PPO算法逐行代码详解
最佳答案 问答题库658位专家为你答疑解惑
前言:本文会从理论部分、代码部分、实践部分三方面进行PPO算法的介绍。其中理论部分会介绍PPO算法的推导流程,代码部分会给出PPO算法的各部分的代码以及简略介绍,实践部分则会通过debug代码调试的方式从头到尾的带大家看清楚应用PPO算法在cartpole环境上进行训练的整体流程,进而帮助大家将理论与代码实践相结合,更好的理解PPO算法。
文章目录
- 1. 理论部分
- 2. 代码部分
- 2.1 神经网络的定义
- 2.2 PPO算法的定义
- 2.3 on policy算法的训练代码
- 3. 实践部分
1. 理论部分
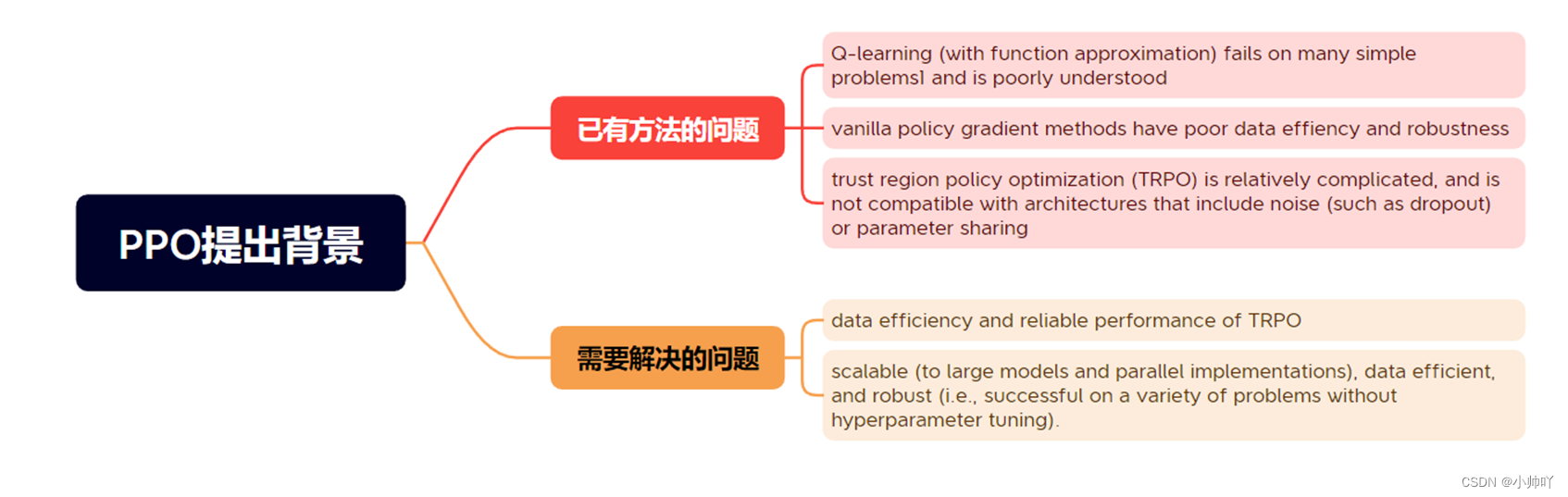
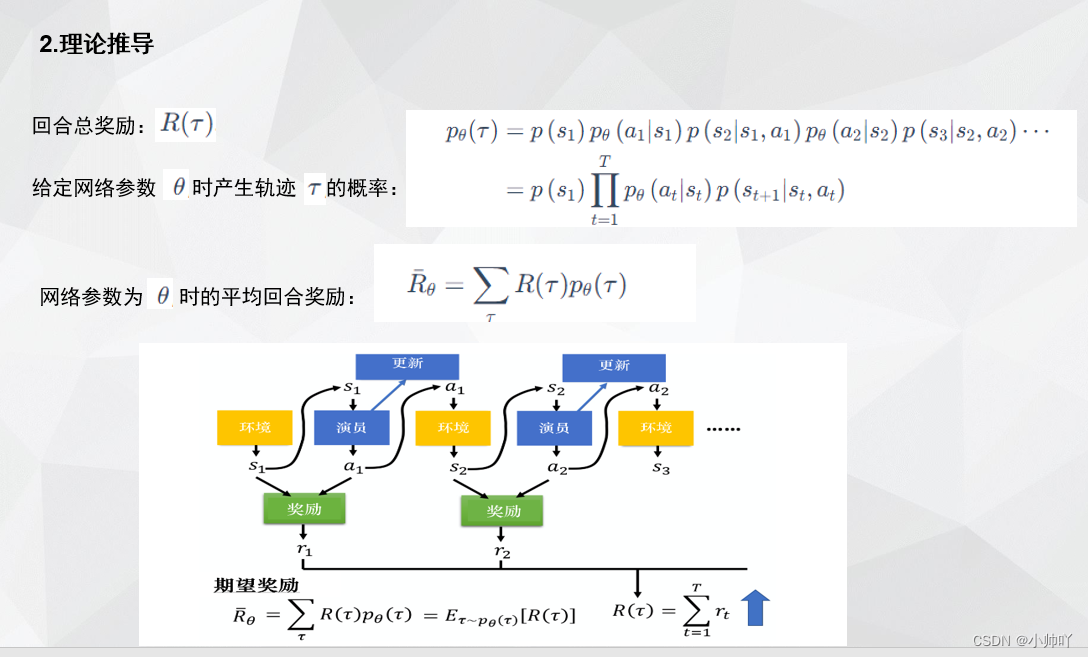
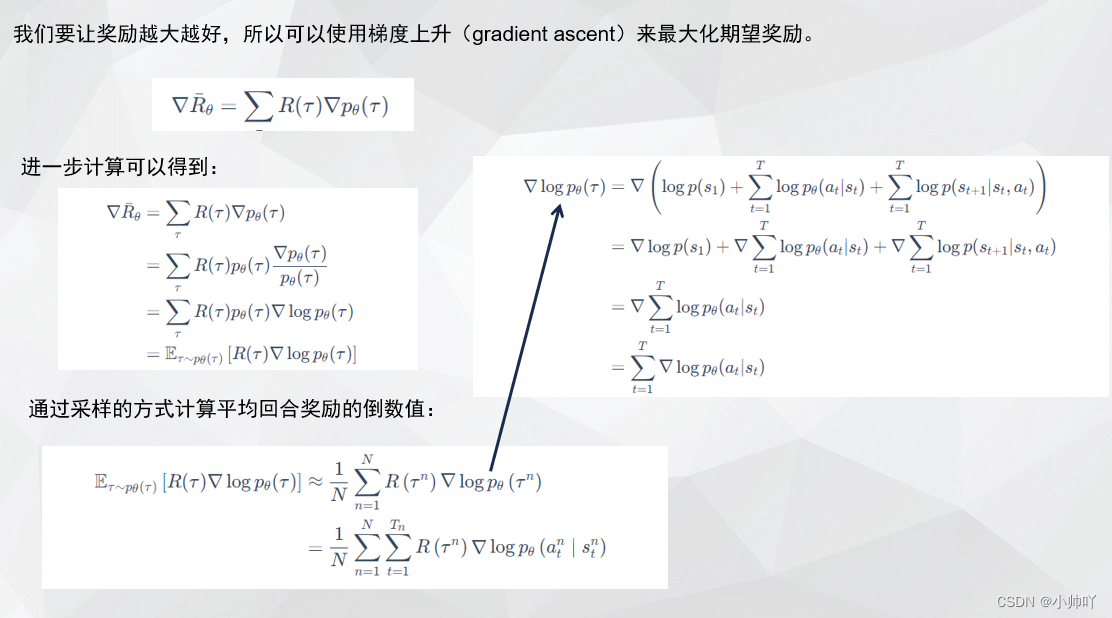
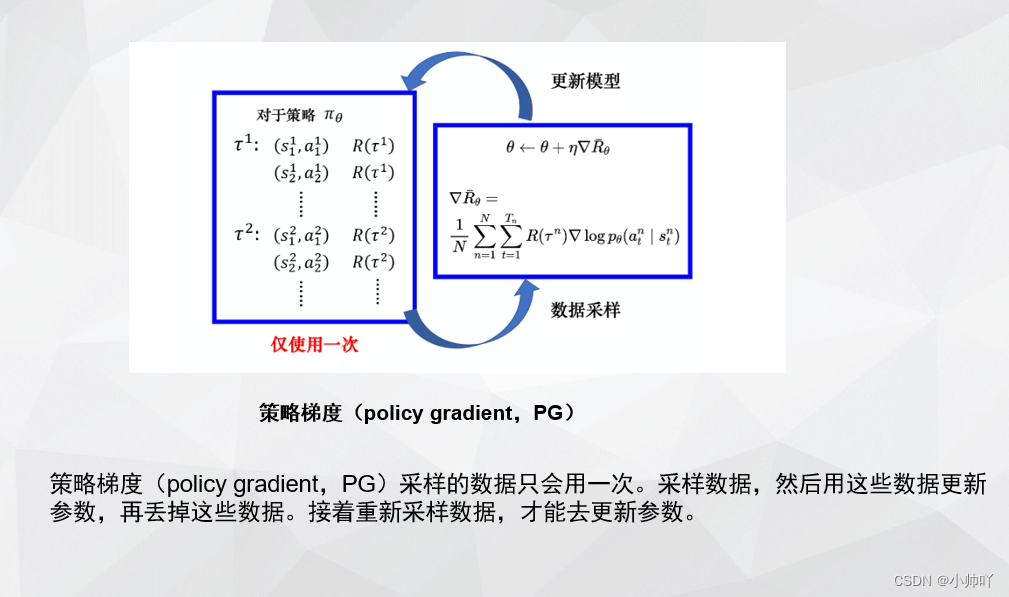
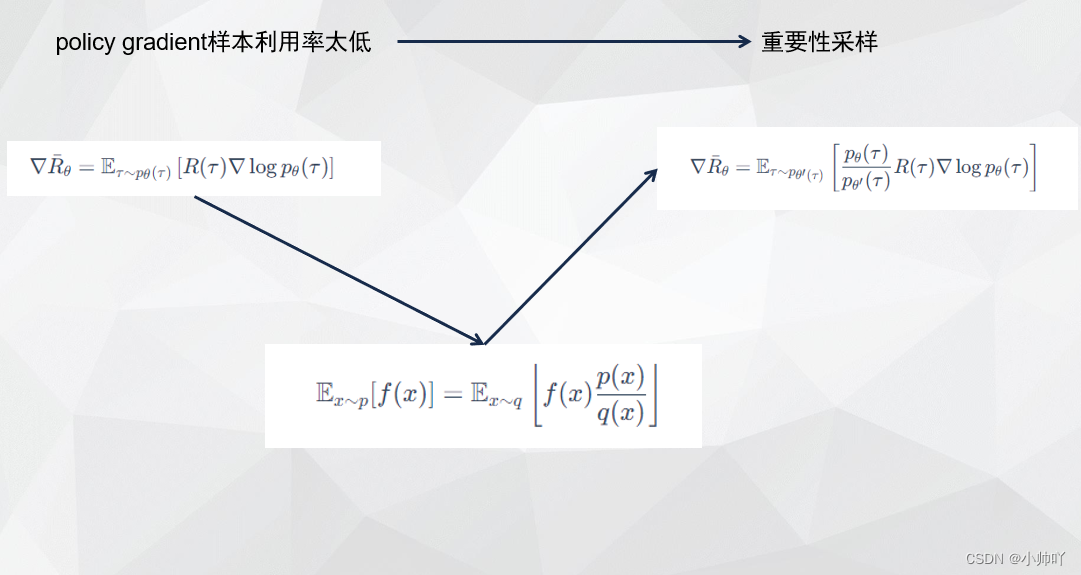
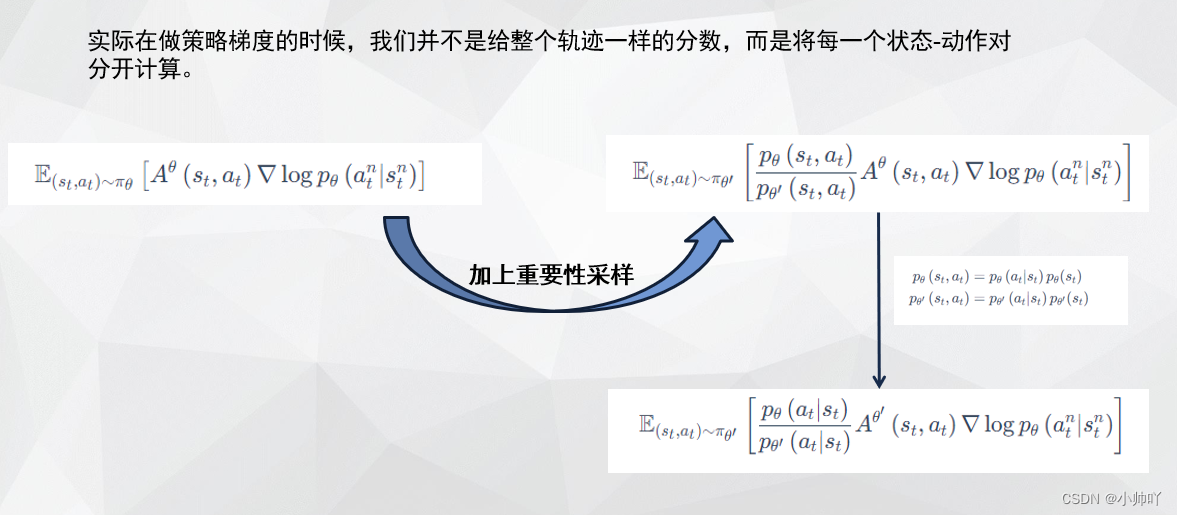
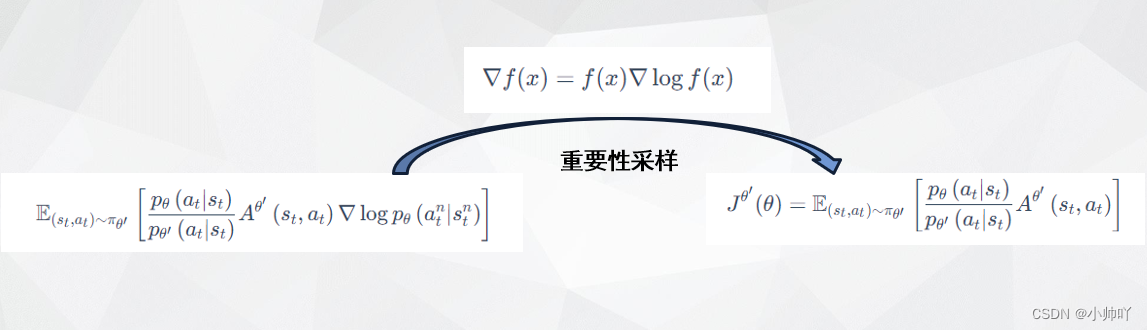
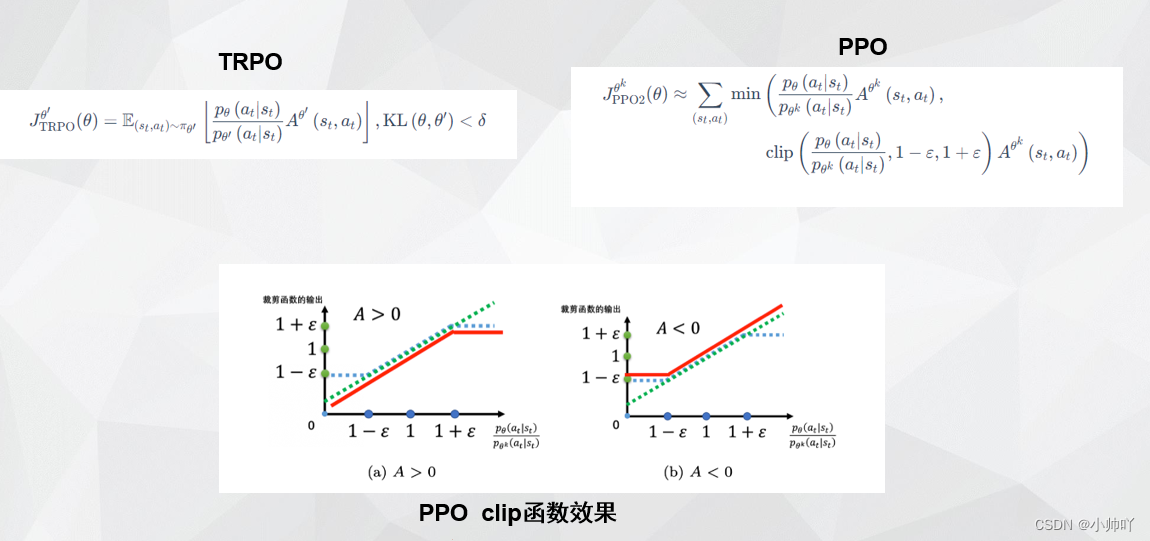


2. 代码部分
这里使用的是《动手学强化学习》中提供的代码,我将这本书中的代码整理到了github上,并且方便使用pycharm进行运行和调试。代码地址:https://github.com/zxs-000202/dsx-rl
代码核心部分整体上可以分为三部分,分别是关于神经网络的类的定义(PolicyNet,ValueNet),关于PPO算法的类的定义(PPO),on policy算法训练流程的定义(train_on_policy_agent)。
2.1 神经网络的定义
策略网络actor采用两层全连接层,第一层采用relu激活函数,第二层采用softmax函数。
class PolicyNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, action_dim)def forward(self, x):x = F.relu(self.fc1(x))return F.softmax(self.fc2(x), dim=1)
价值网络critic采用两层全连接层,第一层和第二层均采用relu激活函数,第二层最后输出的维度是1,表示t时刻某个状态s的价值V。
class ValueNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim):super(ValueNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, 1)def forward(self, x):x = F.relu(self.fc1(x))return self.fc2(x)
2.2 PPO算法的定义
这部分是PPO算法最核心的部分。本部分包括神经网络的初始化、相关参数的定义,如何根据状态s选择动作,以及网络参数是如何更新的。整体的代码如下:
class PPO:''' PPO算法,采用截断方式 '''def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,lmbda, epochs, eps, gamma, device):self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)self.critic = ValueNet(state_dim, hidden_dim).to(device)self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),lr=actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),lr=critic_lr)self.gamma = gammaself.lmbda = lmbdaself.epochs = epochs # 一条序列的数据用来训练轮数self.eps = eps # PPO中截断范围的参数self.device = devicedef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(self.device)probs = self.actor(state)action_dist = torch.distributions.Categorical(probs)action = action_dist.sample()return action.item()def update(self, transition_dict):states = torch.tensor(transition_dict['states'],dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)rewards = torch.tensor(transition_dict['rewards'],dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(transition_dict['next_states'],dtype=torch.float).to(self.device)dones = torch.tensor(transition_dict['dones'],dtype=torch.float).view(-1, 1).to(self.device)td_target = rewards + self.gamma * self.critic(next_states) * (1 -dones)td_delta = td_target - self.critic(states)advantage = rl_utils.compute_advantage(self.gamma, self.lmbda,td_delta.cpu()).to(self.device)old_log_probs = torch.log(self.actor(states).gather(1,actions)).detach()for _ in range(self.epochs):log_probs = torch.log(self.actor(states).gather(1, actions))ratio = torch.exp(log_probs - old_log_probs)surr1 = ratio * advantagesurr2 = torch.clamp(ratio, 1 - self.eps,1 + self.eps) * advantage # 截断actor_loss = torch.mean(-torch.min(surr1, surr2)) # PPO损失函数critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward()critic_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()
2.3 on policy算法的训练代码
我们知道on policy算法与off policy算法的区别就在与进行采样的网络和用来参数更新的训练网络是否是一个网络。PPO是一种on policy的算法,on policy算法要求训练的网络参数一更新就需要重新进行采样然后训练。但PPO有点特殊,它是利用重要性采样方法来实现数据的多次利用,提高了数据的利用效率。
从下面的代码中可以看到每当一个episode的数据采样完毕之后都会执行agent.update(transition_dict)。在update中会将当前采样得到的数据(也就是当前episode的每个t时刻的 [ 当前状态,动作,奖励,是否结束,下一个状态 ] 这个五元组)通过重要性采样的方法进行多次的神经网络参数的更新,这个具体过程我会在第三部分实践部分进行详细说明。
def train_on_policy_agent(env, agent, num_episodes):return_list = []for i in range(10):with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:for i_episode in range(int(num_episodes / 10)):episode_return = 0transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}state = env.reset()done = Falsewhile not done:action = agent.take_action(state)next_state, reward, done, _ = env.step(action)transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)state = next_stateepisode_return += rewardreturn_list.append(episode_return)agent.update(transition_dict)if (i_episode + 1) % 10 == 0:pbar.set_postfix({'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),'return': '%.3f' % np.mean(return_list[-10:])})pbar.update(1)return return_list
3. 实践部分
该部分带领大家从代码运行流程上从头到尾过一遍。
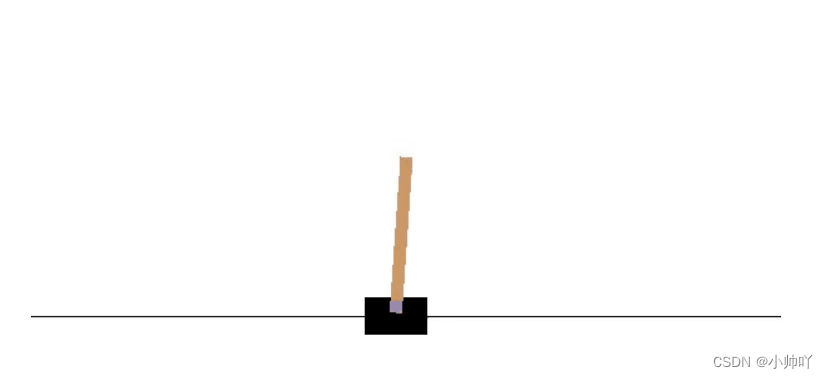
本次PPO算法训练应用的gym环境是CartPole-v0,如下图。该gym环境的状态空间是四个连续值用来表示杆所处的状态,而动作空间是两个离散值用来表示给杆施加向左或者向右的力(也就是action为0或者1)。
代码中前面的部分是网络、算法、训练参数的定义,真正开始训练是在return_list = rl_utils.train_on_policy_agent(env, agent, num_episodes)。我们在这里打一个断点进行调试。
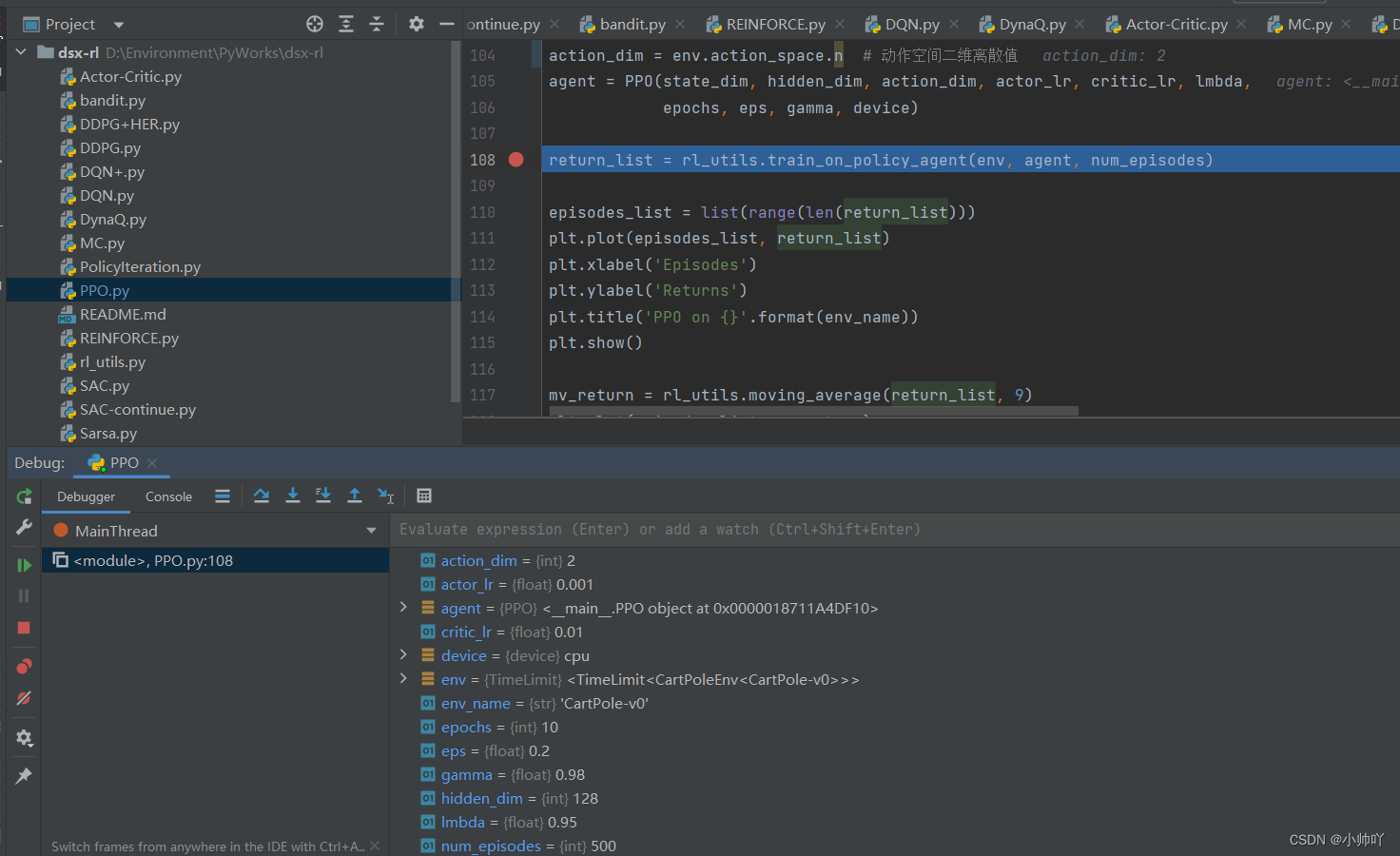
比较重要的训练参数是episode为500,epoch为10。表示一共采样500个episode的数据,每个episode数据采样完毕后再update阶段进行10次的梯度下降参数更新。
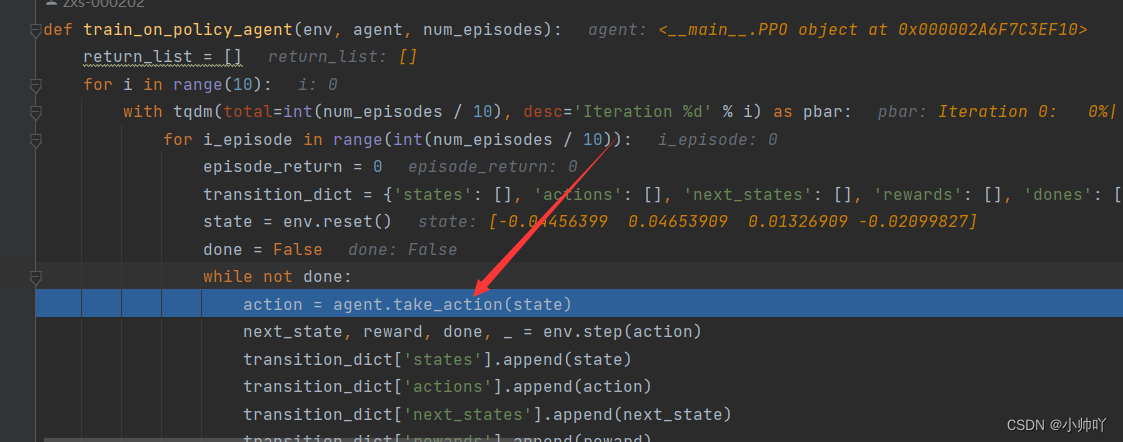
