Elasticsearch:使用 ES|QL
最佳答案 问答题库658位专家为你答疑解惑
在我之前的文章 “Elasticsearch:ES|QL 查询语言简介”,我对 ES|QL 做了一个简单的介绍。在今天的文章中,我们来描述如何使用 ES|QL。
REST API
这个用来返回 ES|QL (Elasticsearch qyery language) 的查询结果。它具有如下的格式:
POST /_query
{"query": """FROM library| EVAL year = DATE_TRUNC(1 YEARS, release_date)| STATS MAX(page_count) BY year| SORT year| LIMIT 5"""
}请求
POST _query前提条件
- 如果启用了 Elasticsearch 安全功能,你必须对你搜索的数据流、索引或别名具有读取索引权限。
请求参数
(可选,字符串)响应的格式。 有关有效值,请参阅如下的响应格式。
你还可以使用 Accept HTTP 标头指定格式。 如果你同时指定此参数和 Accept HTTP 标头,则此参数优先。
响应格式
ES|QL 可以以以下人类可读和二进制格式返回数据。 你可以通过在 URL 中指定格式参数或设置 Accept 或 Content-Type HTTP 标头来设置格式。
注意:URL 参数优先于 HTTP 标头。 如果两者均未指定,则响应将以与请求相同的格式返回。
format
HTTP header
Description
Human readable
csv
text/csv
Comma-separated values
json
application/json
JSON (JavaScript Object Notation) human-readable format
tsv
text/tab-separated-values
Tab-separated values
txt
text/plain
CLI-like representation
yaml
application/yaml
YAML (YAML Ain’t Markup Language) human-readable format
Binary
cbor
application/cbor
Concise Binary Object Representation
smile
application/smile
Smile binary data format similar to CBOR
csv 格式接受格式化 URL 查询属性分隔符,该属性指示应使用哪个字符来分隔 CSV 值。 默认为逗号 (,),并且不能采用以下任何值:双引号 (")、回车符 (\r) 和换行符 (\n)。也不能使用制表符 (\t)。请改用 tsv 格式。
请求 body
响应 body
(对象数组)搜索结果的列标题。 每个对象都是一列。
columns 对象的属性
- name(字符串)列的名称。
- type(字符串)列的数据类型。
实例
总览
ES|QL 查询 API 接受查询参数中的 ES|QL 查询字符串,运行它并返回结果。 例如:
POST /_query?format=txt
{"query": "FROM library | KEEP author, name, page_count, release_date | SORT page_count DESC | LIMIT 5"
}上面搜索的结果为:
author | name | page_count | release_date
-----------------+--------------------+---------------+------------------------
