已解决
2023_Spark_实验二十:SparkStreaming累加计算单词频率
来自网友在路上 161861提问 提问时间:2023-10-19 23:05:37阅读次数: 61
最佳答案 问答题库618位专家为你答疑解惑
一、需求分析
在服务器端不断产生数据的时候,sparkstreaming客户端需要不断统计服务器端产生的相同数据出现的总数,即累计服务器端产生的相同数据的出现的次数。
二、实验环境
centos7 + nc + spark2.1.1 + windows + idea
三、思路分析
流程分析

思路分析
每次客户端程序处理服务器端数据后,将其结果缓存在检查点中,下一次客户端读入数据并处理数据时会去检查点根据key查询和进行更新,并重新将结果更新到检查点中。
检查点:本质上就是对应于HDFS上的一个目录,将数据写入到该目录下以文件的形式将结果保存下来。故,需要先在hdfs上创建检查点对应的目录。
四、编程实现
实验步骤:
-
编写客户端处理程序,程序如下
import org.apache.spark.SparkConfimport org.apache.spark.storage.StorageLevelimport org.apache.spark.streaming.{Seconds, StreamingContext}object MyTotalNetworkWordCount {def main(args: Array[String]): Unit = {//创建一个Context对象: StreamingContext (SparkContext, SQLContext)//指定批处理的时间间隔val conf = newSparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")val ssc = new StreamingContext(conf,Seconds(5))//设置检查点ssc.checkpoint("file:///d:/temp/checkpoint")//创建一个DStream,处理数据,hadoop001为虚拟机的主机名,端口号为netcat服务的端口号val lines = ssc.socketTextStream("192.168.245.110",1234,StorageLevel.MEMORY_AND_DISK_SER)//执行wordcountval words = lines.flatMap(_.split(" "))//定义函数用于累计每个单词的总频率val addFunc = (currValues: Seq[Int], prevValueState: Option[Int]) => {//通过Spark内部的reduceByKey按key规约,然后这里传入某key当前批次的Seq/List,再计算当前批次的总和val currentCount = currValues.sum// 已累加的值val previousCount = prevValueState.getOrElse(0)// 返回累加后的结果,是一个Option[Int]类型Some(currentCount + previousCount)}val pairs = words.map(word => (word, 1))val totalWordCounts = pairs.updateStateByKey[Int](addFunc)totalWordCounts.print()ssc.start()ssc.awaitTermination()}}-
运行程序
-
在Linux中启动nc: nc -l 1234
-
输入测试数据,每输入一次数据执行一次回车:
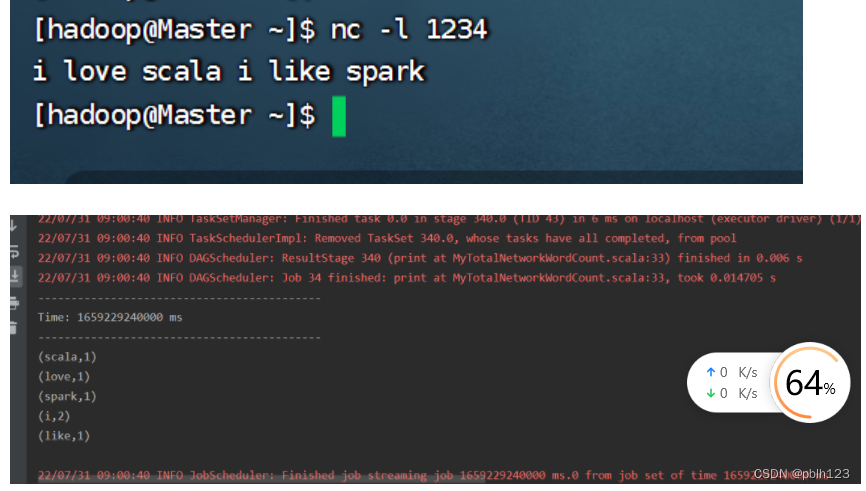
查看下检查点是否有数据:
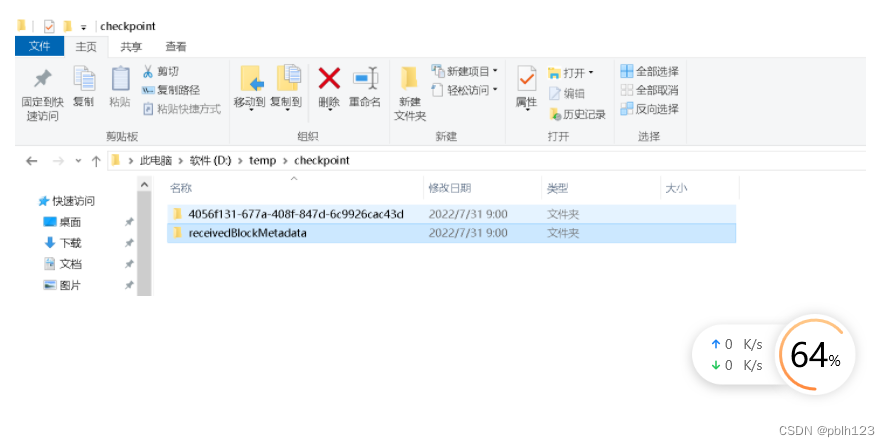
查看全文
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"2023_Spark_实验二十:SparkStreaming累加计算单词频率":http://eshow365.cn/6-19882-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!