已解决
论文阅读——GPT3
来自网友在路上 149849提问 提问时间:2023-10-30 18:07:11阅读次数: 49
最佳答案 问答题库498位专家为你答疑解惑
来自论文:Language Models are Few-Shot Learners
Arxiv:https://arxiv.org/abs/2005.14165v2
记录下一些概念等。,没有太多细节。
预训练LM尽管任务无关,但是要达到好的效果仍然需要在特定数据集或任务上微调。因此需要消除这个限制。解决这些问题的一个潜在途径是元学习——在语言模型的背景下,这意味着该模型在训练时发展了一系列广泛的技能和模式识别能力,然后在推理时使用这些能力来快速适应或识别所需的任务(如图1.1所示)
“in-context learning”:

关于“zero-shot”, “one-shot”, or “few-shot”的解释:

随着模型增大,in-context learning效果越好:
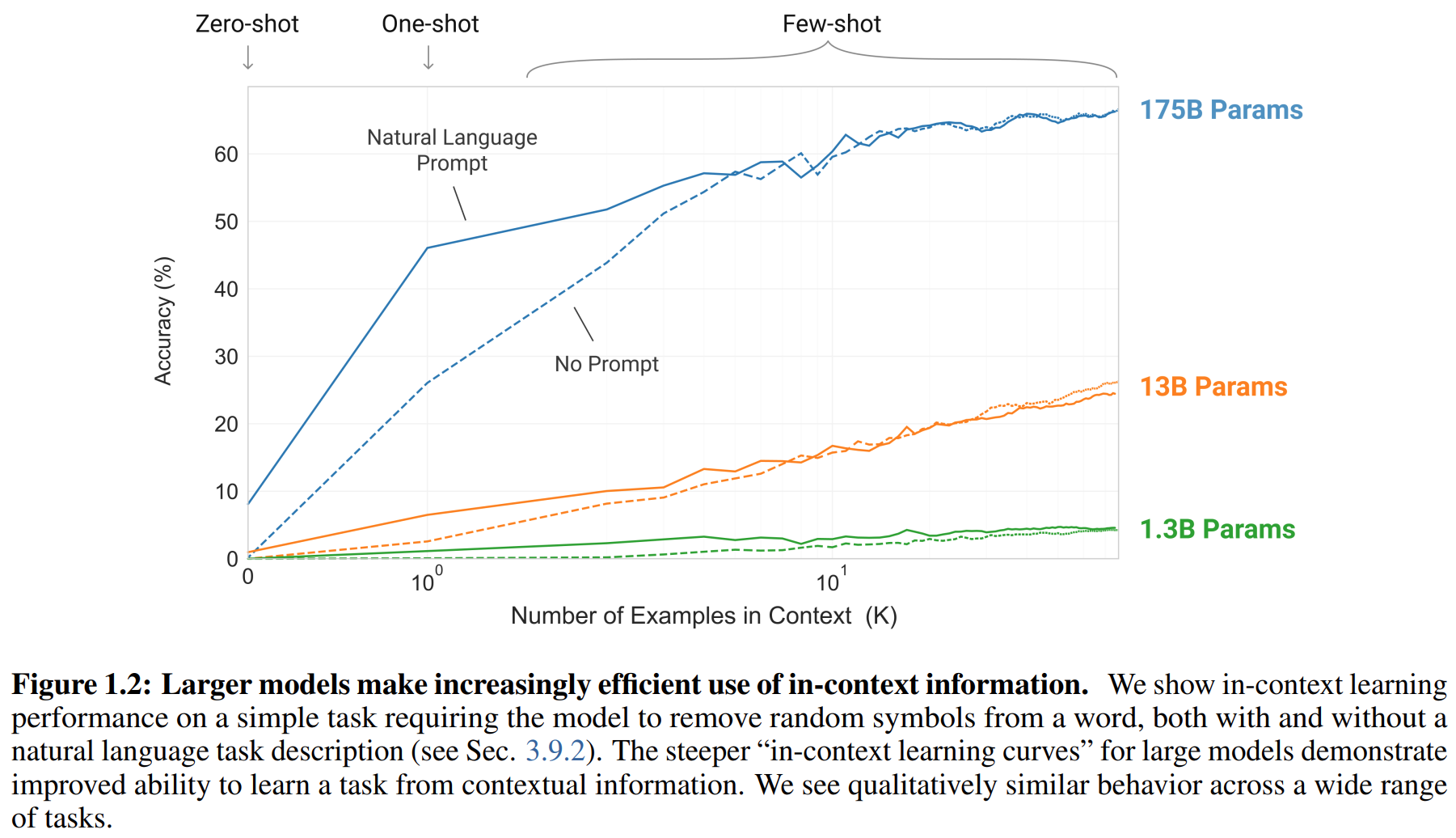
关于“zero-shot”, “one-shot”, or “few-shot”