Peter F. Hamilton|Pandora's Star |768 |2004-03-02T00:00:00.000Z
Vernor Vinge |A Fire Upon the Deep|613 |1992-06-01T00:00:00.000Z
Frank Herbert |Dune |604 |1965-06-01T00:00:00.000Z
Alastair Reynolds|Revelation Space |585 |2000-03-15T00:00:00.000Z
James S.A. Corey |Leviathan Wakes |561 |2011-06-02T00:00:00.000ZKibana 控制台
如果你使用 Kibana 控制台(强烈推荐),请在创建查询时利用三引号 """。这不仅会自动转义查询字符串内的双引号 ("),而且还支持多行请求:
POST /_query?format=txt
{"query": """FROM library| KEEP author, name, page_count, release_date| SORT page_count DESC| LIMIT 5"""
}使用 Elasticsearch Query DSL 进行过滤
在过滤器参数中指定 Query DSL 查询以过滤运行 ES|QL 查询的文档集。
POST /_query?format=txt
{"query": """FROM library| KEEP author, name, page_count, release_date| SORT page_count DESC| LIMIT 5""","filter": {"range": {"page_count": {"gte": 100,"lte": 200}}}
}返回:
author | name | page_count | release_date
---------------+------------------------------------+---------------+------------------------
Douglas Adams |The Hitchhiker's Guide to the Galaxy|180 |1979-10-12T00:00:00.000Z列结果 - columnar results
默认情况下,ES|QL 以行形式返回结果。 例如,FROM 将每个单独的文档作为一行返回。 对于 json、yaml、cbor 和 smile 格式,ES|QL 可以以列方式返回结果,其中一行代表结果中所有列的值。
POST /_query?format=json
{"query": """FROM library| KEEP author, name, page_count, release_date| SORT page_count DESC| LIMIT 5""","columnar": true
}返回:
{"columns": [{"name": "author", "type": "text"},{"name": "name", "type": "text"},{"name": "page_count", "type": "integer"},{"name": "release_date", "type": "date"}],"values": [["Peter F. Hamilton", "Vernor Vinge", "Frank Herbert", "Alastair Reynolds", "James