pytorch:R-CNN的pytorch实现
最佳答案 问答题库628位专家为你答疑解惑
pytorch:R-CNN的pytorch实现
仅作为学习记录,请谨慎参考,如果错误请评论指出。
参考文献:Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
https://blog.csdn.net/qq_41694024/category_12145273.html
参考项目:https://github.com/object-detection-algorithm/R-CNN
模型参数文件:链接:https://pan.baidu.com/s/1EWYcYuhwK5s7x1yOTe7rlQ?pwd=lgsf 提取码:lgsf
下载网盘里的模型参数然后放进./models文件夹内
环境配置: python3.10 pip install -r requirements.txt
R-CNN可以说是使用CNN进行目标检测任务的始祖,而且取得了不错的成绩。对后续的算法,例如现在经常使用的Yolo系列有很大的影响。刚入门目标检测我认为还是有必要学习下R-CNN。
R-CNN算法的大致流程

作者在论文中的图中说明了大致的算法流程。输入图像后提取大约两千个候选框,然后将候选框放缩成(227x227)大小的图像放入到CNN网络中进行特征提取,然后通过训练好的SVM对其打分分类
模型设计
1、区域提议。使用选择性搜索算法提出候选框。由于CNN网络接受的输入图像尺寸只能是(227x227)因此还需要对候选框做进一步的变形,作者实验了几种不同的方法,最终选择了包含上下文(padding= 16pixels)的改变高宽比的缩放。

2、特征提取。2012年AlexNet在ImageNet上胜出使得CNN重新得到人们的关注,作者认为CNN相较于传统算法提取特征更加高效和通用,因此提取特征的任务可以由AlexNet实现。但是同样存在问题,如何在小数据集上训练出高性能的特征提取器,作者想到了使用微调。
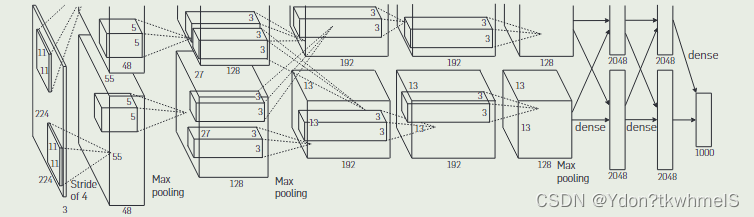
用Pytorch实现R-CNN单类别检测
VOC数据集处理
VOC数据集的介绍可以参考这篇博客:https://blog.csdn.net/cengjing12/article/details/107820976
我们需要从VOC数据集中得到训练用的正负样本。首先获取包含识别类别物体的图片,然后通过选择性搜索算法生成很多的候选框,其中候选框与真实边界框的IoU值大于0.5设置为正样本其余则是负样本,IoU阈值可以设置成其他值。
import osimport cv2
import xmltodict
import numpy as npimport selectivesearch
import util'''
VOC数据集的结构
.
└── VOCdevkit #根目录└── VOC2012 #不同年份的数据集,这里只下载了2012的,还有2007等其它年份的├── Annotations #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等├── ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本│ ├── Action│ ├── Layout│ ├── Main #存放的是分类和检测的数据集分割文件│ └── Segmentation├── JPEGImages #存放源图片├── SegmentationClass #存放的是图片,语义(class)分割相关└── SegmentationObject #存放的是图片,实例(object)分割相关├── Main
│ ├── train.txt 写着用于训练的图片名称
│ ├── val.txt 写着用于验证的图片名称
│ ├── trainval.txt train与val的合集
│ ├── test.txt 写着用于测试的图片名称
'''PATH = r"E:\Postgraduate_Learning\Python_Learning\DataSets\pascal_voc2007\VOCdevkit\VOC2007"def get_class(path):"""获取VOC数据集中的类别必须按照VOC数据集的标准格式:param path: 数据集的根目录的下一级目录即,VOC+年份,例如:VOC2007:return: 数据集的类别 list"""# 判断是否是文件夹if os.path.isdir(path):# 得到文件夹中所有的txt文件object_list = os.listdir(path + "\ImageSets\Main")# print(object_list)class_list = []temp = []# 所有的txt文件命名格式为 类别名_train(val、trainval).txt 意思是这个类别的训练集或者测试集或者训练集和测试集混在一起# 只保留带有类别名字的txt文件object_list = [i for i in object_list if i.find("_") != -1]# print(object_list)for class_name in object_list:# 处理文件名,得到类别名class_name = class_name.strip(".txt").split('_')[0]temp.append(class_name)# 去除重复类[class_list.append(i) for i in temp if i not in class_list]# (len(class_list))# print(class_list)# 类别排序class_list = sorted(class_list)return class_listdef xml_parse(path):"""解析标注文件:param path: 数据集的根目录的下一级目录即,VOC+年份,例如:VOC2007:return: 图片名字列表, 对象类别列表, 对象边界框列表"""# 下面三个一一对应# 图片名字列表image_name_list = []# 对象类别列表object_class_list = []# 对象边界框列表object_bndbox_list= []xml_file_list = os.listdir(path+"\Annotations")# print(len(xml_file_list))for xml_file in xml_file_list:with open(os.path.join(path+"\Annotations", xml_file), "r") as xml_file:xml_dict = xmltodict.parse(xml_file.read())# print(xml_dict)# 图片的名字放在了 ['annotation']标签下的['filename']属性image_name = xml_dict['annotation']['filename']# 因为有很多个[object]标签,所以xml解析出来的字典 object对应的值是个列表object_list = xml_dict['annotation']['object']# 可能一张图片中就有一个对象,转换为可以迭代的列表if isinstance(object_list, list) != True:object_list = list([object_list])# print(type(object_list))# 一张图片可能出现很多个对象,每个对象的坐标和类别都不一定相同for object in object_list:# 获取对象所属类别名称class_name = object['name']# print(class_name)# 获取边界框的坐标bndbox_xmin = int(object['bndbox']['xmin'])bndbox_ymin = int(object['bndbox']['ymin'])bndbox_xmax = int(object['bndbox']['xmax'])bndbox_ymax = int(object['bndbox']['ymax'])# print(bndbox_xmin, bndbox_ymin, bndbox_xmax, bndbox_ymax)image_name_list.append(image_name)object_class_list.append(class_name)object_bndbox_list.append((bndbox_xmin, bndbox_ymin, bndbox_xmax, bndbox_ymax))print(len(image_name_list))return image_name_list, object_class_list, object_bndbox_listdef one_xml_parse(path):# 下面三个一一对应# 图片名字列表image_name_list = []# 对象类别列表object_class_list = []# 对象边界框列表object_bndbox_list= []with open(path, "r") as xml_file:xml_dict = xmltodict.parse(xml_file.read())# print(xml_dict)# 图片的名字放在了 ['annotation']标签下的['filename']属性image_name = xml_dict['annotation']['filename']# 因为有很多个[object]标签,所以xml解析出来的字典 object对应的值是个列表object_list = xml_dict['annotation']['object']# 可能一张图片中就有一个对象,转换为可以迭代的列表if isinstance(object_list, list) != True:object_list = list([object_list])# print(type(object_list))# 一张图片可能出现很多个对象,每个对象的坐标和类别都不一定相同for object in object_list:# 获取对象所属类别名称class_name = object['name']# print(class_name)# 获取边界框的坐标bndbox_xmin = int(object['bndbox']['xmin'])bndbox_ymin = int(object['bndbox']['ymin'])bndbox_xmax = int(object['bndbox']['xmax'])bndbox_ymax = int(object['bndbox']['ymax'])# print(bndbox_xmin, bndbox_ymin, bndbox_xmax, bndbox_ymax)image_name_list.append(image_name)object_class_list.append(class_name)object_bndbox_list.append([bndbox_xmin, bndbox_ymin, bndbox_xmax, bndbox_ymax])# print(len(image_name_list))return image_name_list, object_class_list, object_bndbox_listdef get_posANDneg_image(path, class_name, train: str):"""获取数据集中某个类别的正负样本图片名称:param path::param class_name::return:"""# 正负样本postive_ann_image = []negative_ann_image = []# 根据类别名,读取txt文件with open(os.path.join(path, "ImageSets", "main", class_name+"_"+train+".txt"), "r") as f:# 按行读取txt文件的内容并去除末尾的换行符image_and_ann = [line.strip() for line in f.readlines()]# print(image_and_ann)for line in image_and_ann:# 按照空格分开字符串,前一部分为图片名称,后一部分为正负样本的标志# -1标志的样本间隔一个空格,1标志的样本间隔俩空格image = line.split(' ')# 如果标志是'1'则为正样本,也就是包含了对象的图片if image[-1] == '1':postive_ann_image.append(image[0]+".jpg")# 如果标志是'-1'则是负样本,也就是没有包含对象的图片elif image[-1] == '-1':negative_ann_image.append(image[0]+".jpg")# print(postive_ann_image, negative_ann_image)return postive_ann_image, negative_ann_imagedef get_posANDneg_samples(path, class_name, iou_thr):# 正负样本postive_samples = []negative_samples = []# 正负样本对应的图片名字postive_images = []negative_images = []# 定义选择性选择框gs = selectivesearch.get_selective_search()for name in ["train"]:# 获取包含识别对象图片的文件名名字postive_ann_image, _ = get_posANDneg_image(path, class_name, name)for one_image in postive_ann_image:# print(f"文件名: {one_image}")# 得到一个包含识别对象图片的xml文件路径xmlfile_path = os.path.join(path, "Annotations", one_image.split('.')