执行到这里我们跳到take_action里面看看agent是如何选取动作的。

可以看到首先将输入的state转换为tensor,然后因为actor网络的最后一层是softmax函数,所以通过actor网络输出两个执行两个动作可能性的大小,然后通过action_dist = torch.distributions.Categorical(probs) action = action_dist.sample()根据可能性大小进行采样最后得到这次选择动作1进行返回。
第一个episode中我们采样到的数据如下:

可以看到第一个episode执行了41个step之后done了。
接下来我们跳进update函数中看看具体如何用这个episode采样的数据进行神经网络参数的更新。
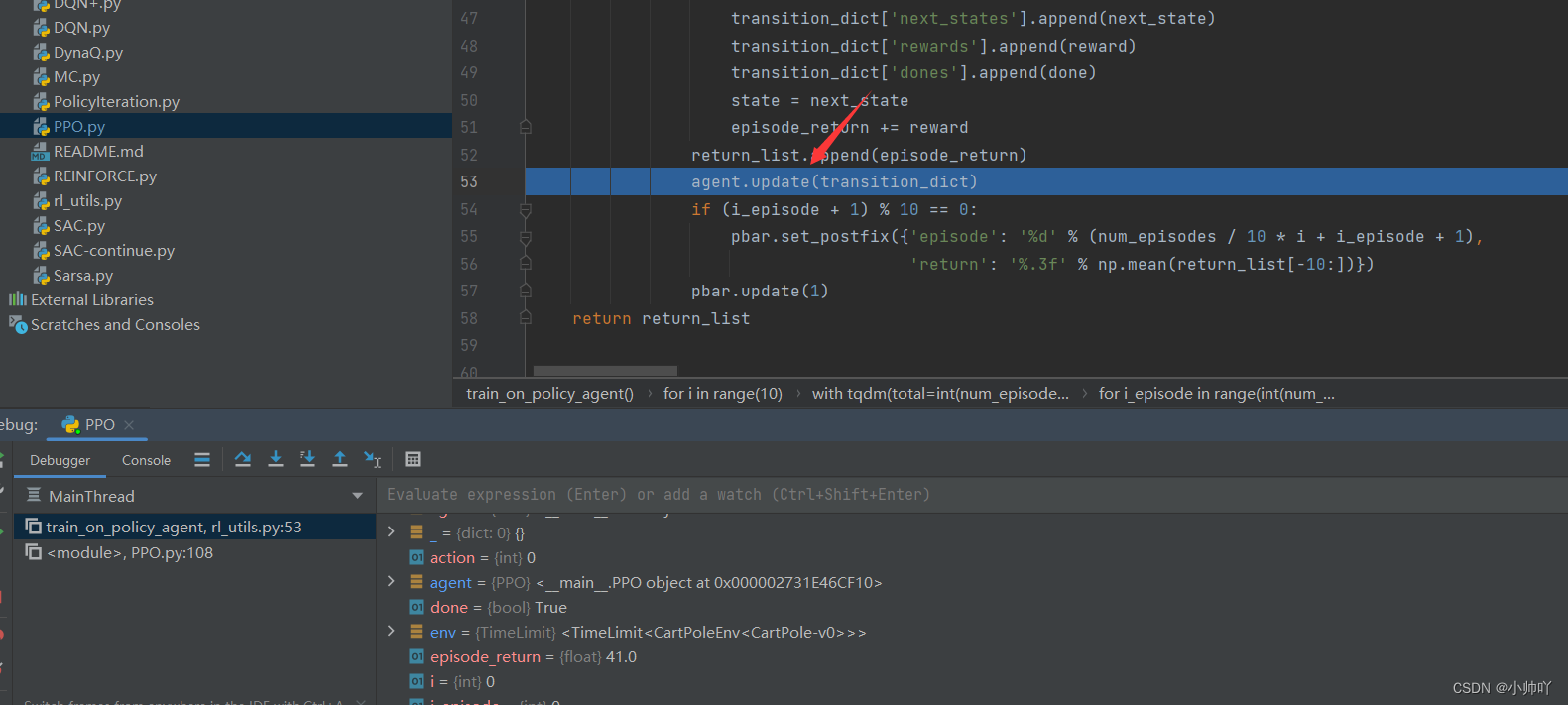
首先从transition_dict中将采样的41个step的数据取出来存到tensor中方便之后进行运算。
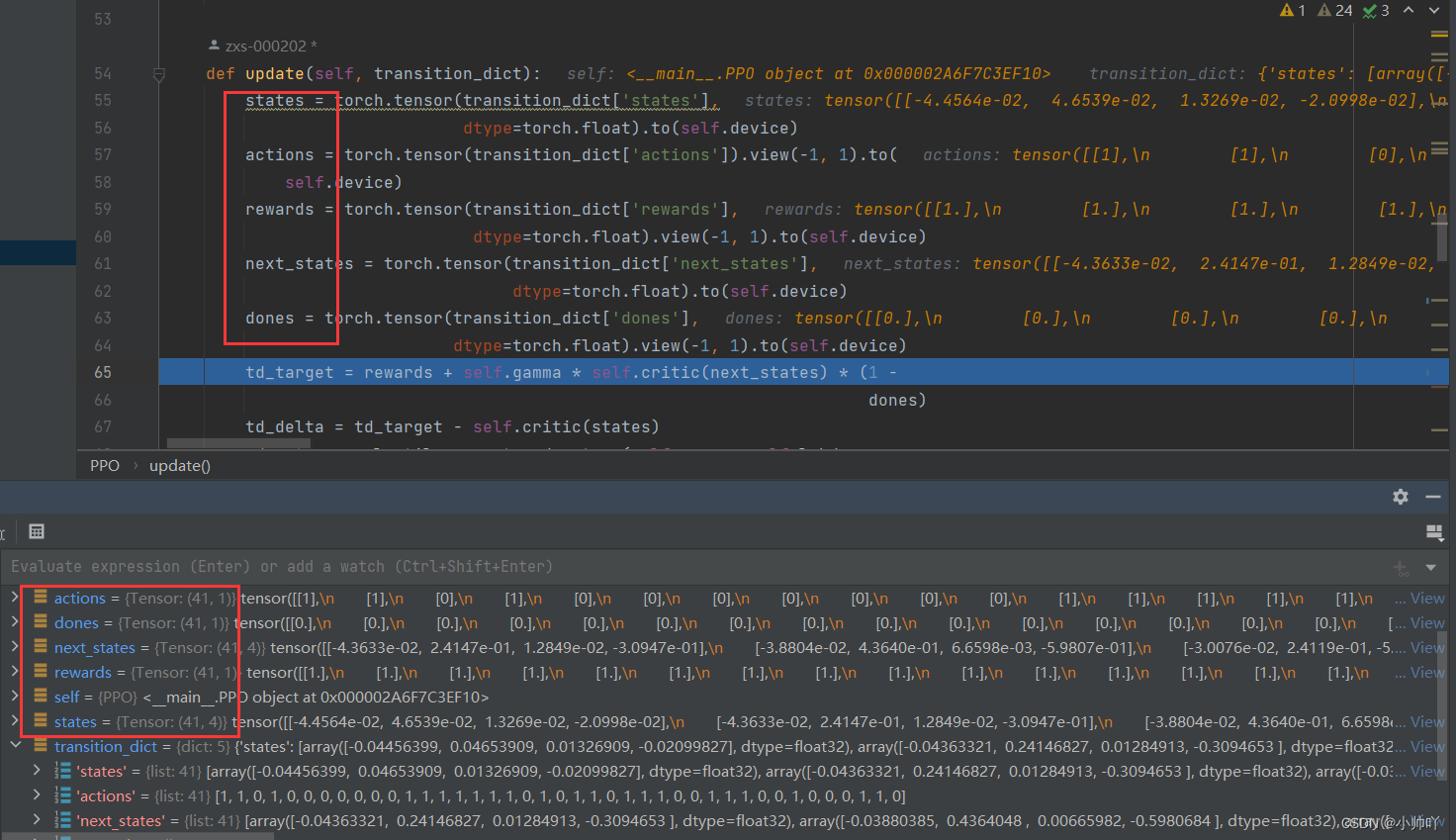
接下来计算td_target,td_delta,advantage,old_log_probs。
其中td_target表示t时刻的得到的奖励值r加上根据t+1时刻critic估计的状态价值V。用公式表示的话就是:
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
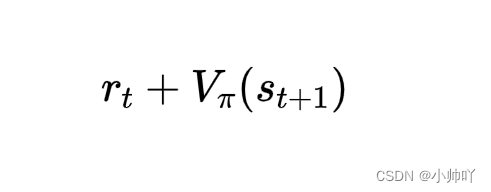
td_delta表示的是td_target和t时刻采用critic估计的状态价值之间的差值。用公式表示的话就是:
td_delta = td_target - self.critic(states)
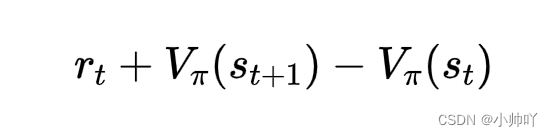
advantage则表示的是某状态下采取某动作的优势值,也就是下面PPO算法公式中的A。
advantage = rl_utils.compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)