S.A. Corey"],["Pandora's Star", "A Fire Upon the Deep", "Dune", "Revelation Space", "Leviathan Wakes"],[768, 613, 604, 585, 561],["2004-03-02T00:00:00.000Z", "1992-06-01T00:00:00.000Z", "1965-06-01T00:00:00.000Z", "2000-03-15T00:00:00.000Z", "2011-06-02T00:00:00.000Z"]]
}将参数传递给查询
通过将值集成到查询字符串本身,可以将值(例如条件的值)传递给 “内联(inline)” 查询:
POST /_query
{"query": """FROM library| EVAL year = DATE_EXTRACT("year", release_date)| WHERE page_count > 300 AND author == "Frank Herbert"| STATS count = COUNT(*) by year| WHERE count > 0| LIMIT 5"""
}为了避免任何黑客攻击或代码注入的尝试,请在单独的参数列表中提取值。 在每个参数的查询字符串中使用问号占位符 (?):
POST /_query
{"query": """FROM library| EVAL year = DATE_EXTRACT("year", release_date)| WHERE page_count > ? AND author == ?| STATS count = COUNT(*) by year| WHERE count > ?| LIMIT 5""","params": [300, "Frank Herbert", 0]
}在 Kibana 中使用 ES|QL
你可以在 Kibana 中使用 ES|QL 来查询和聚合数据、创建可视化并设置警报。
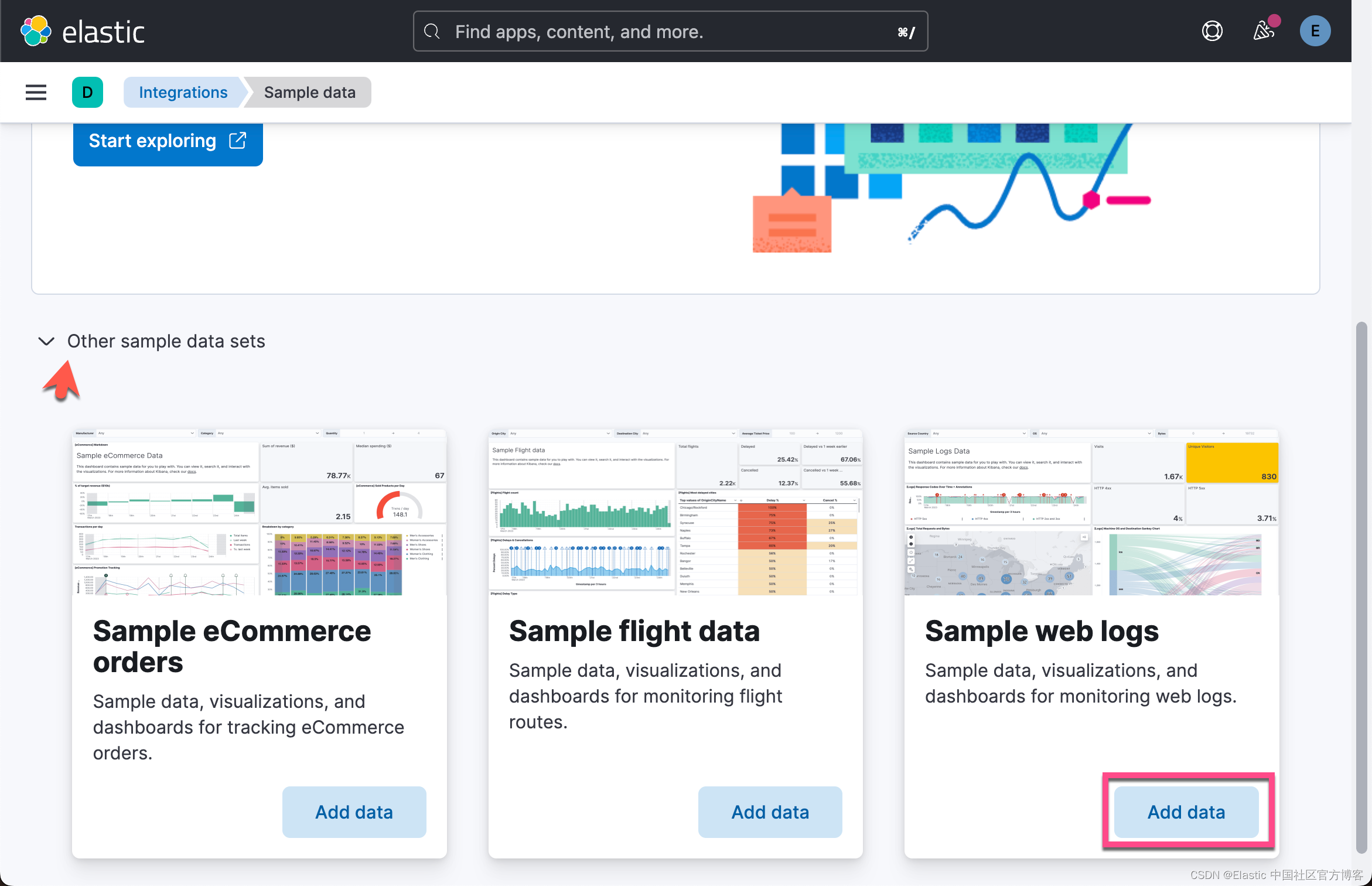
本指南向你展示如何在 Kibana 中使用 ES|QL。 要执行查询,请加载 “Sample Web 日志” 示例数据集,方法是单击来自 Kibana Home 的 “Try sample data”,选择 “Other sample data sets”,然后单击 “Sample web logs”卡上的 “Add data”。
ES|QL 入门
要开始在 Discover 中使用 ES|QL,请打开主菜单并选择 Discover。 接下来,从数据视图菜单中选择 Try ES|QL。
可以使用高级设置中的 discovery:enableESQL 设置来启用和禁用从数据视图菜单中选择 ES|QL 的功能。
查询栏
切换到 ES|QL 模式后,查询栏会显示示例查询。 例如:
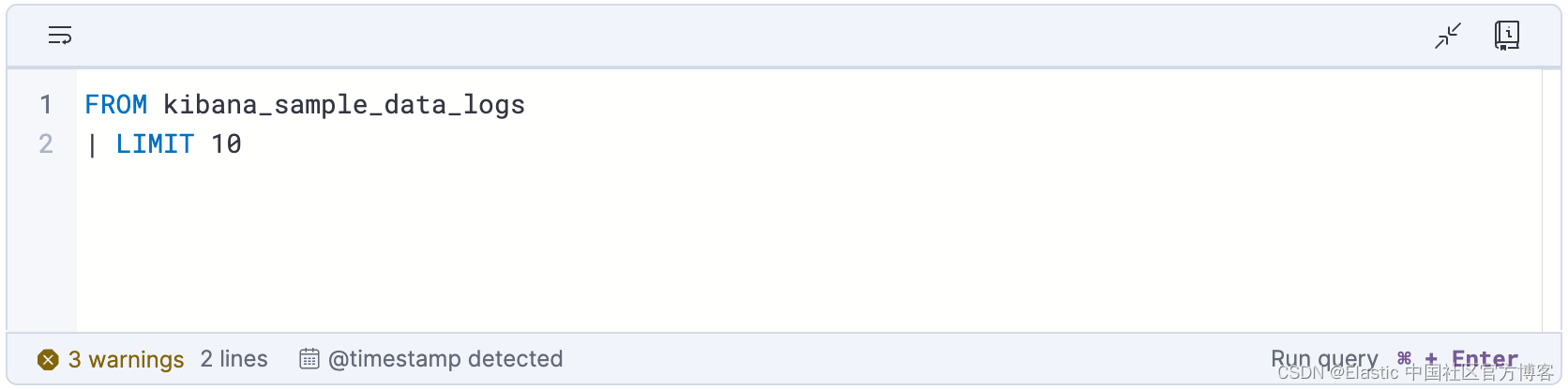
from kibana_sample_data_logs | limit 10每个查询都以源命令开始。 在此查询中,源命令是 FROM。 FROM 从数据流、索引或别名中检索数据。 在此示例中,数据是从 kibana_sample_data_logs 检索的。
源命令后面可以跟一个或多个处理命令。 在该查询中,处理命令是 LIMIT。 LIMIT 限制检索的行数。
提示:单击帮助图标
(esql 图标帮助)可打开所有命令和功能的产品内参考文档。
为了更轻松地编写查询,自动完成功能会提供包含可能的命令和功能的建议:
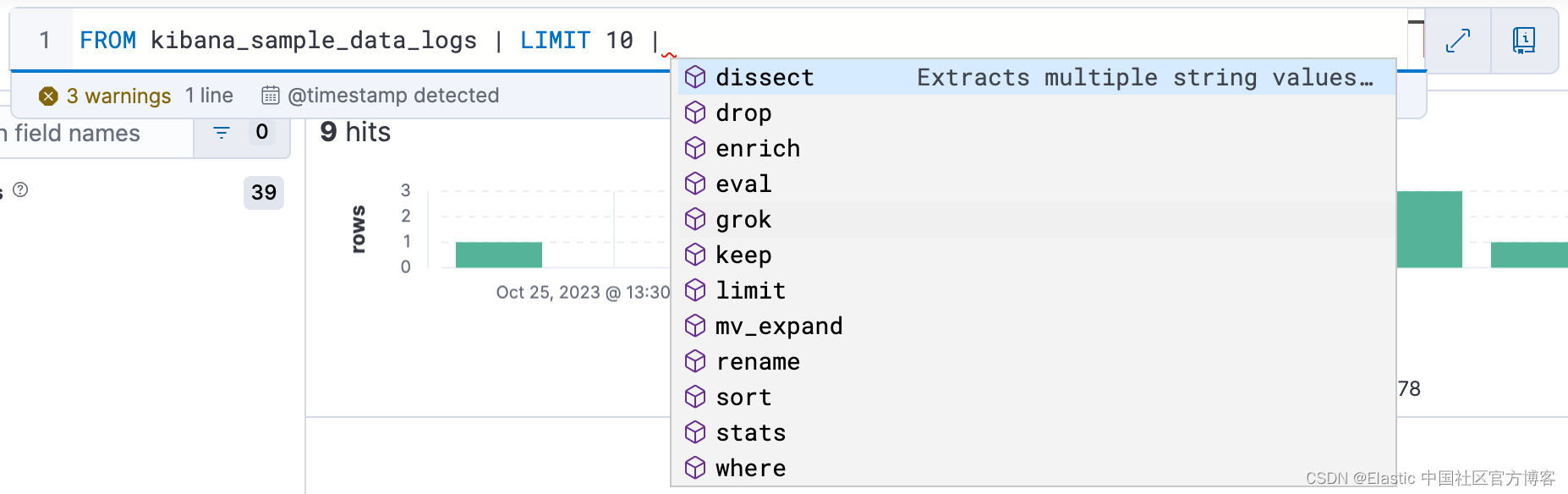