模型结构和GPT2一样,但是改了初始化、预归一化、reversible tokenization,以及在transformers层中使用类似Sparse Transformer的交替密集和局部稀疏的注意力模式。
内容窗口大小=2048 tokens
训练了8个不同大小的模型:
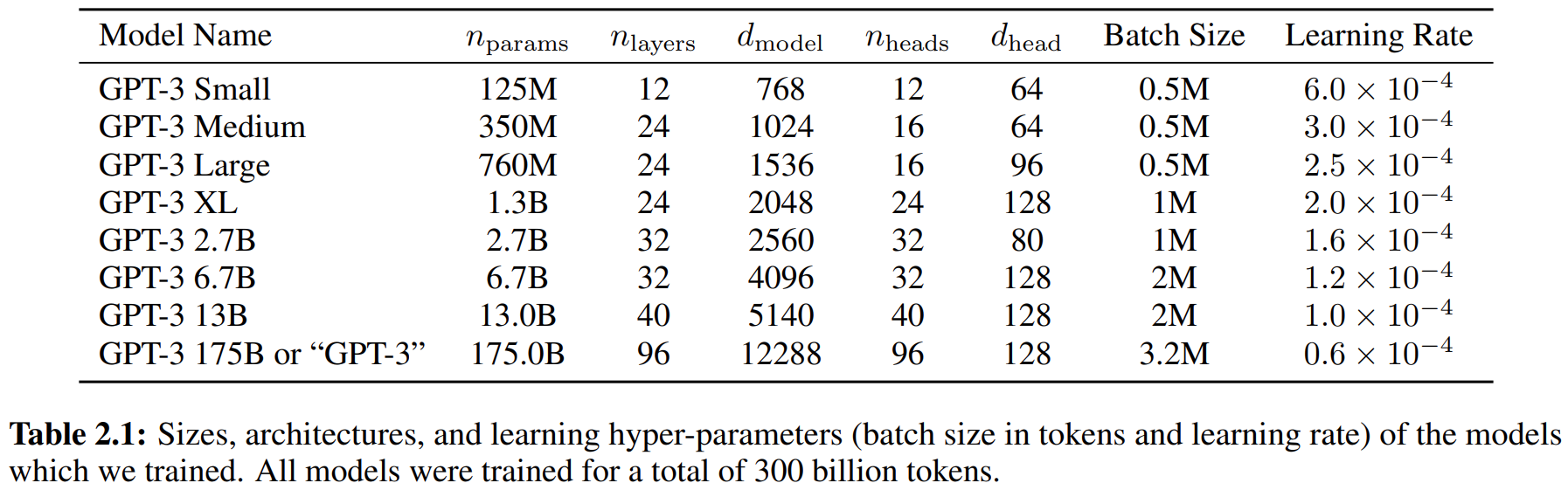
其他细节:
训练大模型需要大batch,小学习率。
few-shot learning中,实例样本数量k取值可以从0到最大窗口大小,一般可以设为10-100。
查看全文
99%的人还看了
相似问题
- 最新AIGC创作系统ChatGPT系统源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图,图片对话理解功能
- 思维模型 等待效应
- FinGPT:金融垂类大模型架构
- 人工智能基础_机器学习044_使用逻辑回归模型计算逻辑回归概率_以及_逻辑回归代码实现与手动计算概率对比---人工智能工作笔记0084
- Pytorch完整的模型训练套路
- Doris数据模型的选择建议(十三)
- python自动化标注工具+自定义目标P图替换+深度学习大模型(代码+教程+告别手动标注)
- ChatGLM2 大模型微调过程中遇到的一些坑及解决方法(更新中)
- Python实现WOA智能鲸鱼优化算法优化随机森林分类模型(RandomForestClassifier算法)项目实战
- 扩散模型实战(十一):剖析Stable Diffusion Pipeline各个组件
猜你感兴趣
版权申明
本文"论文阅读——GPT3":http://eshow365.cn/6-27939-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: CentOS7安装playwright终极指南
- 下一篇: BLIP2中Q-former详解