已解决
动手学深度学习——循环神经网络的简洁实现(代码详解)
来自网友在路上 153853提问 提问时间:2023-11-18 20:14:33阅读次数: 53
最佳答案 问答题库538位专家为你答疑解惑
文章目录
- 循环神经网络的简洁实现
- 1. 定义模型
- 2. 训练与预测
循环神经网络的简洁实现
# 使用深度学习框架的高级API提供的函数更有效地实现相同的语言模型
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
1. 定义模型
构造一个具有256个隐藏单元的单隐藏层的循环神经网络层rnn_layer
# 构造一个具有256个隐藏单元的单隐藏层的循环神经网络层rnn_layer
num_hiddens =256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
使用张量初始化状态,形状为(隐藏层数,批量大小,隐藏单元数)
# 使用张量初始化状态,形状为(隐藏层数,批量大小,隐藏单元数)
state = torch.zeros((1, batch_size, num_hiddens))
state.shape

通过一个隐状态和一个输入,可以用更新后的隐状态计算输出。
# 通过一个隐状态和一个输入,可以用更新后的隐状态计算输出。
# rnn_layer的“输出”(Y)不涉及输出层的计算: 它是指每个时间步的隐状态,这些隐状态可以用作后续输出层的输入。
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
Y.shape, state_new.shape
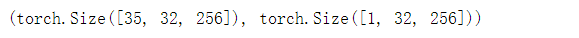 为一个完整的循环神经网络模型定义了一个RNNModel类,rnn_layer只包含隐藏的循环层,我们还需要创建一个单独的输出层。
为一个完整的循环神经网络模型定义了一个RNNModel类,rnn_layer只包含隐藏的循环层,我们还需要创建一个单独的输出层。
# 为一个完整的循环神经网络模型定义了一个RNNModel类
# rnn_layer只包含隐藏的循环层,我们还需要创建一个单独的输出层
#save
class RNNModel(nn.Module):"""循环神经网络模型"""def __init__(self, rnn_layer, vocab_size, **kwargs):super(RNNModel, self).__init__(**kwargs)self.rnn = rnn_layerself.vocab_size = vocab_sizeself.num_hiddens = self.rnn.hidden_size# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1if not self.rnn.bidirectional:self.num_directions = 1self.linear = nn.Linear(self.num_hiddens, self.vocab_size)else:self.num_directions = 2self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)def forward(self, inputs, state):X = F.one_hot(inputs.T.long(), self.vocab_size)X = X.to(torch.float32)Y, state = self.rnn(X, state)# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)# 它的输出形状是(时间步数*批量大小,词表大小)。output = self.linear(Y.reshape((-1, Y.shape[-1])))return output, statedef begin_state(self, device, batch_size=1):if not isinstance(self.rnn, nn.LSTM):# nn.GRU以张量作为隐状态return torch.zeros((self.num_directions * self.rnn.num_layers, batch_size, self.num_hiddens), device=device)else:# nn.LSTM以元组作为隐状态return (torch.zeros((self.num_directions * self.rnn.num_layers, batch_size, self.num_hiddens), device=device),torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device))
2. 训练与预测
在训练模型之前,基于一个具有随机权重的模型进行预测。
# 在训练模型之前,基于一个具有随机权重的模型进行预测。
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
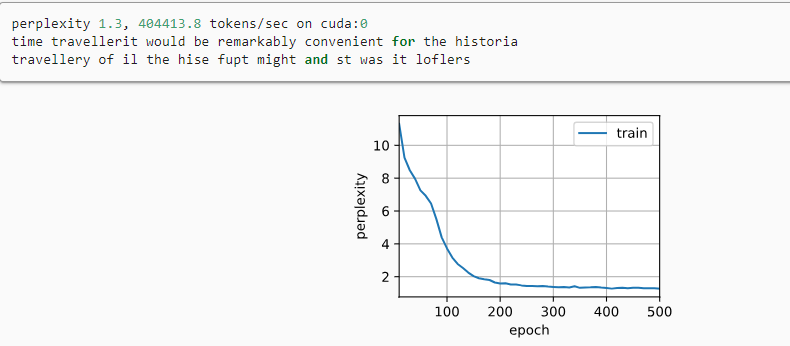
d2l.predict_ch8('time traveller', 10, net, vocab, device)

使用之前的超参数调用train_ch8,并且使用高级API训练模型
# 使用之前的超参数调用train_ch8,并且使用高级API训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
查看全文
99%的人还看了
相似问题
- 最新AIGC创作系统ChatGPT系统源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图,图片对话理解功能
- 思维模型 等待效应
- FinGPT:金融垂类大模型架构
- 人工智能基础_机器学习044_使用逻辑回归模型计算逻辑回归概率_以及_逻辑回归代码实现与手动计算概率对比---人工智能工作笔记0084
- Pytorch完整的模型训练套路
- Doris数据模型的选择建议(十三)
- python自动化标注工具+自定义目标P图替换+深度学习大模型(代码+教程+告别手动标注)
- ChatGLM2 大模型微调过程中遇到的一些坑及解决方法(更新中)
- Python实现WOA智能鲸鱼优化算法优化随机森林分类模型(RandomForestClassifier算法)项目实战
- 扩散模型实战(十一):剖析Stable Diffusion Pipeline各个组件
猜你感兴趣
版权申明
本文"动手学深度学习——循环神经网络的简洁实现(代码详解)":http://eshow365.cn/6-38641-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!