已解决
金融机器学习方法:K-均值算法
来自网友在路上 190890提问 提问时间:2023-10-23 12:26:11阅读次数: 90
最佳答案 问答题库908位专家为你答疑解惑
目录
1.算法介绍
2.算法原理
3.python实现示例
1.算法介绍
K均值聚类算法是机器学习和数据分析中常用的无监督学习方法之一,主要用于数据的分类。它的目标是将数据划分为几个独特的、互不重叠的子集或“集群”,以使得同一集群内的数据点彼此相似,而不同集群的数据点则尽可能不同。
2.算法原理
- 选择K个初始质心,这些质心可以是随机选取的数据点或其他方法得到的。
- 根据每个数据点到质心的距离,将其分配给最近的质心,形成K个集群。
- 重新计算每个集群的质心。
- 重复上述步骤,直到质心不再发生变化或达到一定的迭代次数
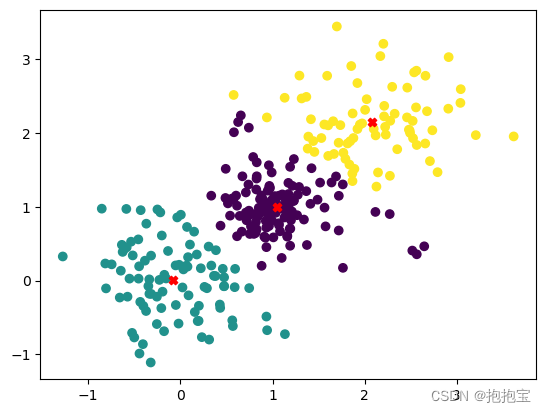
3.python实现示例
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 随机生成数据
np.random.seed(0)
points = np.vstack([np.random.normal(0, 0.5, size=(100, 2)),np.random.normal(1, 0.25, size=(100, 2)),np.random.normal(2, 0.6, size=(100, 2))
])# 使用KMeans进行聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(points)
labels = kmeans.predict(points)
centroids = kmeans.cluster_centers_# 可视化结果
plt.scatter(points[:, 0], points[:, 1], c=labels)
plt.scatter(centroids[:, 0], centroids[:, 1], color='red', marker='X')
plt.show()
结果图:
查看全文
99%的人还看了
猜你感兴趣
版权申明
本文"金融机器学习方法:K-均值算法":http://eshow365.cn/6-22476-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 【API接口功能】以图搜款,最快1秒助您找到想要的商品!
- 下一篇: WebSocket 入门案例