[0]+".xml")# 得到一个包含识别对象图片路径img_path = os.path.join(path, "JPEGImages", one_image)# 读取图片jpeg_img = cv2.imread(img_path)# 生成候选框selectivesearch.config(gs, jpeg_img, strategy='q')# 计算候选建议rects = selectivesearch.get_rects(gs)# print(f"总共生成了{len(rects)}个候选框")# 解析对应图片的xml文件image_name_list, object_class_list, object_bndbox_list = one_xml_parse(xmlfile_path)# 获取边界框object_bndbox_list = [object_bndbox_list[index] for (index, name) in enumerate(object_class_list)if name == class_name ]# print(f"共获取{len(object_bndbox_list)}个标注边界框")# 转换边界框的数据类型object_bndbox_list = np.array(object_bndbox_list)# print(f"转换边界框的数据类型为{type(object_bndbox_list)}")# 标注框大小,如果有多个边界框,则叹得最大的边界框大小maximum_bndbox_size = 0for bndbox in object_bndbox_list:xmin, ymin, xmax, ymax = bndboxbndbox_size = (ymax - ymin) * (xmax - xmin)if bndbox_size > maximum_bndbox_size:maximum_bndbox_size = bndbox_size# 对每个候选框进行处理,计算并比较IOU值获取正样本for bndbox in object_bndbox_list:# 计算IOU的值iou_list = util.compute_ious(rects, bndbox)# print("计算预选框和实框的iou列表", len(iou_list))iou_thr = iou_thr# iou_list和 rect 列表长度应该一致for i in range(len(iou_list)):xmin, ymin, xmax, ymax = rects[i]rect_size = (ymax - ymin) * (xmax - xmin)iou_score = iou_list[i]# 如果某个框体的iou值在0-0.3之间且框体大少低于真实框体的五分之一if 0 < iou_score <= iou_thr and rect_size > maximum_bndbox_size / 5.0:# 负样本negative_samples.append(rects[i])negative_images.append(one_image)if iou_thr <= iou_score <= 1 and rect_size > maximum_bndbox_size / 5.0:postive_samples.append(rects[i])postive_images.append(one_image)return postive_samples, postive_images, len(postive_samples), \negative_samples, negative_images, len(negative_samples)if __name__ == "__main__":# voc_dataset = VOCDetection(root= PATH, year= "2007", image_set= "train",# download= False)# print(type(voc_dataset))# CLASS = get_class(PATH)# print(CLASS)# print(get_posANDneg_image(PATH, "cat"))postive_samples, postive_images, a, \negative_samples, negative_images, b = get_posANDneg_samples(PATH, "cat", iou_thr= 0.3)制作模型训练用的数据集
Pytorch提供了Dataset类,需要自定义数据集的时候通过继承Dataset类并重写__init__()、__getitem__()、__len__()来实现自定义数据集。
__init__()中实现读取处理相关图片。
__getitem__()接受索引返回对应的样本以及标签。
__len__()返回数据集的大小。
实现好这三个方法后,通过Dataloader加载数据集。
import random
import numpy as np
import torch
from torchvision import transforms
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.data import Sampler
import cv2
import os
from PIL import Imageimport pascal_VOCclass RCNN_DetectionDataSet(Dataset):"""适用于RCNN单类别识别的数据集"""def __init__(self, path, transform= None):self.transform = transformself.path = path# 获取分类标签self.detect_class = pascal_VOC.get_class(path)[0]# 获取获取正负样本,对应的样本数量,对应的图片名称self.postive_samples, self.postive_images, self.num_postive, \self.negative_samples, self.negative_images, self.num_negative = \pascal_VOC.get_posANDneg_samples(path, self.detect_class, iou_thr= 0.3)passdef __getitem__(self, index):# 如果索引小于正样本图片的数量,则认为是正样本索引if index < self.num_postive:# 读取正样本图片JPEGimages = cv2.imread(os.path.join(self.path, "JPEGImages", self.postive_images[index]))else:# 读取负样本图片JPEGimages = cv2.imread(os.path.join(self.path, "JPEGImages", self.negative_images[index - self.num_postive]))# 转换下色彩通道JPEGimages = cv2.cvtColor(JPEGimages, cv2.COLOR_BGR2RGB)if index < self.num_postive:# 正样本的标签为1label = torch.tensor([1])# 获取对象所在的区域x1, y1, x2, y2 = self.postive_samples[index]region = JPEGimages[y1:y2, x1:x2]region = cv2.resize(region, (227, 227))region = transforms.ToTensor()(region)else:# 负样本为0label = torch.tensor([0])x1, y1, x2, y2 = self.negative_samples[index - self.num_postive]region = JPEGimages[y1:y2, x1:x2]region = cv2.resize(region, (227, 227))region = transforms.ToTensor()(region)return region, labeldef __len__(self):# 样本数量就是所有边界框的个数return self.num_postive + self.num_negativepassdef get_postive_samples_num(self):return self.num_postivedef get_negative_samples_num(self):return self.num_negativeclass RCNN_BatchSampler(Sampler):"""2分类数据集采样器"""def __init__(self, num_positive, num_negative, batch_positive, batch_negative):self.num_positive = num_positiveself.num_negative = num_negativeself.batch_positive = batch_positiveself.batch_negative = batch_negative# 计算数据集大小length = num_positive + num_negative# 生成索引序列self.idx_list = list(range(length))# 计算batch大小self.batch = batch_negative + batch_positive# 计算可以生成多少个完整batchself.num_iter = length // self.batchdef __iter__(self):sampler_list = list()for i in range(self.num_iter):tmp = np.concatenate((random.sample(self.idx_list[:self.num_positive], self.batch_positive),random.sample(self.idx_list[self.num_positive:], self.batch_negative)))random.shuffle(tmp)sampler_list.extend(tmp)return iter(sampler_list)def __len__(self) -> int:return self.num_iter * self.batchdef get_num_batch(self) -> int:return self.num_iterdef test(idx):PATH = r"E:\Postgraduate_Learning\Python_Learning\DataSets\pascal_voc2007\VOCdevkit\VOC2007"train_data_set = RCNN_DetectionDataSet(PATH)print('positive num: %d' % train_data_set.get_postive_samples_num())print('negative num: %d' % train_data_set.get_negative_samples_num())print('total num: %d' % train_data_set.__len__())# 测试id=3/66516/66517/530856image, target = train_data_set.__getitem__(idx)print('target: %d' % target)print(image)print(type(image))cv2.imshow("a",image)cv2.waitKey(0)def test1():root_dir = r"E:\Postgraduate_Learning\Python_Learning\DataSets\pascal_voc2007\VOCdevkit\VOC2007"train_data_set = RCNN_DetectionDataSet(root_dir)train_sampler = RCNN_BatchSampler(train_data_set.get_postive_samples_num(), train_data_set.get_negative_samples_num(), 32, 96)print('sampler len: %d' % train_sampler.__len__())print('sampler batch num: %d' % train_sampler.get_num_batch())first_idx_list = list(train_sampler.__iter__())[:128]print(first_idx_list)# 单次批量中正样本个数print('positive batch: %d' % np.sum(np.array(first_idx_list) < 66517))if __name__ == "__main__":# PATH = r"E:\Postgraduate_Learning\Python_Learning\DataSets\pascal_voc2007\VOCdevkit\VOC2007"# test_dataset = RCNN_DetectionDataSet(PATH, transform= None)# test_dataloader = DataLoader(test_dataset, 4, shuffle= True)# a = next(iter(test_dataloader))[0]# print(a.shape)# print(next(iter(test_dataloader))[1])# cv2.imshow("a", a[0].numpy())# cv2.waitKey(0)# # 测试结果应该是正# test(120)# # 测试结果应该是正# test(280)# # 测试结果应该是负# test(600)# # 测试结果应该是负# test(2100)test1()
微调
Pytorch已经实现了AlexNet的结构,并且提供了ImageNet训练后的参数。所需要做的就是在准备好的数据集上再训练。
import torch
from torch import nn