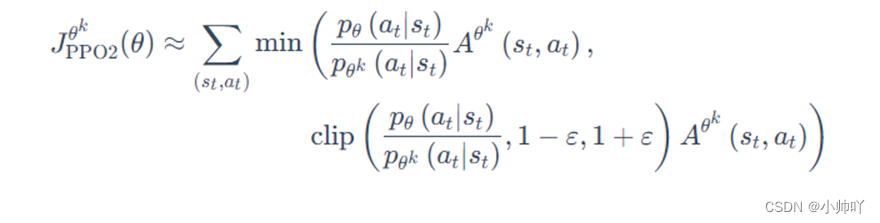
old_log_probs则表示的是旧策略下某个状态下采取某个动作的概率值的对数值。对应下面PPO算法公式中的clip函数中分母。
old_log_probs = torch.log(self.actor(states).gather(1,actions)).detach()
到这里我们计算出这些值的shape如下图所示。接下来我们就要进入一个循环中,循环epoch=10次进行参数的神经网络参数的更新。
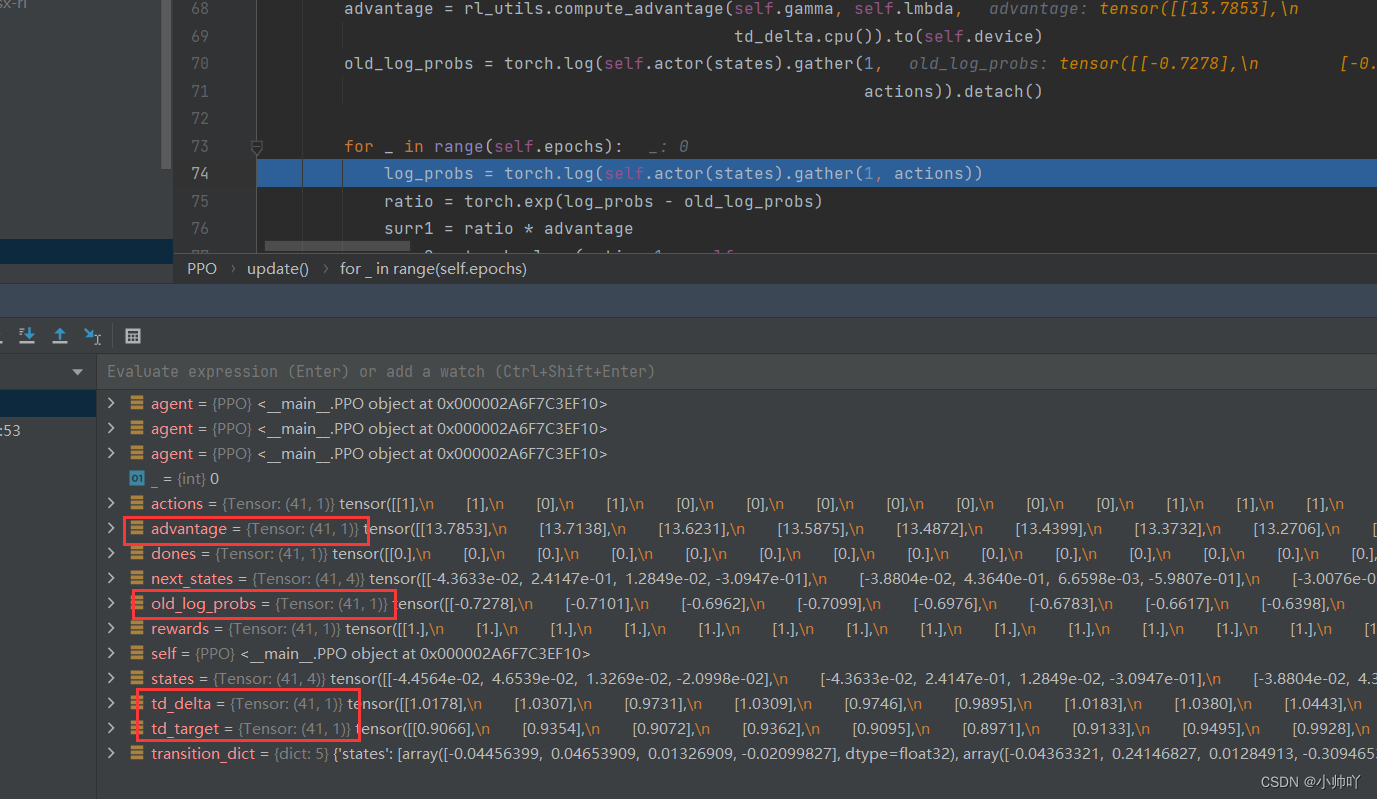
具体而言首先在每个循环中计算一次当前的actor参数下对应的state和action的概率值的对数值,也就是下面分式中的分子。
这里用到的高中对数数学公式有:
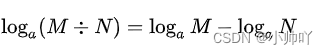
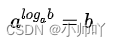
通过上面两个公式可以计算得到
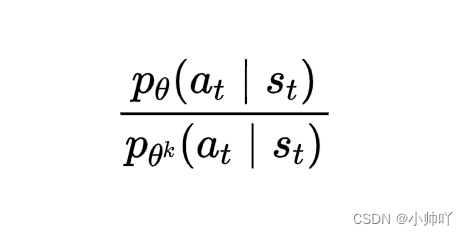
然后计算这个分式的值ratio。
之后结合下面的公式和代码可以看出surr1和surr2分别是下图公式中对应的值。

log_probs = torch.log(self.actor(states).gather(1, actions))
ratio = torch.exp(log_probs - old_log_probs)
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantage # 截断
然后计算actor的loss值和critic的loss值
actor_loss = torch.mean(-torch.min(surr1, surr2)) # PPO损失函数
critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))
计算得到的数据的shape如下图:
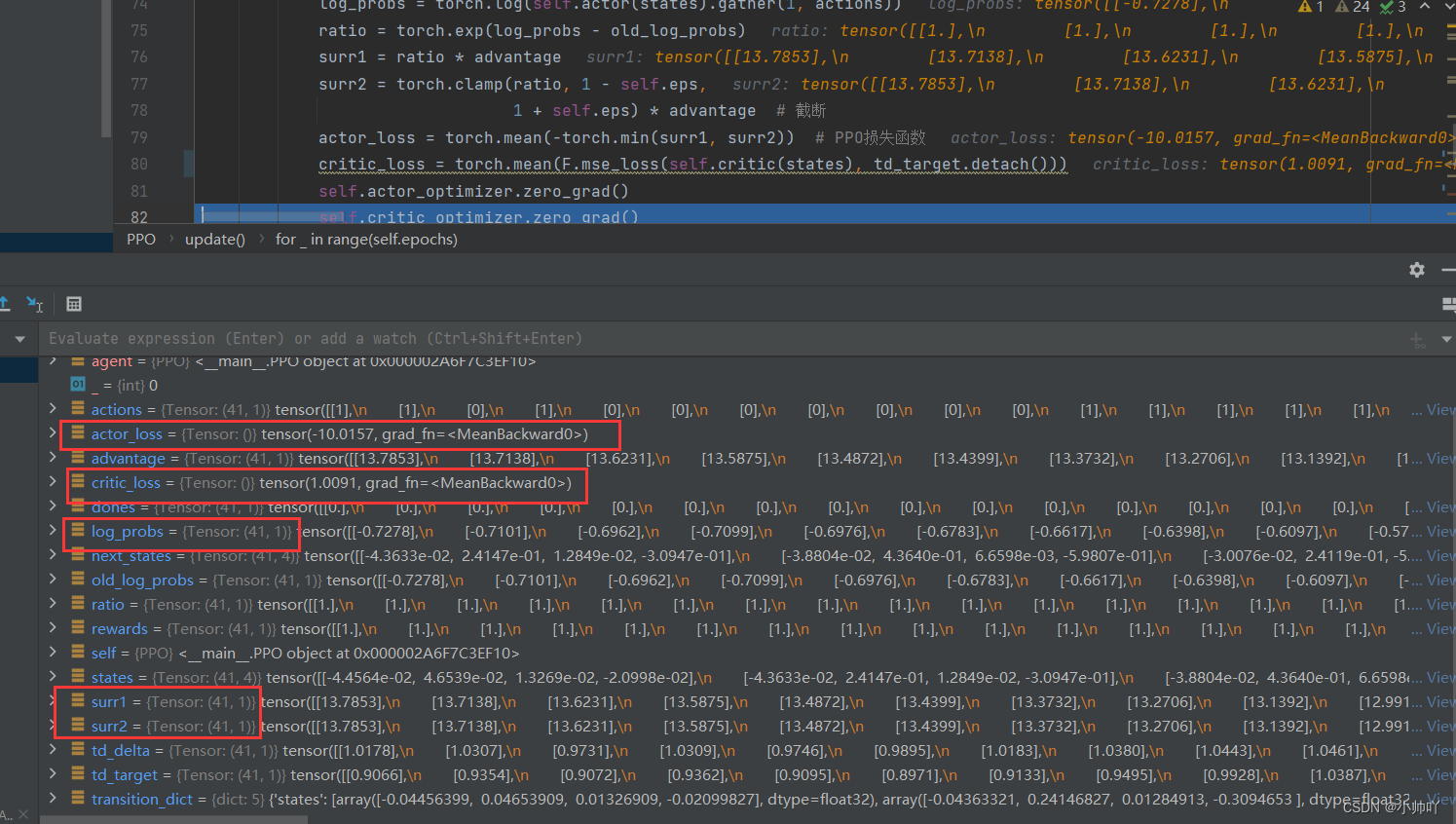
