李开复创业公司零一万物开源迄今为止最长上下文大模型:Yi-6B和Yi-34B,支持200K超长上下文
最佳答案 问答题库1108位专家为你答疑解惑
本文来自DataLearnerAI官方网站:李开复创业公司零一万物开源迄今为止最长上下文大模型:Yi-6B和Yi-34B,支持200K超长上下文 | 数据学习者官方网站(Datalearner)![]() https://www.datalearner.com/blog/1051699285770532
https://www.datalearner.com/blog/1051699285770532
零一万物(01.AI)是由李开复在2023年3月份创办的一家大模型创业企业,并在2023年6月份正式开始运营。在2023年11月6日,零一万物开源了4个大语言模型,包括Yi-6B、Yi-6B-200K、Yi-34B、Yi-34B-200k。模型在MMLU的评分上登顶,最高支持200K超长上下文输入,获得了社区的广泛关注。

- Yi-6B、Yi-34B模型简介
- Yi-6B和Yi-34B模型的训练细节
- Yi-6B和Yi-34B的开源情况
Yi-6B、Yi-34B模型简介
这是李开复亲自担任CEO的一家企业,可以说相当地重视。本次发布的模型包括4个:
注意,这里的4K/32K表示模型本身在4K的序列上进行训练,但是在推理阶段可以扩展到32K。
这四个模型最大的特点是最高支持200K的上下文长度,是目前全球支持的最长的上下文大模型。
此外,这四个模型的表现也十分好,在MMLU的语言理解评测上得分76.3,是目前为止全球最高的开源大模型(预训练结果测试结果,不包含特殊微调的模型):
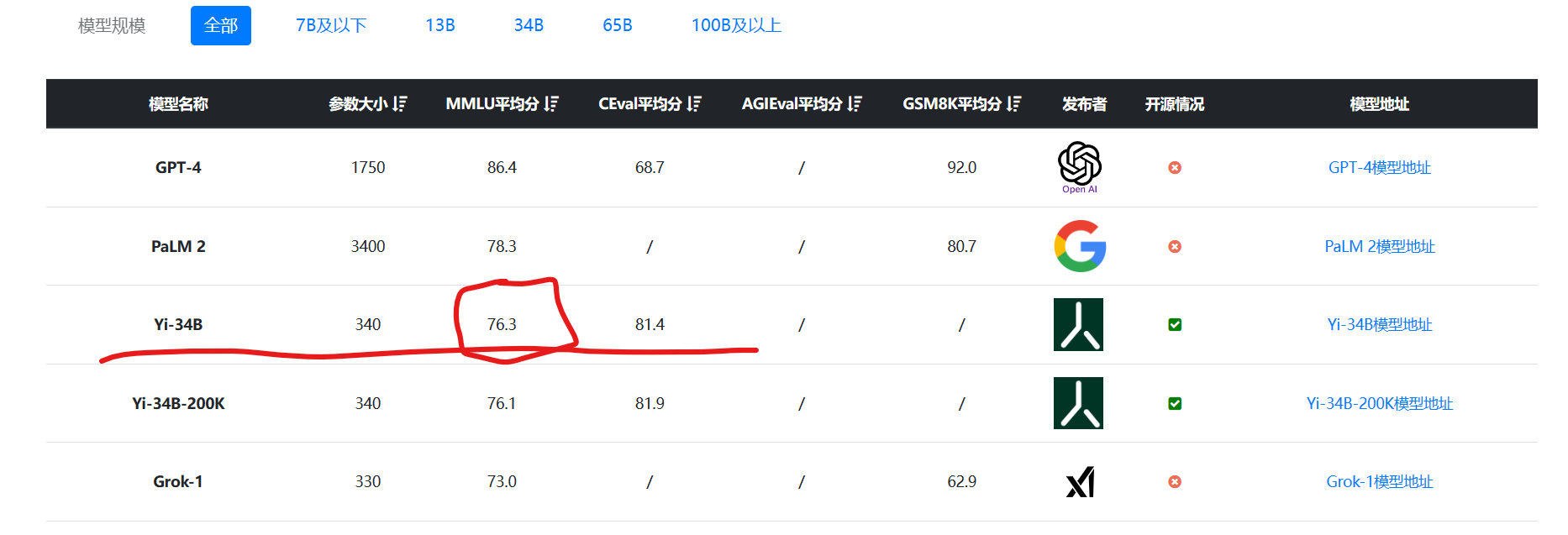
数据来源:大模型综合评测对比 | 当前主流大模型在各评测数据集上的表现总榜单 | 数据学习 (DataLearner)
由于该模型也在HuggingFace的OpenLLM Leaderboard上提交了数据,也引起了国外很多人的关注。
Yi-6B和Yi-34B模型的训练细节
关于Yi-6B和Yi-34B的模型训练细节,官方没有透露,只说明了这两个模型在多语言语料上训练,语料的数据达到3万亿tokens。官方说明这些模型是双语模型,支持中文和英文。
6B的模型可以在消费级显卡上运行。而34B的模型是可以出现涌现能力的最低参数规模,这可能也是发布这两个模型的初衷。
Yi-6B和Yi-34B的开源情况
模型本身的GitHub代码采用Apache2.0开源方式,但是模型的预训练结果则是自有开源协议,个人和科研完全免费使用,商用需要获得授权申请,但是申请免费。
模型的其它信息参考DataLearner信息卡:
- Yi-6B : Yi-6B(Yi-6B)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习 (DataLearner)
- Yi-6B-200K:Yi-6B-200K(Yi-6B-200K)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习 (DataLearner)
- Yi-34B :Yi-34B(Yi-34B)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习 (DataLearner)
- Yi-34B-200K: Yi-34B-200K(Yi-34B-200K)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习 (DataLearner)
99%的人还看了
相似问题
- 最新AIGC创作系统ChatGPT系统源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图,图片对话理解功能
- 思维模型 等待效应
- FinGPT:金融垂类大模型架构
- 人工智能基础_机器学习044_使用逻辑回归模型计算逻辑回归概率_以及_逻辑回归代码实现与手动计算概率对比---人工智能工作笔记0084
- Pytorch完整的模型训练套路
- Doris数据模型的选择建议(十三)
- python自动化标注工具+自定义目标P图替换+深度学习大模型(代码+教程+告别手动标注)
- ChatGLM2 大模型微调过程中遇到的一些坑及解决方法(更新中)
- Python实现WOA智能鲸鱼优化算法优化随机森林分类模型(RandomForestClassifier算法)项目实战
- 扩散模型实战(十一):剖析Stable Diffusion Pipeline各个组件
猜你感兴趣
版权申明
本文"李开复创业公司零一万物开源迄今为止最长上下文大模型:Yi-6B和Yi-34B,支持200K超长上下文":http://eshow365.cn/6-36754-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 识典百科取代快懂百科,如何在识典百科创建词条?
- 下一篇: 《GPT与AI助手:技术进步与就业前景》