_t sum = 0;for (auto e : key){sum += e * 31;}return sum;}};// 定义节点信息template<class T>struct Node{Node(const T& data):_next(nullptr), _data(data){}Node* _next;T _data;};template<class K, class T, class KeyOfT>class HashTable;template<class K, class T, class Ref, class Ptr, class KeyOfT>struct _iterator{typedef _iterator<K, T, T&, T*, KeyOfT> Self;typedef Node<T> Node;_iterator(Node* node, HashTable<K, T, KeyOfT>* pht, int hashi):_node(node), _pht(pht), _hashi(hashi){}Self operator++(){// 如果后面还有值,++就是到这个桶的下一个元素if (_node->_next){_node = _node->_next;}else{++_hashi;while (_hashi < _pht->_table.size()){if (_pht->_table[_hashi]){_node = _pht->_table[_hashi];break;}++_hashi;}if (_hashi == _pht->_table.size()){_node = nullptr;}}return *this;}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self& s){return _node != s._node;}Node* _node;int _hashi; // 现在位于哪个桶HashTable<K, T, KeyOfT>* _pht; // 迭代器所在的哈希表};template<class K, class T, class KeyOfT>class HashTable{template<class K, class T, class Ref, class Ptr, class KeyOfT>friend struct _iterator;typedef Node<T> Node;public:typedef _iterator<K, T, T&, T*, KeyOfT> iterator;// 构造函数HashTable():_n(0){_table.resize(10);}// 析构函数~HashTable(){//cout << endl << "*******************" << endl;//cout << "destructor" << endl;for (int i = 0; i < _table.size(); i++){//cout << "[" << i << "]->";Node* cur = _table[i];while (cur){Node* next = cur->_next;//cout << cur->_kv.first << " ";delete cur;cur = next;}//cout << endl;_table[i] = nullptr;}}// 迭代器iterator begin(){for (int i = 0; i < _table.size(); i++){if (_table[i]){return iterator(_table[i], this, i);}}return end();}iterator end(){return iterator(nullptr, this, -1);}// 插入元素bool insert(const T& data){KeyOfT kot;// 如果哈希表中有这个元素,就不插入了if (find(data)){return false;}// 扩容问题if (_n == _table.size()){HashTable newtable;int newsize = (int)_table.size() * 2;newtable._table.resize(newsize, nullptr);for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 把哈希桶中的元素插入到新表中int newhashi = kot(cur->_data) % newsize;// 头插cur->_next = newtable._table[newhashi];newtable._table[newhashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable._table);}// 先找到在哈希表中的位置size_t hashi = kot(data) % _table.size();// 把节点插进去Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return true;}Node* find(const T& Key){KeyOfT kot;// 先找到它所在的桶int hashi = kot(Key) % _table.size();// 在它所在桶里面找数据Node* cur = _table[hashi];while (cur){if (cur->_data == Key){return cur;}cur = cur->_next;}return nullptr;}private:vector<Node*> _table;size_t _n;};
}
基本逻辑的实现
// set
#pragma once
#include "HashTable.h"
namespace myset
{template<class K>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};typedef typename opened_hashing::HashTable<K, K, SetKeyOfT>::iterator iterator;public:iterator begin(){return _table.begin();}iterator end(){return _table.end();}bool insert(const K& key){return _table.insert(key);}private:opened_hashing::HashTable<K, K, SetKeyOfT> _table;};
}// map
#pragma once#include "HashTable.h"namespace mymap
{template<class K, class V>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& key){return key.first;}};typedef typename opened_hashing::HashTable<K, pair<K, V>, MapKeyOfT>::iterator iterator;public:iterator begin(){return _table.begin();}iterator end(){return _table.end();}bool insert(const pair<K, V>& key){return _table.insert(key);}private:opened_hashing::HashTable<K, pair<K, V>, MapKeyOfT> _table;};