from torchvision import models
from torchvision import transforms
from torch.utils.data import DataLoaderimport dataset
from Lib.Trainer import Trainerdef load_data():"""加载数据,只加载训练集的:return:"""# 增强数据集transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((227, 227)),transforms.ToTensor(),# 对图片进行归一化,每个输入通道都减去其平均值再除以其标准差# 两个参数表示平均值和方差transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])path = r"E:\Postgraduate_Learning\Python_Learning\DataSets\pascal_voc2007\VOCdevkit\VOC2007"# 数据集data_set = dataset.RCNN_DetectionDataSet(path= path, transform= transform)# 每一个批次含有32个正样本和96个负样本data_sampler = dataset.RCNN_BatchSampler(data_set.get_postive_samples_num(),data_set.get_negative_samples_num(),32, 96)# drop_last表示是否当数据集无法整除批量大小时丢掉最后一批data_loader = DataLoader(dataset= data_set,batch_size= 128,sampler= data_sampler,num_workers= 2,drop_last= True)data_size = len(data_sampler)return data_loader, data_sizedef AlexNet_finetuning():# 指定使用的设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# device = torch.device("cpu")AlexNet_pre = models.alexnet(pretrained=True)# AlexNet_pre = models.alexnet(pretrained= False)train_iter, train_size = load_data()# print(AlexNet_pre)# 获取分类器的输入特征数量num_features = AlexNet_pre.classifier[6].in_features# print(AlexNet_pre.classifier[6].in_features)# 把最后一层改成二分类AlexNet_pre.classifier[6] = nn.Linear(num_features, 2)# AlexNet_pre = AlexNet_pre.to(device)# 使用交叉熵作为损失函数loss = nn.CrossEntropyLoss()optimer = torch.optim.SGD(params= AlexNet_pre.parameters(), lr= 1e-3,momentum= 0.9)# 学习率衰减策略,每7个epoch衰减十倍lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer= optimer,step_size= 7,gamma= 0.1 ,verbose= True)trainer = Trainer()trainer.config_trainer(AlexNet_pre, dataloader= train_iter,optimer= optimer, lr_scheduler= lr_scheduler, loss= loss,device= device)trainer.config_task(128, 10)trainer.start_task()torch.save(AlexNet_pre.state_dict(), '.models/alexnet_cat_10epochs_new.pth')
if __name__ == "__main__":AlexNet_finetuning()做上一点说明,R-CNN使用的分类器是SVM,原文将AlexNet最后一层去掉只用网络提取了4096维的向量然后使用已经训练好的SVM进行分类,本篇的实现则直接用了Softmax做分类,相当于没有改变网络结构。
关于作者为何不使用Softmax做分类,在附录中有说明,但是说的不咋清楚。
作者说,使用了Softmax反而造成了性能的下降,他们推断可能是因为正负样本的划分不同导致的(SVM正样本只有真实边界框,负样本要求IoU小于0.3与真实边界框)。CNN的那种划分方式用在微调上造成了正样本太少负样本太多的情况。关于SVM我不咋了解,而且作为初学者,推断不出什么原因。
预测
选一些图片,按照上面的算法流程进行预测即可。
import torch
from torchvision import transforms
from torchvision.models import alexnet
from torch import nn
import cv2
import copy
import time
import numpy as npimport pascal_VOC
import selectivesearch
import utildef get_model(device=None):# 加载CNN模型model = alexnet()num_classes = 2num_features = model.classifier[6].in_featuresmodel.classifier[6] = nn.Linear(num_features, num_classes)model.load_state_dict(torch.load('models/alexnet_cat_10epochs_new.pth'))model.eval()# 取消梯度追踪for param in model.parameters():param.requires_grad = Falseif device:model = model.to(device)return modeldef nms(rect_list, score_list):"""非最大抑制:param rect_list: list,大小为[N, 4]:param score_list: list,大小为[N]"""nms_rects = list()nms_scores = list()rect_array = np.array(rect_list)score_array = np.array(score_list)# 一次排序后即可# 按分类概率从大到小排序idxs = np.argsort(score_array)[::-1]rect_array = rect_array[idxs]score_array = score_array[idxs]thresh = 0.1while len(score_array) > 0:# 添加分类概率最大的边界框nms_rects.append(rect_array[0])nms_scores.append(score_array[0])rect_array = rect_array[1:]score_array = score_array[1:]length = len(score_array)if length <= 0:break# 计算IoUiou_scores = util.iou(np.array(nms_rects[len(nms_rects) - 1]), rect_array)# print(iou_scores)# 去除重叠率大于等于thresh的边界框idxs = np.where(iou_scores < thresh)[0]rect_array = rect_array[idxs]score_array = score_array[idxs]return nms_rects, nms_scoresdef draw_box_with_text(img, rect_list, score_list):"""绘制边框及其分类概率:param img::param rect_list::param score_list::return:"""for i in range(len(rect_list)):xmin, ymin, xmax, ymax = rect_list[i]score = score_list[i]cv2.rectangle(img, (xmin, ymin), (xmax, ymax), color=(0, 0, 255), thickness=2)cv2.putText(img, "{:.3f}".format(score), (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 1)if __name__ == "__main__":device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 数据转换transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((227, 227)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])model = get_model(device=device)gs = selectivesearch.get_selective_search()test_img_path = r"./img/n_test1.jpg"# test_xml_path = r"./img/000122.xml"img = cv2.imread(test_img_path)dst = copy.deepcopy(img)# 获取标注的边界框# _, _, bndboxs = pascal_VOC.one_xml_parse(test_xml_path)# for bndbox in bndboxs:# xmin, ymin, xmax, ymax = bndbox# cv2.rectangle(dst, (xmin, ymin), (xmax, ymax), color=(0, 255, 0), thickness=1)# cv2.imshow("a", dst)# cv2.waitKey(0)# 候选区域建议selectivesearch.config(gs, img, strategy='f')rects = selectivesearch.get_rects(gs)print('候选区域建议数目: %d' % len(rects))svm_thresh = 0.8# 得分列表,正样本列表score_list = list()positive_list = list()start = time.time()for rect in rects:xmin, ymin, xmax, ymax = rectrect_img = img[ymin:ymax, xmin:xmax]rect_transform = transform(rect_img).to(device)output = model(rect_transform.unsqueeze(0))# print(output)# print(output.shape)output = output[0]if torch.argmax(output).item() == 1:"""预测为cat"""probs = torch.softmax(output, dim=0).cpu().numpy()print(probs)print(probs.shape)if probs[1] >= svm_thresh:score_list.append(probs[1])positive_list.append(rect)# cv2.rectangle(dst, (xmin, ymin), (xmax, ymax), color=(0, 0, 255), thickness=2)# print(rect, output, probs)end = time.time()print('detect time: %d s' % (end - start))nms_rects, nms_scores = nms(positive_list, score_list)print(nms_rects)print(nms_scores)draw_box_with_text(dst, nms_rects, nms_scores)cv2.imshow('img', dst)cv2.waitKey(0)
99%的人还看了
相似问题
- 斯坦福机器学习 Lecture2 (假设函数、参数、样本等等术语,还有批量梯度下降法、随机梯度下降法 SGD 以及它们的相关推导,还有正态方程)
- 340条样本就能让GPT-4崩溃,输出有害内容高达95%?OpenAI的安全防护措施再次失效
- FSOD论文阅读 - 基于卷积和注意力机制的小样本目标检测
- 数智竞技何以成为“科技+体育”新样本?
- [深度学习]不平衡样本的loss
- Python实战:绘制直方图的示例代码,数据可视化获取样本分布特征
- 某汽车金融企业:搭建SDLC安全体系,打造智慧金融服务样本
- 计算样本方差和总体方差
- 小样本分割的新视角,Learning What Not to Segment【CVPR 2022】
- 学习笔记|两独立样本秩和检验|曼-惠特尼 U数据分布图|规范表达|《小白爱上SPSS》课程:SPSS第十二讲 | 两独立样本秩和检验如何做?
猜你感兴趣
版权申明
本文"pytorch:R-CNN的pytorch实现":http://eshow365.cn/6-28071-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: MySQL使用存储过程迁移用户表数据,过滤用户名相同名称不同的用户
- 下一篇: 历史随想随记