最后对actor和critic进行梯度下降进行参数更新。
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
ctor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()
至此第一次循环执行完毕,接下来还需要再进行九次这种循环,把当前episode的41个step的数据再进行九次actor和critic参数的更新。
然后update相当于执行完毕了。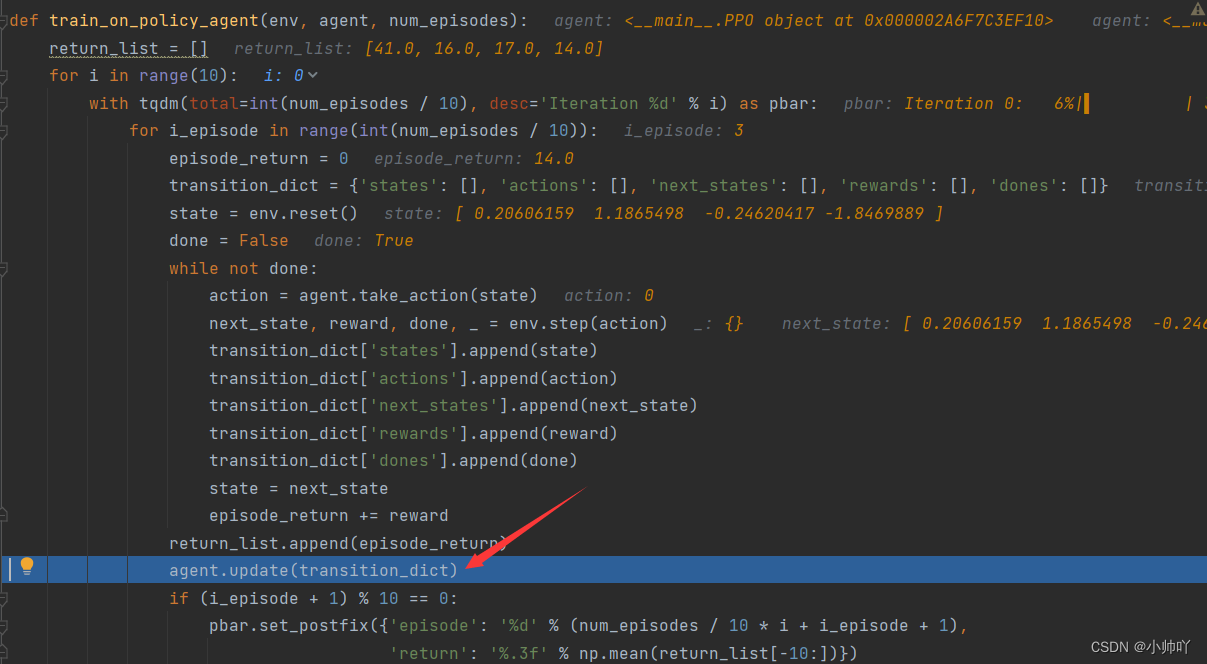
接下来一个episode的训练过程相当于结束了,我们一共有500个episode需要训练,再循环499次就完成了整个训练的流程。
还有一部分比较重要的就是通过GAE计算优势函数Advantage的代码。
def compute_advantage(gamma, lmbda, td_delta):td_delta = td_delta.detach().numpy()advantage_list = []advantage = 0.0for delta in td_delta[::-1]:advantage = gamma * lmbda * advantage + deltaadvantage_list.append(advantage)advantage_list.reverse()return torch.tensor(advantage_list, dtype=torch.float)这部分就留给大家结合第一部分理论部分最后一张图来进行理解了。
参考资料
- 磨菇书easy-rl https://datawhalechina.github.io/easy-rl/#/chapter5/chapter5
- 《动手学强化学习》 https://hrl.boyuai.com/chapter/2/ppo%E7%AE%97%E6%B3%95
99%的人还看了
猜你感兴趣
版权申明
本文"PPO算法逐行代码详解":http://eshow365.cn/6-19359-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!