Stable Diffusion系列(一):古早显卡上最新版 WebUI 安装及简单操作
最佳答案 问答题库758位专家为你答疑解惑
文章目录
- Stable Diffusion安装
- AnimateDiff插件适配
- sdxl模型适配
- Stable Diffusion使用
- 插件安装
- 界面设置
- 基础文生图
- 加入lora的文生图
Stable Diffusion安装
我的情况比较特殊,显卡版本太老,最高也就支持cuda10.2,因此只能安装pytorch1.12.1,并且无法安装xformers。
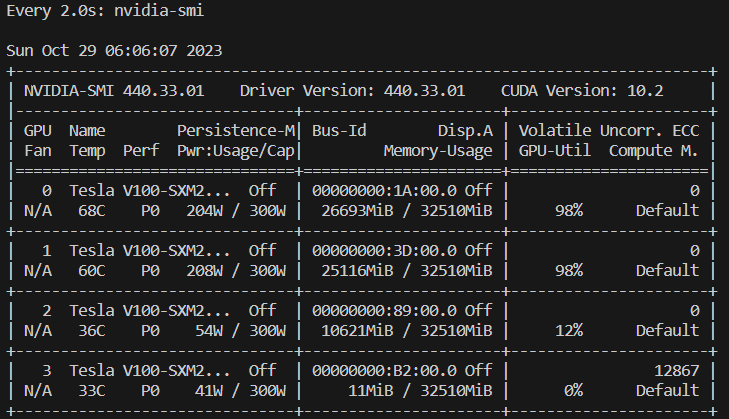
在安装好虚拟环境和对应pytorch版本后,按照github教程安装stable diffusion webui即可,在webui.sh中将use_venv=1 (默认) 修改为use_venv=0,以在当前激活的虚拟环境中运行webui,然后执行bash webus.sh安装相关依赖。
针对显卡使用情况,可在webui-user.sh中设置可见显卡export CUDA_VISIBLE_DEVICES=0,1,2,并在执行webui.py时在命令行中通过--device-id=1指定具体的使用设备。
为了使用最新的模型和插件,需要做出以下适配:
AnimateDiff插件适配
该插件的原理是在调用和完成时分别向原始模型中注入(inject)和删除(restore)时间步模块从而生成连续变化的GIF,由于整体版本过老,直接执行该插件会报没有insert和pop方法的错误,因此需要在animatediff_mm.py文件中手动实现这两个函数,需要注意insert和pop的操作和通常理解不一样:
def inject(self, sd_model, model_name="mm_sd_v15.ckpt"):unet = sd_model.model.diffusion_modelself._load(model_name)self.gn32_original_forward = GroupNorm32.forwardgn32_original_forward = self.gn32_original_forward# self.tes_original_forward = TimestepEmbedSequential.forward# def mm_tes_forward(self, x, emb, context=None):# for layer in self:# if isinstance(layer, TimestepBlock):# x = layer(x, emb)# elif isinstance(layer, (SpatialTransformer, VanillaTemporalModule)):# x = layer(x, context)# else:# x = layer(x)# return x# TimestepEmbedSequential.forward = mm_tes_forwardif self.mm.using_v2:logger.info(f"Injecting motion module {model_name} into SD1.5 UNet middle block.")# unet.middle_block.insert(-1, self.mm.mid_block.motion_modules[0])# unet.middle_block.add_module('new_module', self.mm.mid_block.motion_modules[0])# unet.middle_block.appendself.mm.mid_block.motion_modules[0])unet.middle_block = unet.middle_block[0:-1].append(self.mm.mid_block.motion_modules[0]).append(unet.middle_block[-1])# n = len(unet.middle_block._modules)# index = -1# if index < 0:# index += n# for i in range(n, index, -1):# unet.middle_block._modules[str(i)] = unet.middle_block._modules[str(i - 1)]# unet.middle_block._modules[str(index)] = unet.middle_blockelse:logger.info(f"Hacking GroupNorm32 forward function.")def groupnorm32_mm_forward(self, x):x = rearrange(x, "(b f) c h w -> b c f h w", b=2)x = gn32_original_forward(self, x)x = rearrange(x, "b c f h w -> (b f) c h w", b=2)return xGroupNorm32.forward = groupnorm32_mm_forwardlogger.info(f"Injecting motion module {model_name} into SD1.5 UNet input blocks.")for mm_idx, unet_idx in enumerate([1, 2, 4, 5, 7, 8, 10, 11]):mm_idx0, mm_idx1 = mm_idx // 2, mm_idx % 2unet.input_blocks[unet_idx].append(self.mm.down_blocks[mm_idx0].motion_modules[mm_idx1])logger.info(f"Injecting motion module {model_name} into SD1.5 UNet output blocks.")for unet_idx in range(12):mm_idx0, mm_idx1 = unet_idx // 3, unet_idx % 3if unet_idx % 3 == 2 and unet_idx != 11:# unet.output_blocks[unet_idx].insert(# -1, self.mm.up_blocks[mm_idx0].motion_modules[mm_idx1]# )# unet.output_blocks[unet_idx].add_module('new_module', self.mm.up_blocks[mm_idx0].motion_modules[mm_idx1])# unet.output_blocks[unet_idx].append(self.mm.up_blocks[mm_idx0].motion_modules[mm_idx1])unet.output_blocks[unet_idx] = unet.output_blocks[unet_idx][0:-1].append(self.mm.up_blocks[mm_idx0].motion_modules[mm_idx1]).append(unet.output_blocks[unet_idx][-1])else:unet.output_blocks[unet_idx].append(self.mm.up_blocks[mm_idx0].motion_modules[mm_idx1])self._set_ddim_alpha(sd_model)self._set_layer_mapping(sd_model)logger.info(f"Injection finished.")def restore(self, sd_model):self._restore_ddim_alpha(sd_model)unet = sd_model.model.diffusion_modellogger.info(f"Removing motion module from SD1.5 UNet input blocks.")for unet_idx in [1, 2, 4, 5, 7, 8, 10, 11]:# unet.input_blocks[unet_idx].pop(-1)unet.input_blocks[unet_idx] = unet.input_blocks[unet_idx][:-1]logger.info(f"Removing motion module from SD1.5 UNet output blocks.")for unet_idx in range(12):if unet_idx % 3 == 2 and unet_idx != 11:# unet.output_blocks[unet_idx].pop(-2)unet.output_blocks[unet_idx] = unet.output_blocks[unet_idx][:-2].append(unet.output_blocks[unet_idx][-1])else:# unet.output_blocks[unet_idx].pop(-1)unet.output_blocks[unet_idx] = unet.output_blocks[unet_idx][:-1]if self.mm.using_v2:logger.info(f"Removing motion module from SD1.5 UNet middle block.")