注意:ES|QL 关键字不区分大小写。 以下查询与前一个查询相同:
FROM kibana_sample_data_logs | LIMIT 10
展开查询栏
为了便于阅读,你可以将每个处理命令另起一行。 以下查询与前一个查询相同:
FROM kibana_sample_data_logs
| LIMIT 10为了更方便地编写多行查询,请单击双头箭头按钮 ![]() (esql 图标展开查询栏)来展开查询栏:
(esql 图标展开查询栏)来展开查询栏:
要返回紧凑查询栏,请单击最小化编辑器按钮 ![]() (esql 图标最小化查询栏)。
(esql 图标最小化查询栏)。
警告
查询可能会导致警告,例如在查询不受支持的字段类型时。 发生这种情况时,查询栏中会显示警告符号。 要查看详细警告,请展开查询栏,然后单击 warnings。
结果表
对于示例查询,结果表显示 10 行。 省略 LIMIT 命令,结果表默认最多 500 行。 使用 LIMIT,你可以将限制增加到最多 10,000 行。
注意:10,000 行限制仅适用于查询检索并显示在 Discover 中的行数。 任何查询或聚合都在完整数据集上运行。
每行显示示例查询的两列:包含 @timestamp 字段的列和包含完整文档的列。 要显示文档中的特定字段,请使用 KEEP 命令:
FROM kibana_sample_data_logs
| KEEP @timestamp, bytes, geo.dest要将所有字段显示为单独的列,请使用 KEEP *:
FROM kibana_sample_data_logs
| KEEP *注意:Discover 中的最大列数为 50。如果查询返回超过 50 列,Discover 只显示前 50 列。
排序
要对其中一列进行排序,请单击要排序的列名称并选择排序顺序。 请注意,这执行客户端排序。 它仅对查询检索到的行进行排序,由于(隐式)限制,这些行可能不是完整的数据集。 要对完整数据集进行排序,请使用 SORT 命令:
FROM kibana_sample_data_logs
| KEEP @timestamp, bytes, geo.dest
| SORT bytes DESC时间过滤
要显示指定时间范围内的数据,请使用 time filter。 仅当你查询的索引具有名为 @timestamp 的字段时,才会启用时间过滤器。
如果你的索引没有名为 @timestamp 的时间戳字段,你可以使用 WHERE 命令和 NOW 函数限制时间范围。 例如时间戳字段名为 timestamp,查询最近15分钟的数据:
FROM kibana_sample_data_logs
| WHERE timestamp > NOW() - 15minutes分析和可视化数据
Discover 在查询栏和结果表之间显示日期直方图可视化。 如果你正在查询的索引不包含 @timestamp 字段,则不会显示直方图。
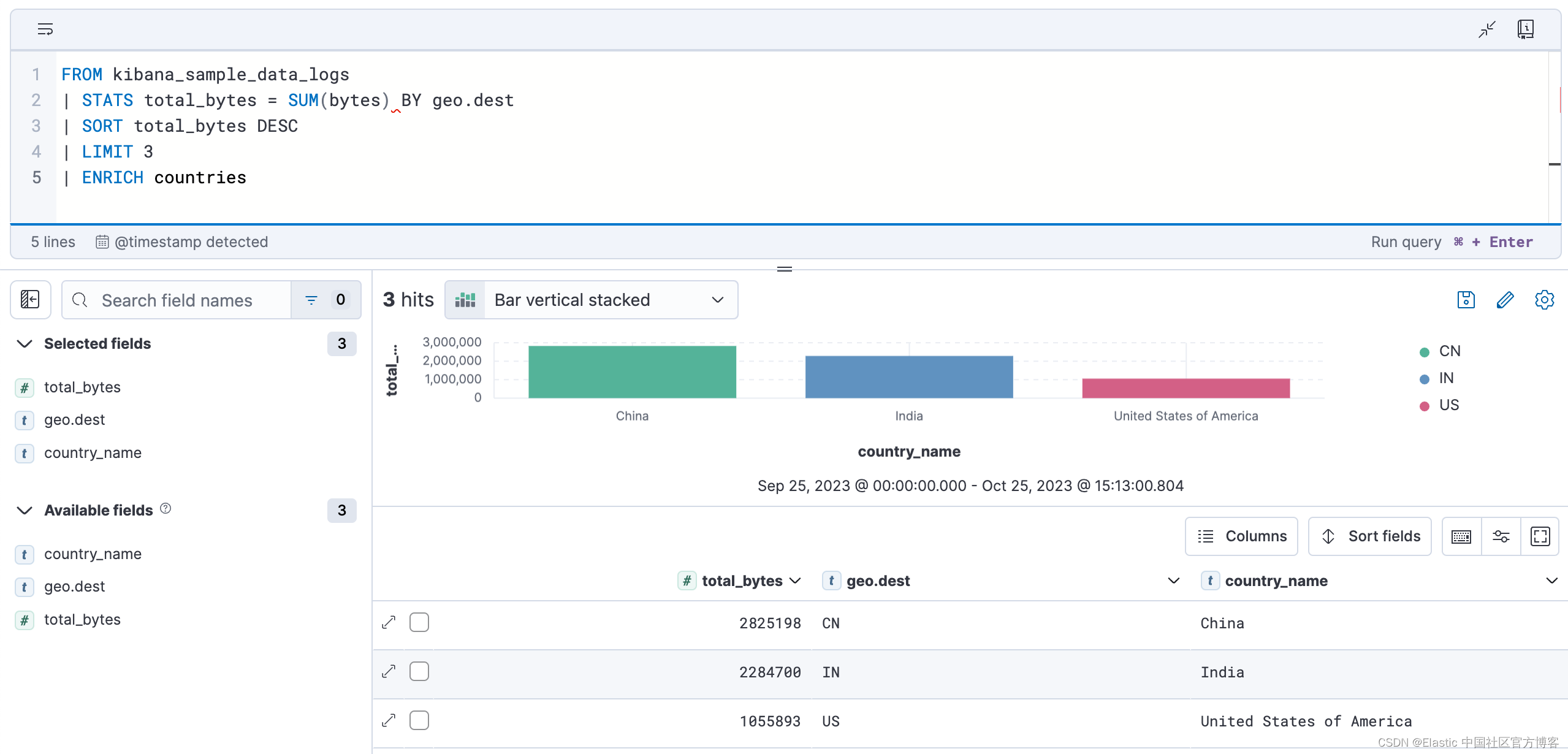
可视化适应查询。 查询的性质决定了可视化的类型。 例如,此查询聚合每个目标国家/地区的总字节数:
FROM kibana_sample_data_logs
| STATS total_bytes = SUM(bytes) BY geo.dest
| SORT total_bytes DESC
| LIMIT 3生成的可视化结果是一个显示前 3 个国家/地区的条形图:
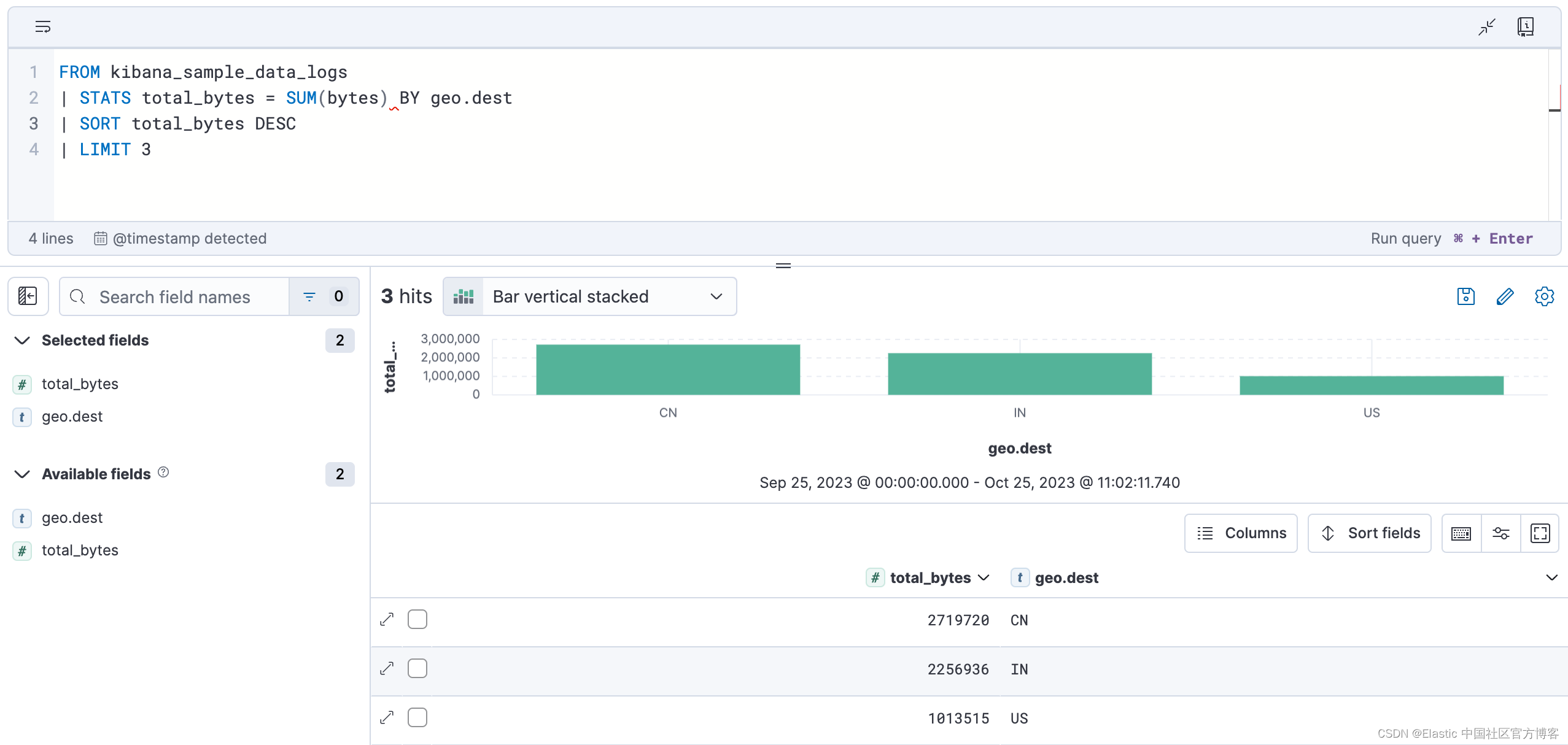
要将可视化更改为其他类型,请单击可视化类型下拉列表:

要对可视化进行其他更改(例如轴和颜色),请单击铅笔按钮 ![]() (esql 图标编辑可视化)。 这将打开一个内联编辑器:
(esql 图标编辑可视化)。 这将打开一个内联编辑器:

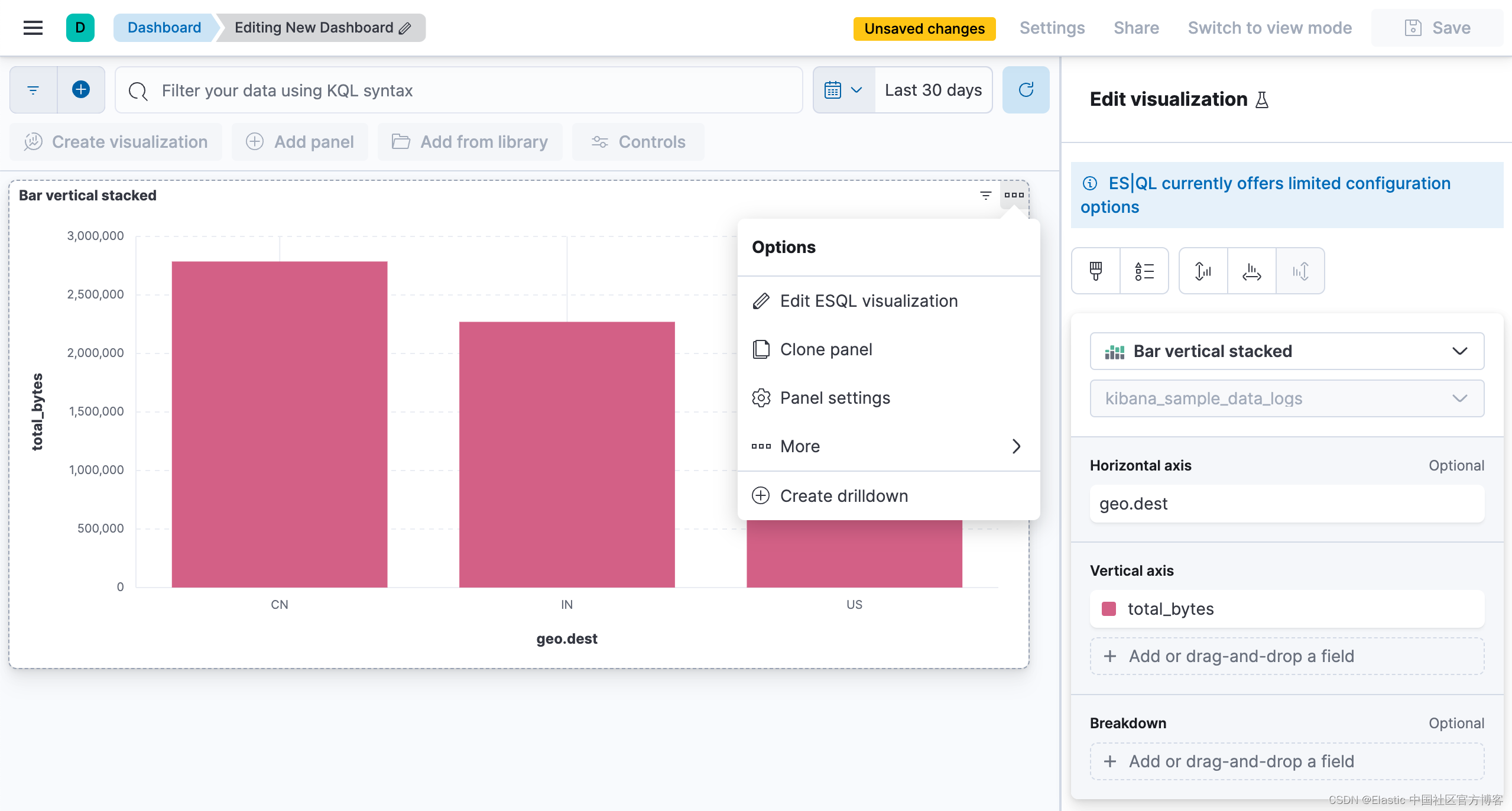
你可以通过单击保存按钮 ![]() (esql 图标保存可视化)将可视化保存到新的或现有的仪表板。 保存到仪表板后,你可以继续对可视化进行更改。 单击右上角的选项按钮
(esql 图标保存可视化)将可视化保存到新的或现有的仪表板。 保存到仪表板后,你可以继续对可视化进行更改。 单击右上角的选项按钮 ![]() (esql 图标选项)并选择 Edit ESQL Visualization 以打开内联编辑器:
(esql 图标选项)并选择 Edit ESQL Visualization 以打开内联编辑器:
制定丰富政策
ES|QL ENRICH 命令使你能够使用另一个数据集的字段来 enrich 查询数据集。 在使用 ENRICH 之前,你需要创建并执行丰富策略。 如果存在策略,则会自动完成建议。 如果没有,请单击 “Click to create” 来创建一个。

接下来,你可以输入策略名称、策略类型、源索引和可选的查询:

点击 Next 选择匹配字段并丰富字段:
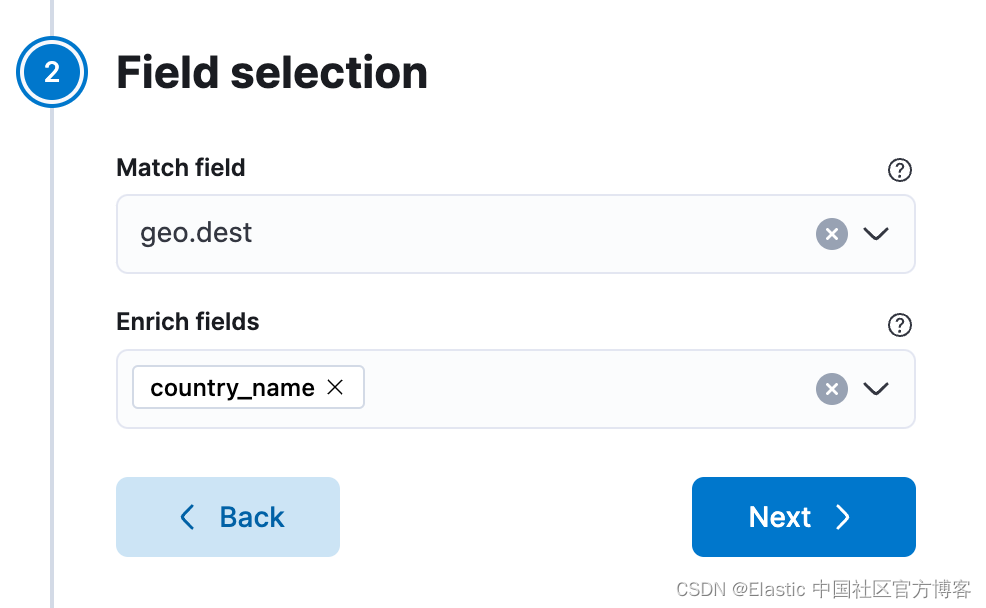
最后点击 Create and execute。
现在,你可以在 ES|QL 查询中使用丰富策略:
创建警报规则
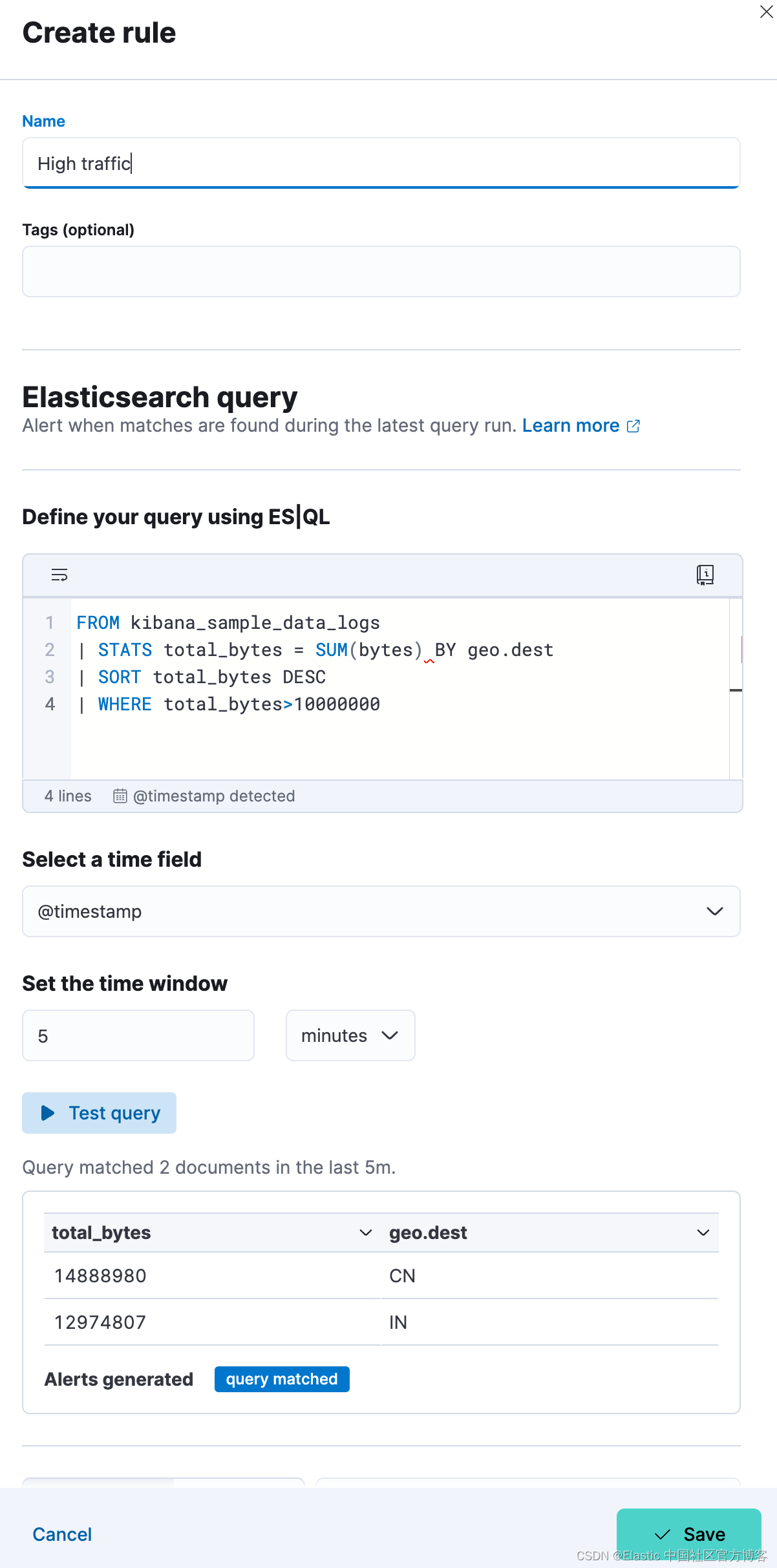
你可以使用 ES|QL 查询来创建警报。 从 Discover 中,单击 Alerts 并选择 Create search threshold rule。 这将打开一个面板,使你能够使用 ES|QL 查询创建规则。 接下来,你可以测试查询、添加连接器并保存规则。
局限性
- 当 Discover 处于 ES|QL 模式时,不会启用用于过滤数据的用户界面。 要过滤数据,请编写一个使用 WHERE 命令的查询。
- 在 ES|QL 模式下,单击 “Discover” 字段列表中的字段不会显示该字段的快速统计信息。
- Discover 显示的行数不超过 10,000 行。 此限制仅适用于查询检索并显示在 Discover 中的行数。 任何查询或聚合都在完整数据集上运行。
- Discover 显示不超过 50 列。 如果查询返回超过 50 列,Discover 仅显示前 50 列。
- 在没有任何过滤器的情况下一次查询许多索引可能会导致 Kibana 出现错误,类似于
esql] > Unexpected error from Elasticsearch: The content length (536885793) is bigger than the maximum allowed string (536870888). 内容长度 (536885793) 大于允许的最大字符串 (536870888)。 ES|QL 的响应太长。 使用 DROP 或 KEEP 来限制返回的字段数。
任务管理
我们可以使用 task management API 来列举及取消 ES|QL 查询。这个 API 返回有关集群中当前正在执行的任务的信息。
警告:Task management API 是新的,仍应被视为测试版功能。 API 可能会以不向后兼容的方式进行更改。 有关功能状态,请参阅 #51628。
请求
GET /_tasks/<task_id>GET /_tasks先决条件
如果启用了Elasticsearch安全功能,你必须具有 monitor 或 manage 集群权限才能使用此 API。
描述
任务管理 API 返回有关当前在集群中的一个或多个节点上执行的任务的信息。
