机器学习:随机森林
最佳答案 问答题库808位专家为你答疑解惑
集成学习
集成学习(Ensemble Learning)是一种机器学习方法,通过将多个基本学习算法的预测结果进行组合,以获得更好的预测性能。集成学习的基本思想是通过结合多个弱分类器或回归器的预测结果,来构建一个更强大的集成模型。集成学习可以用于分类问题和回归问题。在分类问题中,集成学习将多个分类器的预测结果进行投票或加权组合,最终输出集成模型的预测结果。在回归问题中,集成学习将多个回归器的预测结果进行平均或加权平均,得到最终的回归结果。
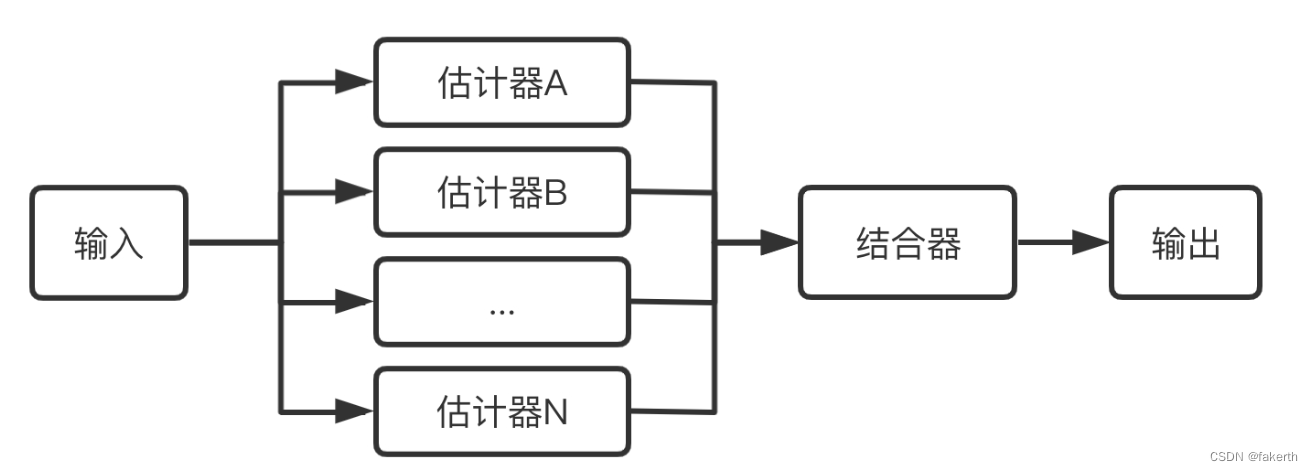
集成学习的优势在于能够减少单个模型的过拟合风险,提高模型的泛化能力。通过结合多个模型的预测结果,集成模型可以在不同数据分布、噪声和样本偏差等情况下表现更好。然而,集成学习也需要考虑模型之间的差异性,过度集成可能导致过拟合,因此在实践中需要进行适当的调参和模型选择。
Bagging
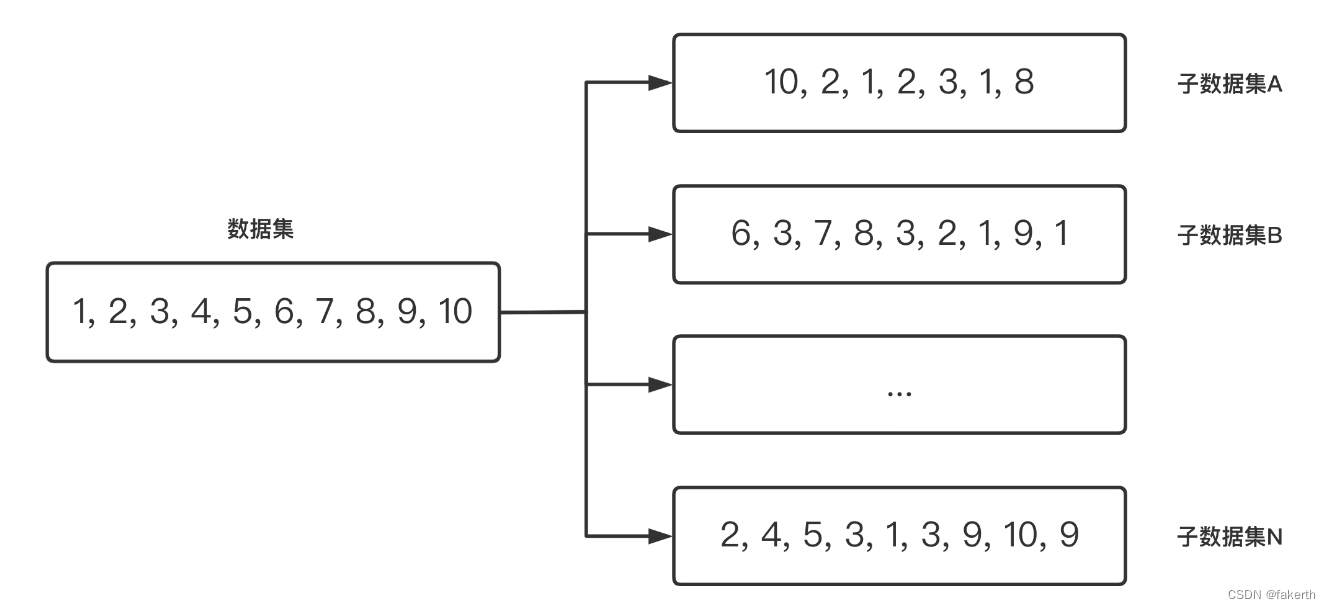
Bagging(Bootstrap Aggregating)是一种基于自助采样(bootstrap sampling)和集成学习的方法。它通过对原始训练集进行有放回采样,生成多个采样集,然后使用每个采样集来训练一个基本分类器或回归器。最后,通过对这些基本模型的预测结果进行投票或平均,得到最终的集成模型的预测结果。
Bagging的步骤如下:
1.自助采样(Bootstrap Sampling):
从原始训练集中有放回地随机采样,生成多个采样集,每个采样集的样本数量与原始训练集相同,但可能包含重复样本和缺失样本。
2.基本模型训练:
使用每个采样集来训练一个基本分类器或回归器。这些基本模型可以是相同的学习算法,也可以是不同的学习算法。
3.预测结果集成:
对于分类问题,采用多数投票的方式,将基本模型的预测结果进行投票,选择得票最多的类别作为集成模型的最终预测结果。对于回归问题,采用平均或加权平均的方式,将基本模型的预测结果进行平均,得到集成模型的最终预测结果。
Bagging的优势在于能够减少模型的方差,提高模型的稳定性和泛化能力。由于每个基本模型都是在不同的训练集上独立训练的,它们可以捕捉到数据集中的不同特征和噪声,从而减少了单个模型的过拟合风险。此外,Bagging还可以并行化处理,加速模型训练的过程。
随机森林
随机森林(Random Forest)是一种基于决策树的集成学习方法,通过构建多个决策树,并对它们的预测结果进行集成,来实现分类和回归任务。随机森林结合了Bagging和随机特征选择的技术,具有较好的泛化能力和抗过拟合能力。随机森林的优点如下:
- 随机森林对于高维数据和大规模数据集的处理能力较强。
