Yolov8模型训练报错:torch.cuda.OutOfMemoryError
最佳答案 问答题库658位专家为你答疑解惑
最近在使用自己的数据训练Yolov8模型的时候遇到了很多错误,下面将逐一解答。
问题报错
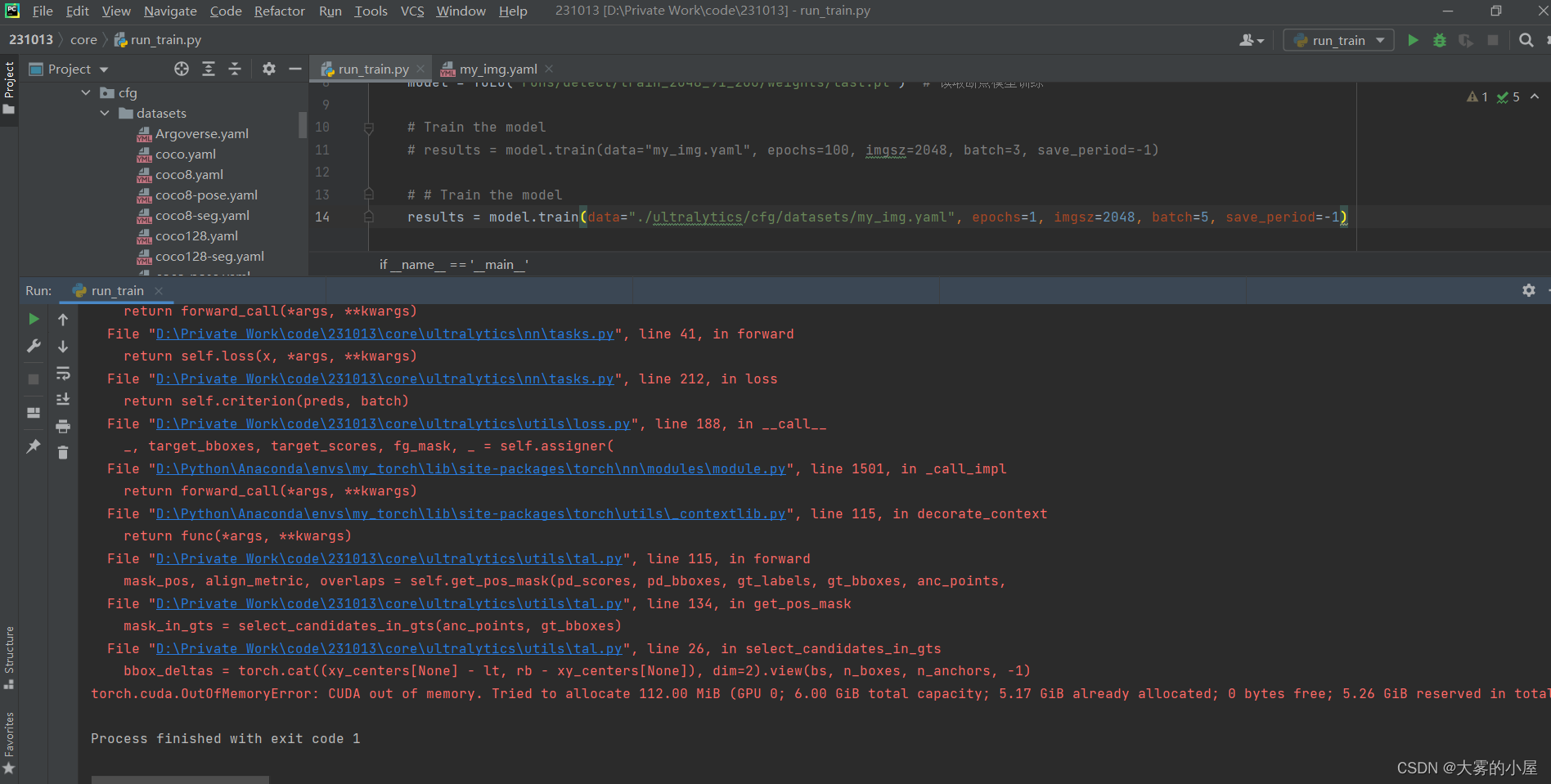
在训练过程中红字报错:torch.cuda.OutOfMemoryError: CUDA out of memory.
后面还会跟着一大段报错:
Tried to allocate XXX MiB (GPU 0; XXX GiB total capacity; XXX GiB already allocated; 0 bytes free; XXX GiB reserved in total by PyTorch)
If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation.
