已解决
吃瓜教程2|线性模型
来自网友在路上 164864提问 提问时间:2023-10-25 00:39:48阅读次数: 64
最佳答案 问答题库648位专家为你答疑解惑
线性回归

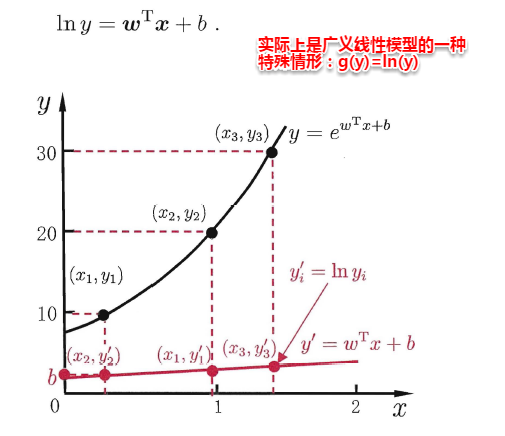
“广义的线性模型”(generalized linear model),其中,g(*)称为联系函数(link function)。
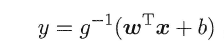
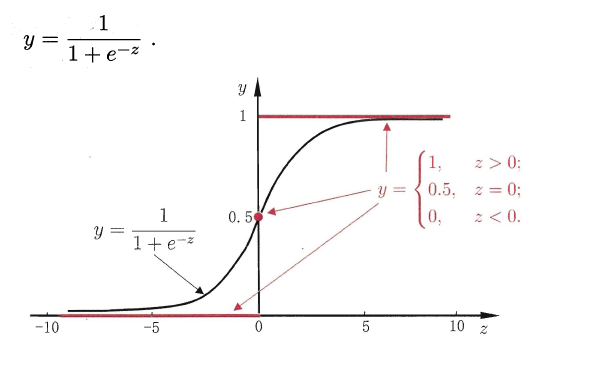
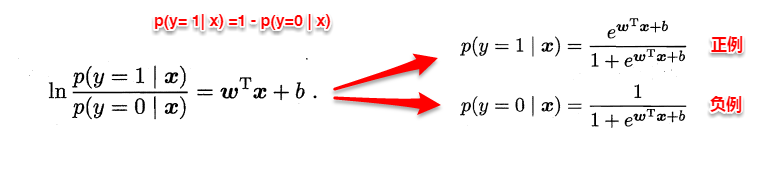
线性几率回归(逻辑回归)
线性判别分析
想让同类样本点的投影点尽可能接近,不同类样本点投影之间尽可能远,即:让各类的协方差之和尽可能小,不用类之间中心的距离尽可能大。基于这样的考虑,LDA定义了两个散度矩阵。
- 类内散度矩阵(within-class scatter matrix)

- 类间散度矩阵(between-class scaltter matrix)
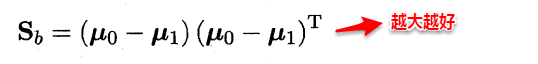
因此得到了LDA的最大化目标:“广义瑞利商”(generalized Rayleigh quotient)。
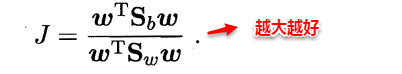
从而分类问题转化为最优化求解w的问题,当求解出w后,对新的样本进行分类时,只需将该样本点投影到这条直线上,根据与各个类别的中心值进行比较,从而判定出新样本与哪个类别距离最近。求解w的方法如下所示,使用的方法为λ乘子。

若将w看做一个投影矩阵,类似PCA的思想,则LDA可将样本投影到N-1维空间(N为类簇数),投影的过程使用了类别信息(标记信息),因此LDA也常被视为一种经典的监督降维技术。
类别不平衡问题
类别不平衡(class-imbanlance)就是指分类问题中不同类别的训练样本相差悬殊的情况,例如正例有900个,而反例只有100个,这个时候我们就需要进行相应的处理来平衡这个问题。常见的做法有三种:
- 在训练样本较多的类别中进行“欠采样”(undersampling),比如从正例中采出100个,常见的算法有:EasyEnsemble。
- 在训练样本较少的类别中进行“过采样”(oversampling),例如通过对反例中的数据进行插值,来产生额外的反例,常见的算法有SMOTE。
- 直接基于原数据集进行学习,对预测值进行“再缩放”处理。其中再缩放也是代价敏感学习的基础。
查看全文
99%的人还看了
相似问题
- 斯坦福机器学习 Lecture2 (假设函数、参数、样本等等术语,还有批量梯度下降法、随机梯度下降法 SGD 以及它们的相关推导,还有正态方程)
- 340条样本就能让GPT-4崩溃,输出有害内容高达95%?OpenAI的安全防护措施再次失效
- FSOD论文阅读 - 基于卷积和注意力机制的小样本目标检测
- 数智竞技何以成为“科技+体育”新样本?
- [深度学习]不平衡样本的loss
- Python实战:绘制直方图的示例代码,数据可视化获取样本分布特征
- 某汽车金融企业:搭建SDLC安全体系,打造智慧金融服务样本
- 计算样本方差和总体方差
- 小样本分割的新视角,Learning What Not to Segment【CVPR 2022】
- 学习笔记|两独立样本秩和检验|曼-惠特尼 U数据分布图|规范表达|《小白爱上SPSS》课程:SPSS第十二讲 | 两独立样本秩和检验如何做?
猜你感兴趣
版权申明
本文"吃瓜教程2|线性模型":http://eshow365.cn/6-23737-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 读书笔记之《敏捷测试从零开始》(一)
- 下一篇: 爱创科技携手洽洽食品,探索渠道数字化最优解!