# unet.middle_block.pop(-2)unet.middle_block = unet.middle_block[:-2].append(unet.middle_block[-1])else:logger.info(f"Restoring GroupNorm32 forward function.")GroupNorm32.forward = self.gn32_original_forward# TimestepEmbedSequential.forward = self.tes_original_forwardlogger.info(f"Removal finished.")if shared.cmd_opts.lowvram:self.unload()
sdxl模型适配
在选择sdxl模型时,会收到如下报错:
AssertionError: We do not support vanilla attention in 1.12.1+cu102 anymore, as it is too expensive. Please install xformers via e.g. 'pip install xformers==0.0.16'
然后就会自动下载模型,但由于hugging face的连接问题,会报这种错误:
requests.exceptions.ConnectTimeout: (MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/resolve/main/open_clip_pytorch_model.bin (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7fc89a4438b0>, 'Connection to huggingface.co timed out. (connect timeout=10)'))"), '(Request ID: 9f90780e-6ae0-4531-83df-2f5052c4a1a3)')
这时就需要把所有下不了的模型下载到本地,然后把代码里的version由模型名称改成模型路径,例如将repositories/generative-models/configs/inference/sd_xl_base.yaml中的version: laion2b_s39b_b160k改成本地的/models/hugfac/CLIP-ViT-bigG-14-laion2B-39B-b160k/open_clip_pytorch_model.bin
但到这里还没完,为了能正常运行,需要在代码里把对于xformer的检查相关Assert部分注释掉,并重新实现repositories/generative-models/sgm/modules/diffusionmodules/model.py中的attention函数:
def attention(self, h_: torch.Tensor) -> torch.Tensor:h_ = self.norm(h_)q = self.q(h_)k = self.k(h_)v = self.v(h_)# compute attentionB, C, H, W = q.shapeq, k, v = map(lambda x: rearrange(x, "b c h w -> b (h w) c"), (q, k, v))q, k, v = map(lambda t: t.unsqueeze(3).reshape(B, t.shape[1], 1, C).permute(0, 2, 1, 3).reshape(B * 1, t.shape[1], C).contiguous(),(q, k, v),)# out = xformers.ops.memory_efficient_attention(# q, k, v, attn_bias=None, op=self.attention_op# )k = k / (k.shape[-1] ** 0.5)attn = torch.matmul(q, k.transpose(-2, -1))attn = torch.softmax(attn, dim=-1)out = torch.matmul(attn, v)out = (out.unsqueeze(0).reshape(B, 1, out.shape[1], C).permute(0, 2, 1, 3).reshape(B, out.shape[1], C))return rearrange(out, "b (h w) c -> b c h w", b=B, h=H, w=W, c=C)