See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
报错信息如下图:
原因分析
其实这是因为训练时读取的图像数据太大,超出了GPU的显存。
可以看到我这台电脑是GTX2060,显存6G,读取的图像信息已经到了5.17G,无法再进行模型训练。
解决方案
在遇到此类问题时,我们可以调整两个部分的代码。
首先,yolov8的模型训练代码如下:
from core.ultralytics import YOLO
model = YOLO("runs/detect/train_2048_91_200/weights/last.pt") # 读取断点模型训练# # Train the model
results = model.train(data="./ultralytics/cfg/datasets/my_img.yaml", epochs=1, imgsz=2048, batch=5, save_period=-1)1、调整imgsz
此处,我们可以修改:model.train()方法中的,imgsz这个参数。
可以看到博主这边使用的是2024分辨率进行训练,主要原因还是因为项目的图像较大,为5120*5120图像,同时需要做小目标识别。因此设置的比较大。
但是大家可以根据自己的实际情况来调整这个参数的大小,如果本身需要检测的目标比较大,那大家可以尝试将此参数调小一些。
2、调整batch
一般来说显存超了,大多时候会选择调整batch这个参数,虽然调整后会一定程度影响模型的泛化能力,容易导致过拟合,但在现有条件下两害相权取其轻,只能调小这个参数了。
调整batch后
博主这边选择不调整imgsz,原因上面已经说了。
将batch调整至4之后,再次训练。
情况如下:
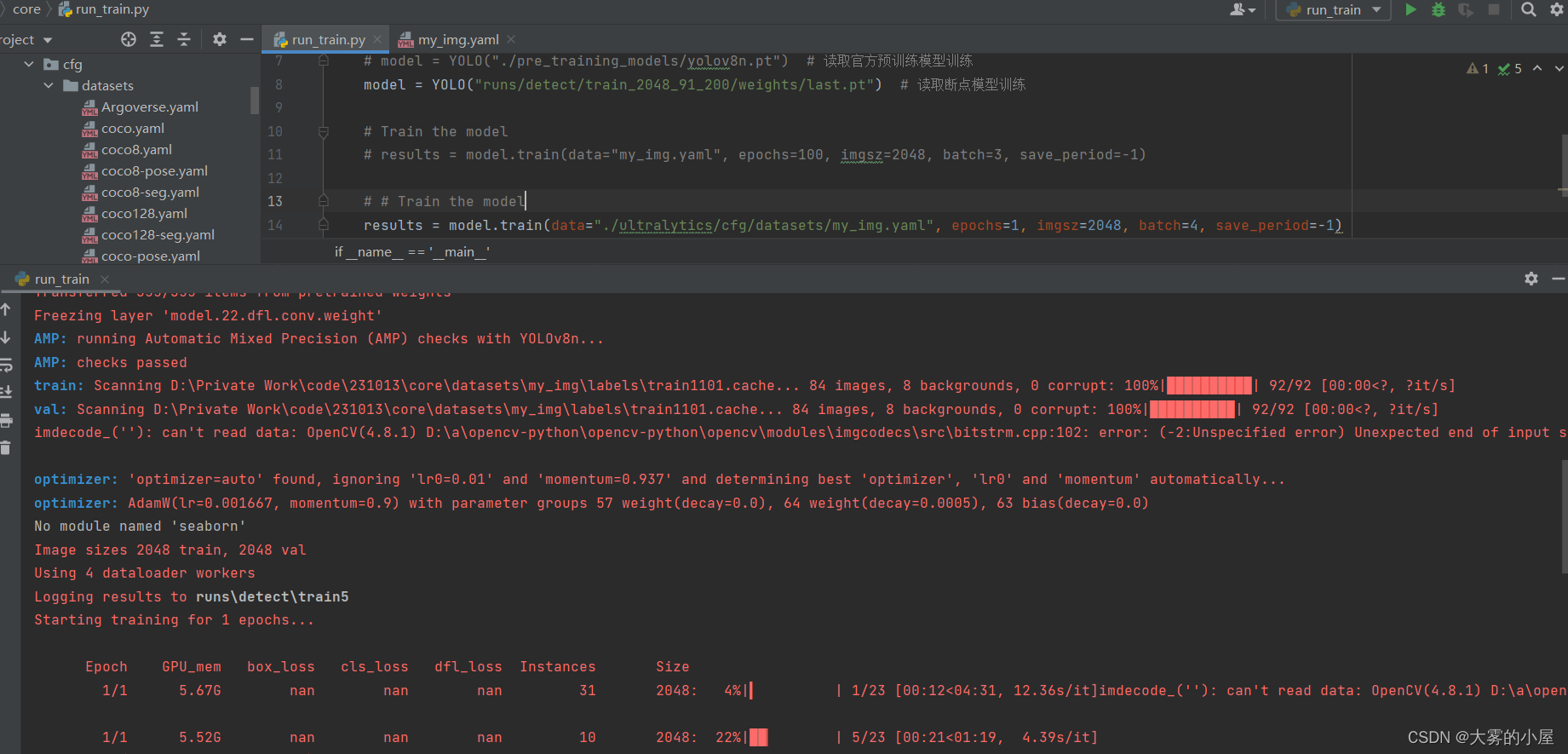
完美跑通!
99%的人还看了
相似问题
- conda创建pytorch环境报错
- Python通过selenium调用IE11浏览器报错解决方法
- kafka本地安装报错
- 【BUG】第一次创建vue3+vite项目启动报错Error: Cannot find module ‘worker_threads‘
- git 构建报错
- Docker build报错总结,版本过新大避雷!
- Mongodb3.4升级高版本mongoTemplate.executeCommand报错The cursor option is required
- duplicate复制数据库单个数据文件复制失败报错rman-03009 ora-03113
- 安装第三方包报错 error: Microsoft Visual C++ 14.0 or greater is required——解决办法
- 邮件|gitpushgithub报错|Lombok注解
猜你感兴趣
版权申明
本文"Yolov8模型训练报错:torch.cuda.OutOfMemoryError":http://eshow365.cn/6-37171-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!