Path 参数
<task_id>
(可选,字符串)要返回的任务 ID (node_id:task_number)。
请求参数
(可选,字符串)用于限制请求的操作的逗号分隔列表或通配符表达式。
省略此参数将返回所有操作。
detailed(可选,布尔值)如果为 true,则响应包括有关分片恢复的详细信息。 默认为 false。group_by(可选,字符串)用于对响应中的任务进行分组的键。
可能的值为:
- nodes - 缺省为 Node ID
- parents - Parent task ID
- none - 不要对任务进行分组
(可选,字符串)用于限制返回信息的父任务 ID。
要返回所有任务,请省略此参数或使用值 -1。
master_timeout(可选,时间单位)等待连接到主节点的时间。 如果超时之前未收到响应,则请求失败并返回错误。 默认为 30 秒。timeout(可选,时间单位)等待响应的时间。 如果超时之前未收到响应,则请求失败并返回错误。 默认为 30 秒。wait_for_completion(可选,布尔值)如果为 true,则请求将阻塞,直到所有找到的任务完成。 默认为 false。响应代码
404(缺少资源)
如果指定了 <task_id> 但未找到,则此代码表示没有与请求匹配的资源。
例子
GET _tasks (1)
GET _tasks?nodes=nodeId1,nodeId2 (2)
GET _tasks?nodes=nodeId1,nodeId2&actions=cluster:* (3)- 检索当前在集群中所有节点上运行的所有任务。
- 检索在节点 nodeId1 和 nodeId2 上运行的所有任务。 有关如何选择单个节点的更多信息,请参阅节点规范。
- 检索在节点 nodeId1 和 nodeId2 上运行的所有与集群相关的任务。
API 返回以下结果:
{"nodes" : {"oTUltX4IQMOUUVeiohTt8A" : {"name" : "H5dfFeA","transport_address" : "127.0.0.1:9300","host" : "127.0.0.1","ip" : "127.0.0.1:9300","tasks" : {"oTUltX4IQMOUUVeiohTt8A:124" : {"node" : "oTUltX4IQMOUUVeiohTt8A","id" : 124,"type" : "direct","action" : "cluster:monitor/tasks/lists[n]","start_time_in_millis" : 1458585884904,"running_time_in_nanos" : 47402,"cancellable" : false,"parent_task_id" : "oTUltX4IQMOUUVeiohTt8A:123"},"oTUltX4IQMOUUVeiohTt8A:123" : {"node" : "oTUltX4IQMOUUVeiohTt8A","id" : 123,"type" : "transport","action" : "cluster:monitor/tasks/lists","start_time_in_millis" : 1458585884904,"running_time_in_nanos" : 236042,"cancellable" : false}}}}
}从特定任务中检索信息
还可以检索特定任务的信息。 以下示例检索有关任务 oTUltX4IQMOUUVeiohTt8A:124 的信息:
GET _tasks/oTUltX4IQMOUUVeiohTt8A:124如果未找到任务,API 将返回 404。