Stable Diffusion使用
插件安装
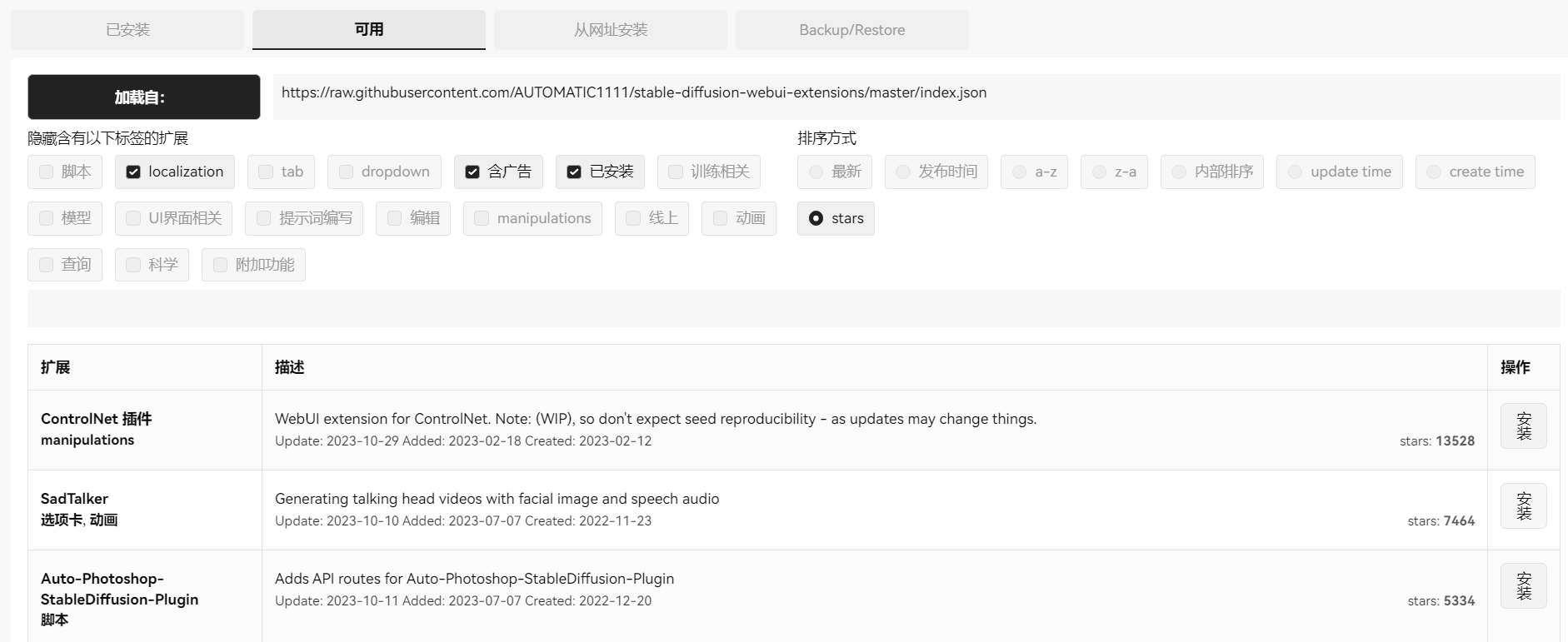
点击扩展→可用→简单粗暴按星数排序:
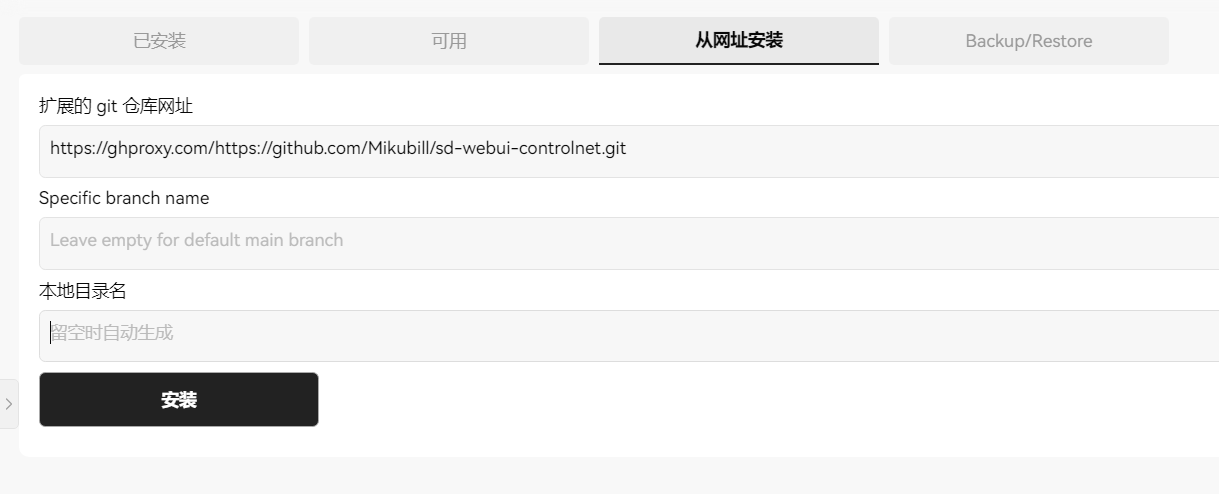
如果github无法访问,可以复制链接后前面加上https://ghproxy.com/从网址安装:
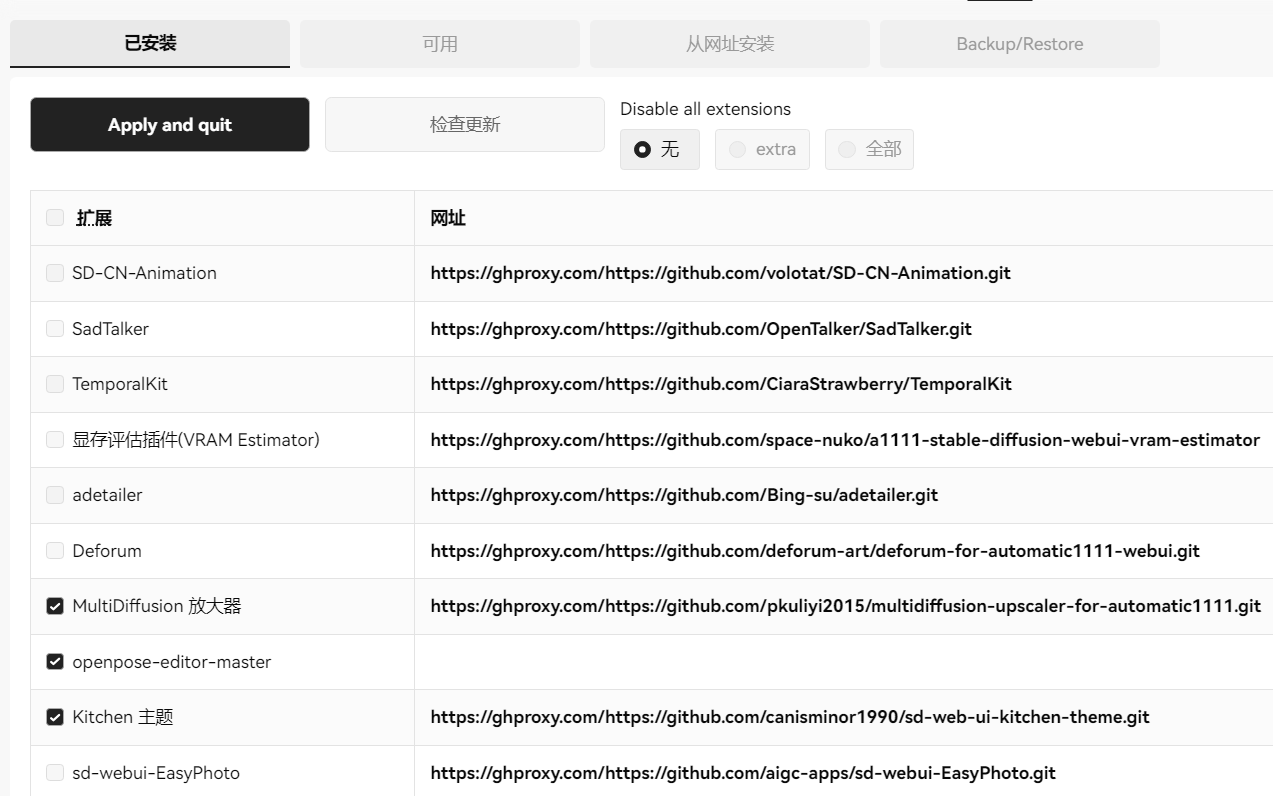
最终安装的部分插件如下,注意需要手动把插件模型下载到对应路径下才能使用:
界面设置
在设置→用户界面中对快捷设置和UItab做修改:
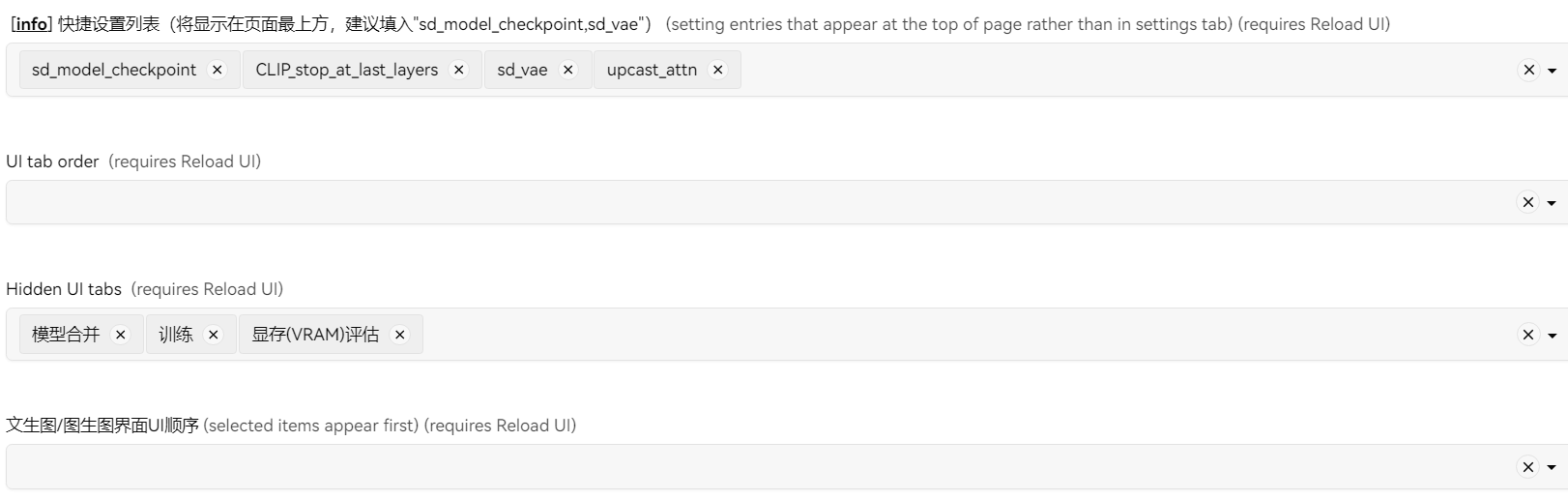
点击右上角设置kitchen插件主题:
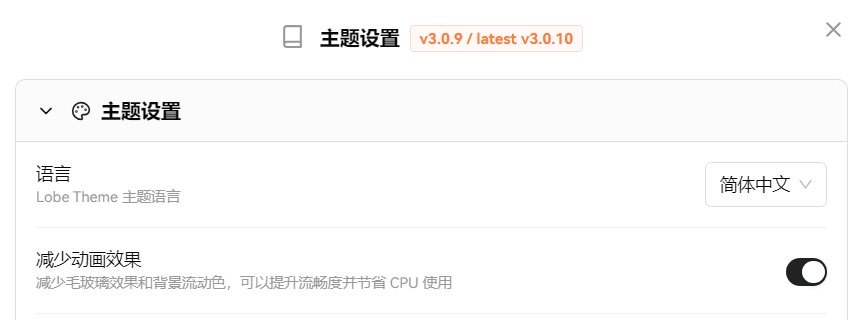
最终效果如下:
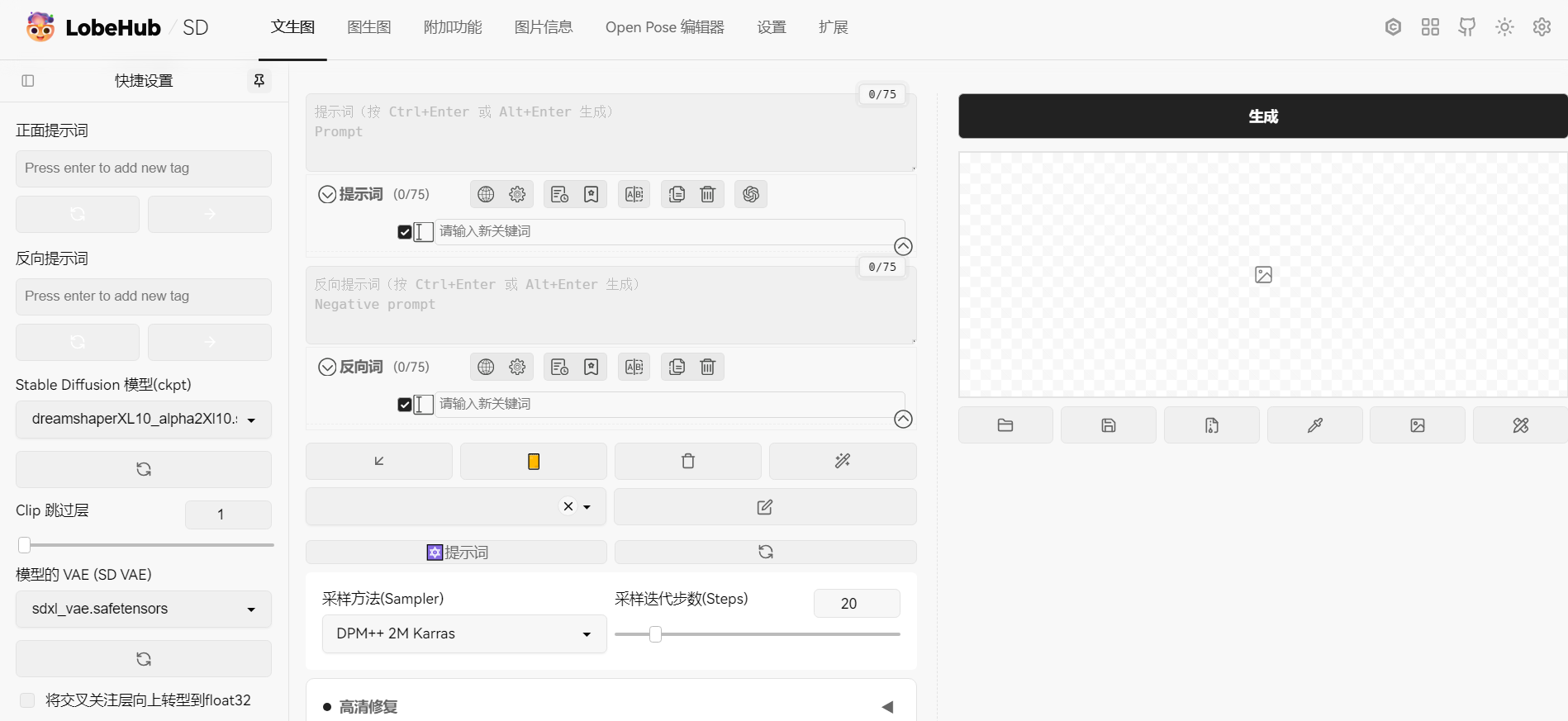
基础文生图
首先在模型左侧选择Stable Diffusion模型及其对应VAE,然后输入正向和反向提示词,在下面点击生成相关设置如采样方法、采样迭代次数和宽高等。
需要注意的几点:
- Clip跳过层设置:CLIP 是用来给提示词编码的神经网络,默认是使用模型最后一层的输出作为提示词的嵌入表示,将其设为2就可以使用模型倒数第二层的输出作为嵌入表示。增加这一参数时,可以更好地保留提示中的信息,生成与提示更匹配的图片,但设置的值过大也会影响编码的准确性。该参数仅适用于使用CLIP的模型,即1.x模型及其派生物。2.0模型及其派生物不与CLIP交互,因为它们使用OpenCLIP。
- 将交叉关注层向上转型到float32设置:遇到NAN报错或者花屏图片时可以试试。
- 图片大小设置:对于SDXL模型,为了保证生成质量图片至少为1024x1024
- 16:9(电影摄影)1820x1024
- 3:2(专业摄影)1536x1024
- 4:3(普通图片)1365x1024
