已解决
scrapy案例教程
来自网友在路上 154854提问 提问时间:2023-11-08 22:53:41阅读次数: 54
最佳答案 问答题库548位专家为你答疑解惑
文章目录
- 1 scrapy简介
- 2 创建项目
- 3 自定义初始化请求url
- 4 定义item
- 5 定义管道
1 scrapy简介
- scrapy常用命令
|命令 | 格式 |说明|
|–|–|–|
|startproject |scrapy startproject <项目名> |创建一个新项目|
|genspider| scrapy genspider <爬虫文件名> <域名> |新建爬虫文件。
|runspider| scrapy runspider <爬虫文件> |运行一个爬虫文件,不需要创建项目。
|crawl| scrapy crawl |运行一个爬虫项目,必须要创建项目。
|list |scrapy list |列出项目中所有爬虫文件。
|view| scrapy view <url地址>| 从浏览器中打开 url 地址。
|shell| csrapy shell <url地址> |命令行交互模式。
|settings |scrapy settings |查看当前项目的配置信息。 - 项目的目录树结构

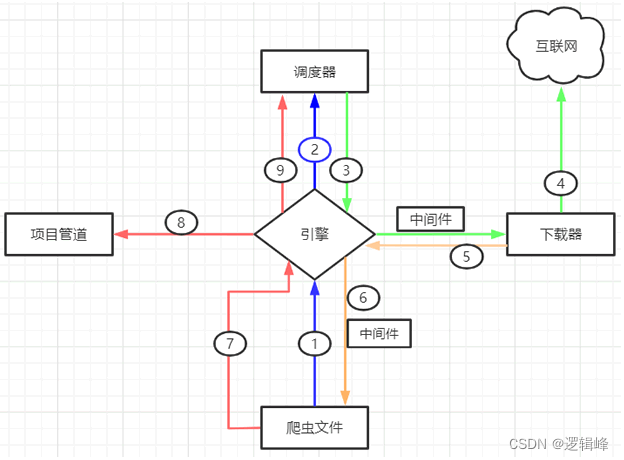
- Scrapy 五大组件
- 两大中间件
- 下载器中间件,位于引擎和下载器之间,主要用来包装 request 请求头,比如 UersAgent、Cookies 和代理 IP 等
- 蜘蛛中间件,位于引擎与爬虫文件之间,它主要用来修改响应对象的属性。
- 工作流程图
2 创建项目
# 创建项目
scrapy startproject Medical
# 进入项目
cd Medical
# 创建爬虫文件
scrapy genspider medical www.baidu.com
3 自定义初始化请求url
import scrapy
import json
from scrapy.http import Response
from Medical.items import MedicalItem
from tqdm import tqdm'''
具体的爬虫程序
'''class MedicalSpider(scrapy.Spider):name = "medical"allowed_domains = ["beian.cfdi.org.cn"]# start_urls = ["https://beian.cfdi.org.cn/CTMDS/pub/PUB010100.do?method=handle05&_dt=20231101162330"]# 重写第一次请求处理函数def start_requests(self):start_url = 'https://www.baidu.com/CTMDS/pub/PUB010100.do?method=handle05&_dt=20231101162330'# 发送post请求data = {'pageSize': '1353','curPage': '1',}yield scrapy.FormRequest(url=start_url, formdata=data, callback=self.parse)def parse(self, response):# 转换为jsonjsonRes = json.loads(response.body)# 查看响应状态码status = jsonRes['success']# 如果状态为Trueif status:# 获取数据dataList = jsonRes['data']# 调用详细方法,发起请求(循环发起)for row in tqdm(dataList,desc='爬取进度'):# 请求详情页urlurlDetail = f"https://www.baidu.com/CTMDS/pub/PUB010100.do?method=handle04&compId={row['companyId']}"# 发起请求yield scrapy.Request(url=urlDetail, callback=self.parseDetail, meta={'row': row})def parseDetail(self, response: Response):# new 一个MedicalItem实例item = MedicalItem()# 获取上次请求的数据源row = response.meta['row']item['companyId'] = row['companyId']item['linkTel'] = row['linkTel']item['recordNo'] = row['recordNo']item['areaName'] = row['areaName']item['linkMan'] = row['linkMan']item['address'] = row['address']item['compName'] = row['compName']item['recordStatus'] = row['recordStatus']item['cancelRecordTime'] = row.get('cancelRecordTime', '')# 获取备案信息divTextList = response.xpath("//div[@class='col-md-8 textlabel']/text()").extract()# 去空白divtextList = [text.strip() for text in divTextList]compLevel = ''if len(divtextList) > 2:compLevel = divtextList[2]recordTime = ''if len(divtextList) > 5:recordTime = divtextList[6]item['compLevel'] = compLevelitem['recordTime'] = recordTime# 获取其他机构地址divListOther = response.xpath("//div[@class='col-sm-8 textlabel']/text()").extract()# 去空白divtextListOther = [text.strip() for text in divListOther]otherOrgAdd = ','.join(divtextListOther)item['otherOrgAdd'] = otherOrgAdd# 获取备案专业和主要研究者信息trList = response.xpath("//table[@class='table table-striped']/tbody/tr")tdTextList = [tr.xpath("./td/text()").extract() for tr in trList]item['tdTextList'] = tdTextList# 返回itemyield item
4 定义item
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapyclass MedicalItem(scrapy.Item):# define the fields for your item here like:# 省份/地区areaName = scrapy.Field()# 公司idcompanyId = scrapy.Field()# 公司名称compName = scrapy.Field()# 公司等级compLevel = scrapy.Field()# 联系人linkMan = scrapy.Field()# 联系电话linkTel = scrapy.Field()# 备案号recordNo = scrapy.Field()# 地址address = scrapy.Field()# 备案状态recordStatus = scrapy.Field()# 取消备案时间cancelRecordTime = scrapy.Field()# 备案时间recordTime = scrapy.Field()# 其他机构地址otherOrgAdd = scrapy.Field()# 子表详情(矩阵)tdTextList = scrapy.Field()
5 定义管道
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysqlfrom Medical.items import MedicalItemclass MedicalPipeline:# 开始def open_spider(self, spider):# 初始化数据库self.db = pymysql.connect(host='localhost',port=3306,user='root',password='logicfeng',database='test2')# 创建游标对象self.cursor = self.db.cursor()def process_item(self, item, spider):companyId = item['companyId']linkTel = item['linkTel']recordNo = item['recordNo']areaName = item['areaName']linkMan = item['linkMan']address = item['address']compName = item['compName']recordStatus = item['recordStatus']cancelRecordTime = item.get('cancelRecordTime', '')compLevel = item.get('compLevel', '')recordTime = item.get('recordTime', '')otherOrgAdd = item.get('otherOrgAdd', '')tdTextList = item['tdTextList']sql1 = "insert INTO medical_register(company_id,area_name,record_no,comp_name,address,link_man,link_tel,record_status,comp_level,record_time,cancel_record_time,other_org_add) "sql2 = f"values('{companyId}','{areaName}','{recordNo}','{compName}','{address}','{linkMan}','{linkTel}','{recordStatus}','{compLevel}','{recordTime}','{cancelRecordTime}','{otherOrgAdd}')"sql3 = sql1 + sql2# 执行sqlself.cursor.execute(sql3)# 提交self.db.commit()for tdText in tdTextList:tdText.insert(0,companyId)# 插入数据库sql4 = "insert into medical_register_sub (company_id,professional_name,principal_investigator,job_title) values(%s,%s,%s,%s)"self.cursor.execute(sql4, tdText)# 提交到数据库self.db.commit()return itemdef close_spider(self, spider):self.cursor.close()self.db.close()print("关闭数据库!")
查看全文
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"scrapy案例教程":http://eshow365.cn/6-35633-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!