要检索特定任务的所有子任务:
GET _tasks?parent_task_id=oTUltX4IQMOUUVeiohTt8A:123如果未找到父级,API 不会返回 404。
获取有关任务的更多信息
你还可以使用 detailed 请求参数来获取有关正在运行的任务的更多信息。 这对于区分任务很有用,但执行成本更高。 例如,使用 detailed 请求参数获取所有搜索:
GET _tasks?actions=*search&detailedAPI 返回以下结果:
{"nodes" : {"oTUltX4IQMOUUVeiohTt8A" : {"name" : "H5dfFeA","transport_address" : "127.0.0.1:9300","host" : "127.0.0.1","ip" : "127.0.0.1:9300","tasks" : {"oTUltX4IQMOUUVeiohTt8A:464" : {"node" : "oTUltX4IQMOUUVeiohTt8A","id" : 464,"type" : "transport","action" : "indices:data/read/search","description" : "indices[test], types[test], search_type[QUERY_THEN_FETCH], source[{\"query\":...}]","start_time_in_millis" : 1483478610008,"running_time_in_nanos" : 13991383,"cancellable" : true,"cancelled" : false}}}}
}新的 description 字段包含人类可读的文本,该文本标识任务正在执行的特定请求,例如标识由搜索任务正在执行的搜索请求,如上面的示例。 其他类型的任务有不同的描述,例如 _reindex 具有源和目标,或 _bulk 只具有请求数和目标索引。 许多请求仅具有空的描述,因为关于请求的更详细的信息不容易获得或者对于识别请求特别有帮助。
重要:带有详细信息的 _tasks 请求也可能返回状态。 这是任务内部状态的报告。 因此,其格式因任务而异。 虽然我们试图保持特定任务的状态在各个版本之间保持一致,但这并不总是可行,因为我们有时会更改实现。 在这种情况下,我们可能会从特定请求的状态中删除字段,因此你对状态所做的任何解析都可能会在次要版本中中断。
等待完成
任务 API 还可用于等待特定任务的完成。 以下调用将阻塞 10 秒,或者直到 I
POST _tasks/oTUltX4IQMOUUVeiohTt8A:12345/_cancelD 为 oTUltX4IQMOUUVeiohTt8A:12345 的任务完成。
GET _tasks/oTUltX4IQMOUUVeiohTt8A:12345?wait_for_completion=true&timeout=10s你还可以等待某些操作类型的所有任务完成。 此命令将等待所有 reindex 任务完成:
GET _tasks?actions=*reindex&wait_for_completion=true&timeout=10s任务取消
如果长时间运行的任务支持取消,则可以使用取消任务 API 取消它。 以下示例取消任务 oTUltX4IQMOUUVeiohTt8A:12345:
POST _tasks/oTUltX4IQMOUUVeiohTt8A:12345/_cancel任务取消命令支持与列表任务命令相同的任务选择参数,因此可以同时取消多个任务。 例如,以下命令将取消在节点 nodeId1 和 nodeId2 上运行的所有重新索引任务。
