已解决
python爬虫(数据获取——selenium)
来自网友在路上 170870提问 提问时间:2023-11-06 16:04:41阅读次数: 70
最佳答案 问答题库708位专家为你答疑解惑
环境测试
from selenium import webdriverchromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
driver = webdriver.Chrome()url = "https://www.xinpianchang.com/discover/article?from=navigator"
driver.get(url)driver.close()常用API
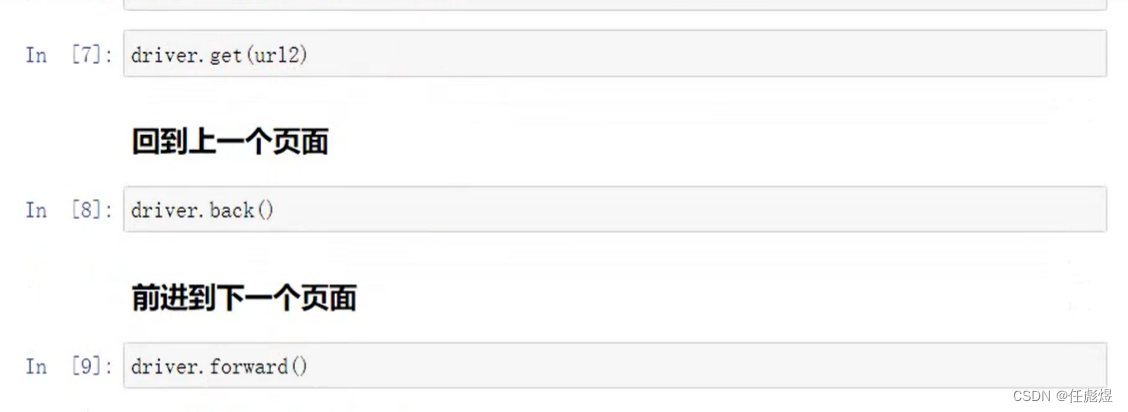
操作页面元素

from selenium import webdriver
import jsonchromedriver_path = r""
driver = webdriver.Chrome()
url = "https://passport.xinpianchang.com/login?redirect_uri=https%3A%2F%2Fwww.xinpianchang.com%2Fuser%2F14226548&mode=quick&type=phone"
driver.get(url)
with open(r"C:\Users\lenovo\Desktop\a.txt", 'r', encoding='utf-8') as rStream:read = rStream.read()replace = read.replace("'", '"').replace("True", "true").replace("False", "false").replace("Null", "null")
with open(r"", 'w', encoding='utf-8') as wStream:write = wStream.write(replace)with open(r"", 'r', encoding='utf-8') as rStream:read = rStream.read()import jsonloads = json.loads(read)
print(loads)
for c in loads:driver.add_cookie(c)driver.get("https://www.xinpianchang.com/")
查看全文
99%的人还看了
相似问题
- 〖大前端 - 基础入门三大核心之JS篇㊲〗- DOM改变元素节点的css样式、HTML属性
- CSS中常用的伪元素选择器
- XmlElement注解在Java的数组属性上,以产生多个相同的XML元素
- Web 自动化神器 TestCafe(二)—元素定位篇
- 代码随想录算法训练营第一天|数组理论基础,704. 二分查找,27. 移除元素
- 代码随想录算法训练营第五十九天 | LeetCode 739. 每日温度、496. 下一个更大元素 I
- JAXB:用XmlElement注解复杂类型的Java属性,来产生多层嵌套的xml元素
- Arcgis js Api日常天坑问题3——加载geojson图层,元素无属性
- 〖大前端 - 基础入门三大核心之JS篇㊳〗- DOM访问元素节点
- 力扣.82删除链表中的重复元素(java语言实现)
猜你感兴趣
版权申明
本文"python爬虫(数据获取——selenium)":http://eshow365.cn/6-33759-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 为什么大家会选择通配符SSL证书?
- 下一篇: vue开发环境搭建部署(mac版)