- 采样方法:对SDXL 1.0来说,建议使用任何DPM++采样器,特别是带有Karras采样器的DPM++。比如DPM++ 2M Karras或DPM++ 2S a Karras
生成示例如下:
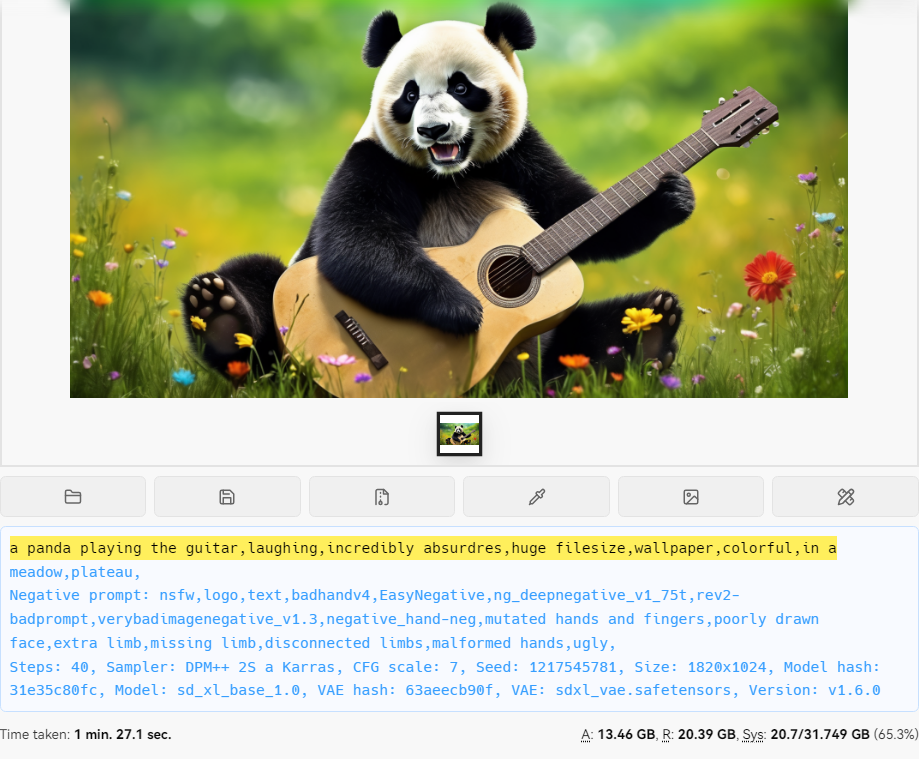
加入lora的文生图
lora是一类对模型进行微调的方法,是一系列参数量较小的模型,在与原始模型结合后,可以对生成图片做特定修饰,可以理解为化妆技术。
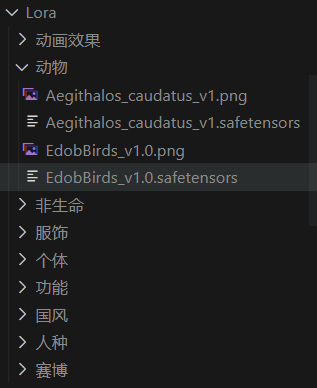
lora的使用方法是将模型下载到models/Lora文件夹下,注意最好分文件夹存放,方便调用和管理:
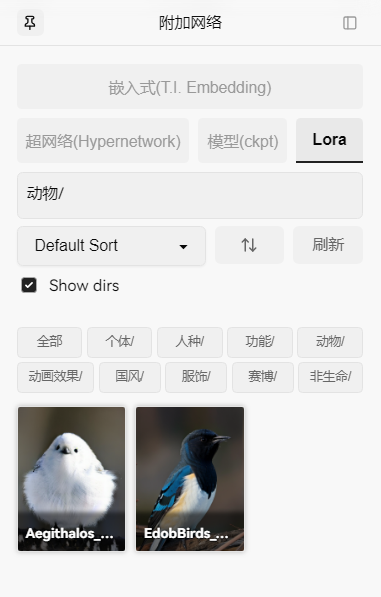
对应的前端界面如下:
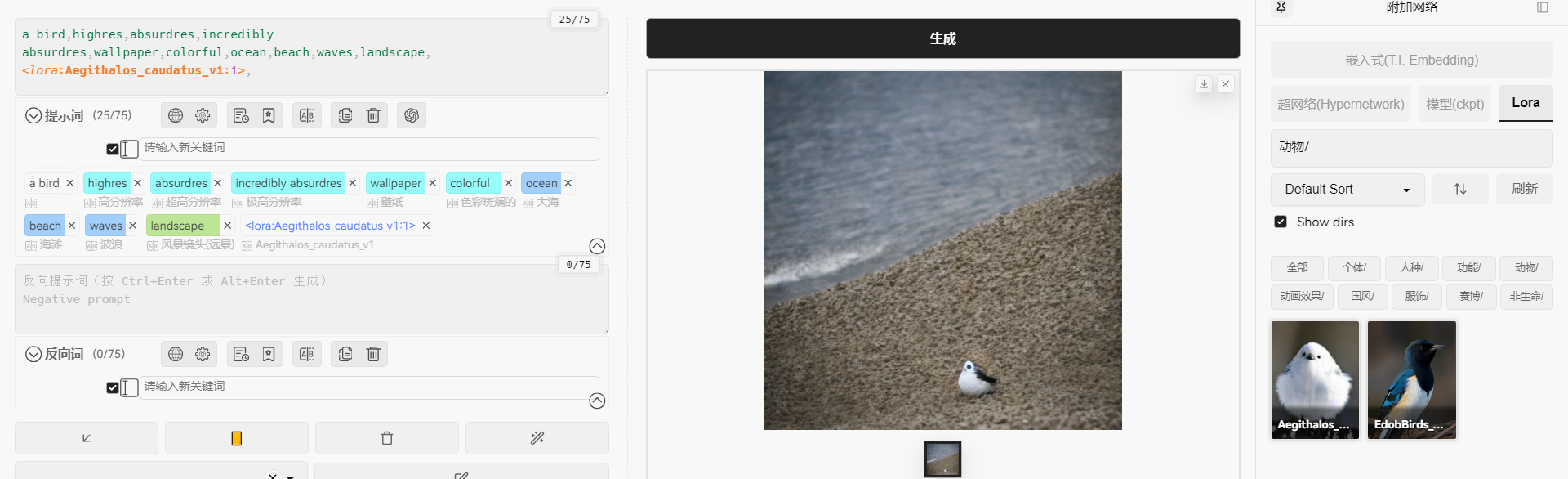
使用方法很简单,在输入提示词后直接点击lora模型,就会自动添加到输入末尾:
99%的人还看了
相似问题
- 最新AIGC创作系统ChatGPT系统源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图,图片对话理解功能
- 思维模型 等待效应
- FinGPT:金融垂类大模型架构
- 人工智能基础_机器学习044_使用逻辑回归模型计算逻辑回归概率_以及_逻辑回归代码实现与手动计算概率对比---人工智能工作笔记0084
- Pytorch完整的模型训练套路
- Doris数据模型的选择建议(十三)
- python自动化标注工具+自定义目标P图替换+深度学习大模型(代码+教程+告别手动标注)
- ChatGLM2 大模型微调过程中遇到的一些坑及解决方法(更新中)
- Python实现WOA智能鲸鱼优化算法优化随机森林分类模型(RandomForestClassifier算法)项目实战
- 扩散模型实战(十一):剖析Stable Diffusion Pipeline各个组件
猜你感兴趣
版权申明
本文"Stable Diffusion系列(一):古早显卡上最新版 WebUI 安装及简单操作":http://eshow365.cn/6-27862-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!