POST _tasks/_cancel?nodes=nodeId1,nodeId2&actions=*reindex任务在被取消后可能会继续运行一段时间,因为它可能无法立即安全地停止其当前活动,或者因为 Elasticsearch 必须完成其他任务的工作才能处理取消。 列表任务 API 将继续列出这些已取消的任务,直到它们完成。 列表任务 API 响应中的 cancelled 标志表示取消命令已被处理,任务将尽快停止。 要排查取消的任务无法立即完成的原因,请使用带有 ?detailed 参数的列表任务 API 来识别系统正在运行的其他任务,并使用 Nodes 热线程 API 来获取有关系统正在执行的工作的详细信息完成取消的任务。
任务分组
任务 API 命令返回的任务列表可以按节点(默认)分组,也可以使用 group_by 参数按父任务分组。 以下命令会将分组更改为父任务:
GET _tasks?group_by=parents可以通过指定 none 作为 group_by 参数来禁用分组:
GET _tasks?group_by=none识别正在运行的任务
X-Opaque-Id 标头在 HTTP 请求标头上提供时,将作为响应中的标头以及任务信息的标头字段中返回。 这允许跟踪某些呼叫,或将某些任务与启动它们的客户端相关联:
curl -i -H "X-Opaque-Id: 123456" "http://localhost:9200/_tasks?group_by=parents"API 返回以下结果:
HTTP/1.1 200 OK
X-Opaque-Id: 123456 (1)
content-type: application/json; charset=UTF-8
content-length: 831{"tasks" : {"u5lcZHqcQhu-rUoFaqDphA:45" : {"node" : "u5lcZHqcQhu-rUoFaqDphA","id" : 45,"type" : "transport","action" : "cluster:monitor/tasks/lists","start_time_in_millis" : 1513823752749,"running_time_in_nanos" : 293139,"cancellable" : false,"headers" : {"X-Opaque-Id" : "123456" (2)},"children" : [{"node" : "u5lcZHqcQhu-rUoFaqDphA","id" : 46,"type" : "direct","action" : "cluster:monitor/tasks/lists[n]","start_time_in_millis" : 1513823752750,"running_time_in_nanos" : 92133,"cancellable" : false,"parent_task_id" : "u5lcZHqcQhu-rUoFaqDphA:45","headers" : {"X-Opaque-Id" : "123456" (3)}}]}}
}- id 作为响应头的一部分
- 由 REST 请求启动的任务的 ID
- REST请求发起的任务的子任务
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"Elasticsearch:使用 ES|QL":http://eshow365.cn/6-32177-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!