}
现在的主体框架已经搭建出来了,用下面的测试用例已经可以实现迭代器遍历了,证明我们的基本框架逻辑已经完成了
// 最基础的测试
void test_set1()
{myset::unordered_set<int> st;st.insert(1);st.insert(2);st.insert(60);st.insert(50);auto it = st.begin();while (it != st.end()){cout << *it << " ";++it;}cout << endl;cout << endl;cout << endl;
}void test_map1()
{mymap::unordered_map<int, int> dict;dict.insert(make_pair(1, 1));dict.insert(make_pair(10, 1));dict.insert(make_pair(220, 1));auto it = dict.begin();while (it != dict.end()){cout << (*it).first << ":" << (*it).second << endl;++it;}cout << endl;
}
但当遇到string类的内容就不可以继续进行了
// 带有string类的内容
void test_set2()
{myset::unordered_set<string> st;st.insert("apple");st.insert("banana");st.insert("pear");st.insert("cake");auto it = st.begin();while (it != st.end()){cout << *it << " ";++it;}cout << endl;cout << endl;cout << endl;
}void test_map2()
{mymap::unordered_map<string, string> dict;dict.insert(make_pair("排序", "sort"));dict.insert(make_pair("苹果", "apple"));dict.insert(make_pair("香蕉", "banana"));auto it = dict.begin();while (it != dict.end()){cout << (*it).first << ":" << (*it).second << endl;++it;}cout << endl;
}
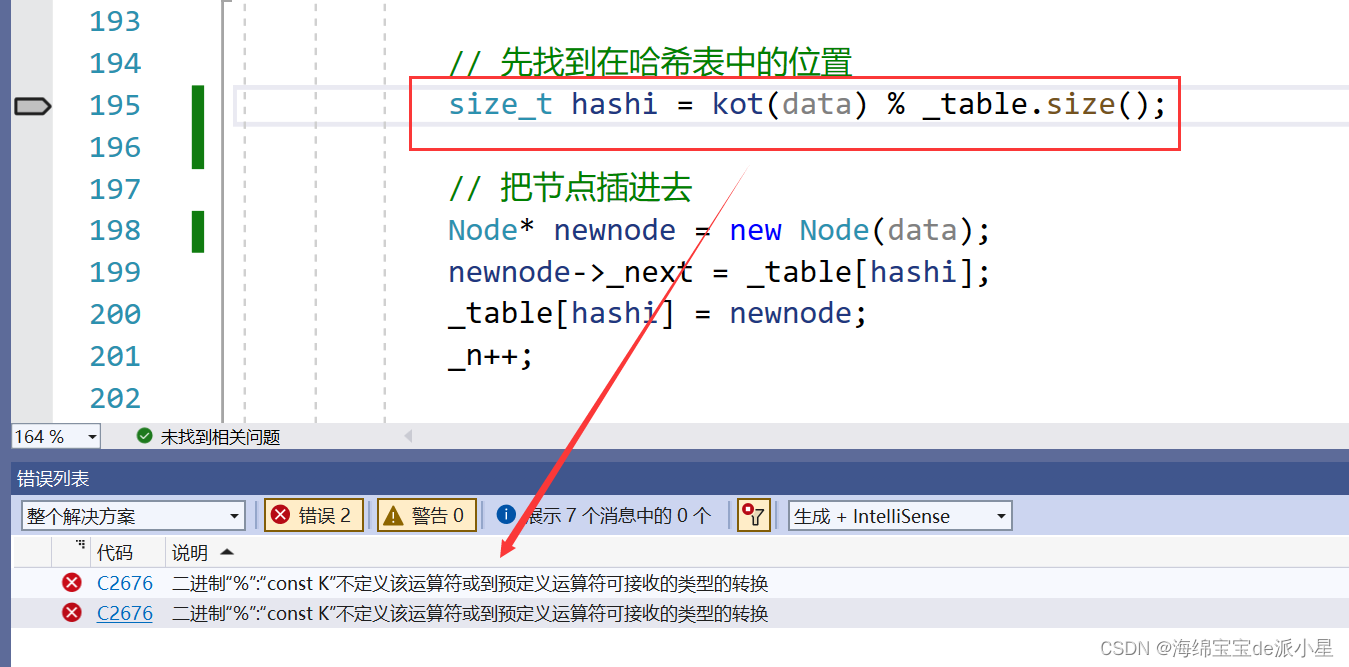
还是前面出现过的原因,因为这里的kot取出来的是第一个元素,但是第一个元素是string,string是不能参与运算的,因此这里要再套一层仿函数来解决string类的问题
最终实现
改造后的哈希表
#pragma once
#include <iostream>
#include <vector>
using namespace std;template <class T>
struct _HashT
{const T& operator()(const T& Key){return Key;}
};template<>
struct _HashT<string>
{size_t operator()(const string& Key){size_t sum = 0;for (auto e : Key){sum += e * 31;}return sum;}
};namespace opened_hashing
{// 定义节点信息template<class T>struct Node{Node(const T& data):_next(nullptr), _data(data){}Node* _next;T _data;};template<class K, class T, class KeyOfT, class Hash>class HashTable;template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>struct _iterator{typedef _iterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;typedef Node<T> Node;_iterator(Node* node, HashTable<K, T, KeyOfT, Hash>* pht, int hashi):_node(node), _pht(pht), _hashi(hashi){}_iterator(Node* node, const HashTable<K, T, KeyOfT, Hash>* pht, int hashi):_node(node), _pht(pht), _hashi(hashi){}Self operator++(){// 如果后面还有值,++就是到这个桶的下一个元素if (_node->_next){_node = _node->_next;}else{++_hashi;while (_hashi < _pht->_table.size()){if (_pht->_table[_hashi]){_node = _pht->_table[_hashi];break;}++_hashi;}if (_hashi == _pht->_table.size()){_node = nullptr;}}return *this;}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self& s) const{return _node != s._node;}Node* _node;int _hashi; // 现在位于哪个桶const HashTable<K, T, KeyOfT, Hash>* _pht; // 迭代器所在的哈希表};template<class K, class T, class KeyOfT, class Hash>class HashTable{template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend struct _iterator;typedef Node<T> Node;public:typedef _iterator<K, T, T&, T*, KeyOfT, Hash> iterator;typedef _iterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;// 构造函数HashTable():_n(0){_table.resize(10);}// 析构函数~HashTable(){//cout << endl << "*******************" << endl;//cout << "destructor" << endl;for (int i = 0; i < _table.size(); i++){//cout << "[" << i << "]->";Node* cur = _table[i];while (cur){Node* next = cur->_next;//cout << cur->_kv.first << " ";delete cur;cur = next;}//cout << endl;_table[i] = nullptr;}}// 迭代器iterator begin(){for (int i = 0; i < _table.size(); i++){if (_table[i]){return iterator(_table[i], this, i);}}return end();}iterator end(){return iterator(nullptr, this, -1);}const_iterator begin() const{for (int i = 0; i < _table.size(); i++){if (_table[i]){return const_iterator(_table[i], this, i);}}return end();}const_iterator end() const{return const_iterator(nullptr, this, -1);}// 插入元素bool insert(const T& data){KeyOfT kot;Hash ht;// 如果哈希表中有这个元素,就不插入了if (find(data)){return false;}// 扩容问题if (_n == _table.size()){HashTable newtable;int newsize = (int)_table.size() * 2;newtable._table.resize(newsize, nullptr);for (int i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 把哈希桶中的元素插入到新表中int newhashi = ht(kot(cur->_data)) % newsize;// 头插cur->_next = newtable._table[newhashi];newtable._table[newhashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable._table);}// 先找到在哈希表中的位置size_t hashi = ht(kot(data)) % _table.size();// 把节点插进去Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return true;}Node* find(const T& Key){KeyOfT kot;Hash ht;// 先找到它所在的桶int hashi = ht(kot(Key)) % _table.size();// 在它所在桶里面找数据Node* cur = _table[hashi];while (cur){if (cur->_data == Key){return cur;}cur = cur->_next;}return nullptr;}private:vector<Node*> _table;size_t _n;};
}
封装后的哈希结构
// set
#pragma once
#include "HashTable.h"
namespace myset
{template<class K, class Hash = _HashT<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};typedef typename opened_hashing::HashTable<K, K, SetKeyOfT, Hash>::const_iterator iterator;typedef typename opened_hashing::HashTable<K, K, SetKeyOfT, Hash>::const_iterator const_iterator;public:const_iterator begin() const{return _table.begin();}const_iterator end() const{return _table.end();}bool insert(const K& key){return _table.insert(key);}private:opened_hashing::HashTable<K, K, SetKeyOfT, Hash> _table;};
}// map
#pragma once#include "HashTable.h"namespace mymap
{template<class K, class V, class Hash = _HashT<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<const K, V>& key){return key.first;}};typedef typename opened_hashing::HashTable<K, pair<const K, V>, MapKeyOfT, Hash >::iterator iterator;typedef typename opened_hashing::HashTable<K, pair<const K, V>, MapKeyOfT, Hash >::const_iterator const_iterator;public:iterator begin(){return _table.begin();}iterator end(){return _table.end();}bool insert(const pair<const K, V>& key){return _table.insert(key);}private:opened_hashing::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _table;};
}
99%的人还看了
相似问题
- 〖大前端 - 基础入门三大核心之JS篇㊲〗- DOM改变元素节点的css样式、HTML属性
- CSS中常用的伪元素选择器
- XmlElement注解在Java的数组属性上,以产生多个相同的XML元素
- Web 自动化神器 TestCafe(二)—元素定位篇
- 代码随想录算法训练营第一天|数组理论基础,704. 二分查找,27. 移除元素
- 代码随想录算法训练营第五十九天 | LeetCode 739. 每日温度、496. 下一个更大元素 I
- JAXB:用XmlElement注解复杂类型的Java属性,来产生多层嵌套的xml元素
- Arcgis js Api日常天坑问题3——加载geojson图层,元素无属性
- 〖大前端 - 基础入门三大核心之JS篇㊳〗- DOM访问元素节点
- 力扣.82删除链表中的重复元素(java语言实现)
猜你感兴趣
版权申明
本文"C++:利用哈希表对unordered系列容器模拟实现":http://eshow365.cn/6-41149-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 蓝桥杯每日一题2023.11.20
- 下一篇: git提交时会将target也提交