- 随机森林能够提供特征的重要性评估,帮助我们理解数据中各个特征的相对重要性。
- 随机森林能够有效地处理缺失值和异常值,不需要数据预处理的步骤。
- 随机森林在训练过程中可以并行化处理,加速模型的训练过程。
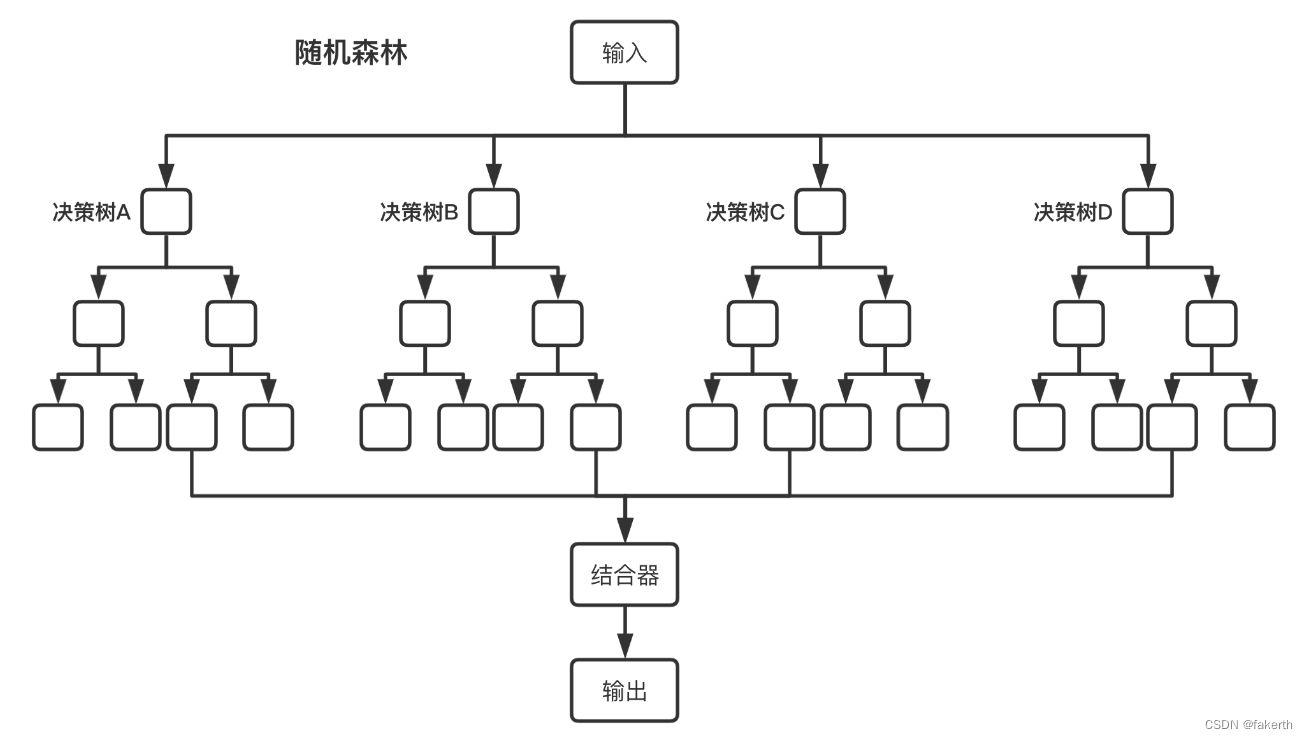
算法步骤
1.决策树的构建:
决策树是一种基本的分类与回归方法,它通过对特征空间进行划分来建立决策规则。在随机森林中,每个决策树都是独立构建的,使用训练集的一个采样集来训练。决策树的构建过程中,通过对特征的随机选择,限制了每个节点可用的特征子集,从而增加了模型的多样性。一般情况下,对于分类问题,随机选择的特征子集大小一般为总特征数的平方根;对于回归问题,一般选择总特征数的三分之一。
2.自助采样(Bootstrap Sampling):
随机森林通过自助采样生成多个采样集。自助采样是一种有放回地随机采样方法,从原始训练集中随机选择与原始训练集相同数量的样本,形成一个采样集。自助采样过程中,每次采样都是独立的,因此某些样本可能在同一个采样集中出现多次,而另一些样本可能被忽略。
3.特征选择:
在每个决策树的节点中,随机森林通过随机选择一部分特征来进行划分。这种特征选择的方式增加了决策树之间的差异性,避免了过度拟合。特征选择的过程可以采用随机选择一定数量的特征子集,也可以采用随机选择一个特定的特征子集。
4.决策树集成:
随机森林通过对多个决策树的预测结果进行集成来得出最终的预测结果。对于分类问题,采用多数投票的方式,选择得票最多的类别作为随机森林的最终预测结果。对于回归问题,采用平均或加权平均的方式,将多个决策树的预测结果进行平均,得到最终的回归结果。
随机森林实现
from sklearn import treeimport os
import pandas as pd
import numpy as np
import sklearn
import xgboost as xgbfrom utils.features import *import warningswarnings.filterwarnings("ignore")def load_datasets():pd.set_option('display.max_columns', 1000)pd.set_option('display.width', 1000)pd.set_option('display.max_colwidth', 1000)df = pd.read_pickle('****.pickle')features = darshan_featuresprint(df.head(10))df_train, df_test = sklearn.model_selection.train_test_split(df, test_size=0.2)X_train, X_test = df_train[features], df_test[features]print(X_test)y_train, y_test = df_train["value"], df_test["value"]print(y_test)return X_train, X_test, y_train, y_testdef model_train(X_train, X_test, y_train, y_test):# 决策树回归clf = tree.DecisionTreeRegressor()# 拟合数据clf = clf.fit(X_train, y_train)y_pred_test = clf.predict(X_test)print(y_test)print(y_pred_test)error = np.median(10 ** np.abs(y_test - y_pred_test))print(error)def main():X_train, X_test, y_train, y_test = load_datasets()model_train(X_train, X_test, y_train, y_test)if __name__ == "__main__":main()99%的人还看了
相似问题
- 最新AIGC创作系统ChatGPT系统源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图,图片对话理解功能
- 思维模型 等待效应
- FinGPT:金融垂类大模型架构
- 人工智能基础_机器学习044_使用逻辑回归模型计算逻辑回归概率_以及_逻辑回归代码实现与手动计算概率对比---人工智能工作笔记0084
- Pytorch完整的模型训练套路
- Doris数据模型的选择建议(十三)
- python自动化标注工具+自定义目标P图替换+深度学习大模型(代码+教程+告别手动标注)
- ChatGLM2 大模型微调过程中遇到的一些坑及解决方法(更新中)
- Python实现WOA智能鲸鱼优化算法优化随机森林分类模型(RandomForestClassifier算法)项目实战
- 扩散模型实战(十一):剖析Stable Diffusion Pipeline各个组件
猜你感兴趣
版权申明
本文"机器学习:随机森林":http://eshow365.cn/6-17722-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 手写线程池,能进行任务窃取的线程池---注释
- 下一篇: c++解压压缩包文件