已解决
selenium自动化测试-获取网页截图
来自网友在路上 168868提问 提问时间:2023-09-27 07:39:26阅读次数: 68
最佳答案 问答题库688位专家为你答疑解惑
今天学习下使用selenium自动化测试工具获取网页截图。
1,如果是简单获取当前屏幕截图只需要使用方法:
driver.get_screenshot_as_file('screenshot.png')
2,如果想获取完整网页长宽的截图需要设置参数后使用该方法:
首先打开驱动方式设置为无界面显示模式
# 打开驱动
def open_driver():try:# 连接浏览器web驱动全局变量global driver# Linux系统下浏览器驱动无界面显示,需要设置参数# “–no-sandbox”参数是让Chrome在root权限下跑# “–headless”参数是不用打开图形界面chrome_options = Options()# 设为无头模式chrome_options.add_argument('--headless')chrome_options.add_argument('--no-sandbox')chrome_options.add_argument('--disable-gpu')chrome_options.add_argument('--disable-dev-shm-usage')# 连接Chrome浏览器驱动,获取驱动driver = webdriver.Chrome(chrome_options=chrome_options)'''# 此步骤很重要,设置chrome为开发者模式,防止被各大网站识别出来使用了Seleniumoptions = Options()# 静默模式(加载浏览器的静默模式,让它在后台偷偷运行)# options.add_argument('headless')# 去掉提示:Chrome正收到自动测试软件的控制options.add_argument('disable-infobars')# 以键值对的形式加入参数,打开浏览器开发者模式# options.add_experimental_option('excludeSwitches', ['enable-automation'])# 打开浏览器开发者模式# options.add_argument("--auto-open-devtools-for-tabs")driver = webdriver.Chrome(chrome_options=options)'''# driver = webdriver.Chrome()print('连接Chrome浏览器驱动')# 浏览器窗口最大化driver.maximize_window()'''1, 隐式等待方法driver.implicitly_wait(最大等待时间, 单位: 秒)2, 隐式等待作用在规定的时间内等待页面所有元素加载;3,使用场景:在有页面跳转的时候, 可以使用隐式等待。'''driver.implicitly_wait(3)# 强制等待,随机休眠 暂停0-3秒的整数秒,时间区间:[0,3]time.sleep(random.randint(0, 3))except Exception as e:driver = Noneprint(str(e))
然后设置网页长宽最大化,保证截图是完整的,不会出现滚动条
S = lambda X: driver.execute_script('return document.body.parentNode.scroll' + X)
driver.set_window_size(S('Width'), S('Height'))
driver.get_screenshot_as_file('screenshot.png')
3,编写代码
依旧采用拆分步骤细化功能模块封装方法编写代码,便于后续扩展功能模块,代码中缺少的封装方法代码,详情参考之前的《selenium自动化测试》文章。
def spider_screenshot_image(req_dict):'''@方法名称: 爬取网页内容截图文件@中文注释: 爬取网页内容截图文件@入参:@param req_dict dict 请求容器@出参:@返回状态:@return 0 失败或异常@return 1 成功@返回错误码@返回错误信息@param rsp_dict dict 响应容器@作 者: PandaCode辉@weixin公众号: PandaCode辉@创建时间: 2023-09-26@使用范例: spider_screenshot_image(req_dict)'''try:if (not type(req_dict) is dict):return [0, "111111", "请求容器参数类型错误,不为字典", [None]]# 截图目录screenshot_dir = os.path.join(os.path.dirname(__file__), 'screenshot')if not os.path.exists(screenshot_dir):os.makedirs(screenshot_dir)print('打开浏览器驱动')open_driver()# 打开网址网页print('打开网址网页')driver.get(req_dict['url'])# 等待6秒启动完成driver.implicitly_wait(6)print('随机休眠')# 随机休眠 暂停0-2秒的整数秒time.sleep(random.randint(0, 2))# 保存当前网页屏幕快照PNG图像文件,截图不保证完整网页内容都截取到page_file_1 = os.path.join(screenshot_dir, 'page1.png')isprint = driver.get_screenshot_as_file(page_file_1)print(isprint)# 网页长宽最大化,保证截图是完整的,不会出现滚动条S = lambda X: driver.execute_script('return document.body.parentNode.scroll' + X)driver.set_window_size(S('Width'), S('Height'))# 保存当前网页屏幕快照PNG图像文件page_file_2 = os.path.join(screenshot_dir, 'page2.png')isprint = driver.get_screenshot_as_file(page_file_2)print(isprint)# 章节内容截图image_file = os.path.join(screenshot_dir, 'content.png')# 元素定位elem = driver.find_element(By.ID, req_dict['elem_id'])print(elem)# 元素截图isprint = elem.screenshot(image_file)print(isprint)print('关闭浏览器驱动')close_driver()print("爬取网页内容截图文件成功")# 返回容器return [1, '000000', '爬取网页内容截图文件成功', [None]]except Exception as e:print('关闭浏览器驱动')close_driver()print("爬取网页内容截图文件异常," + str(e))return [0, '999999', "爬取网页内容截图文件异常," + str(e), [None]]
4,运行效果
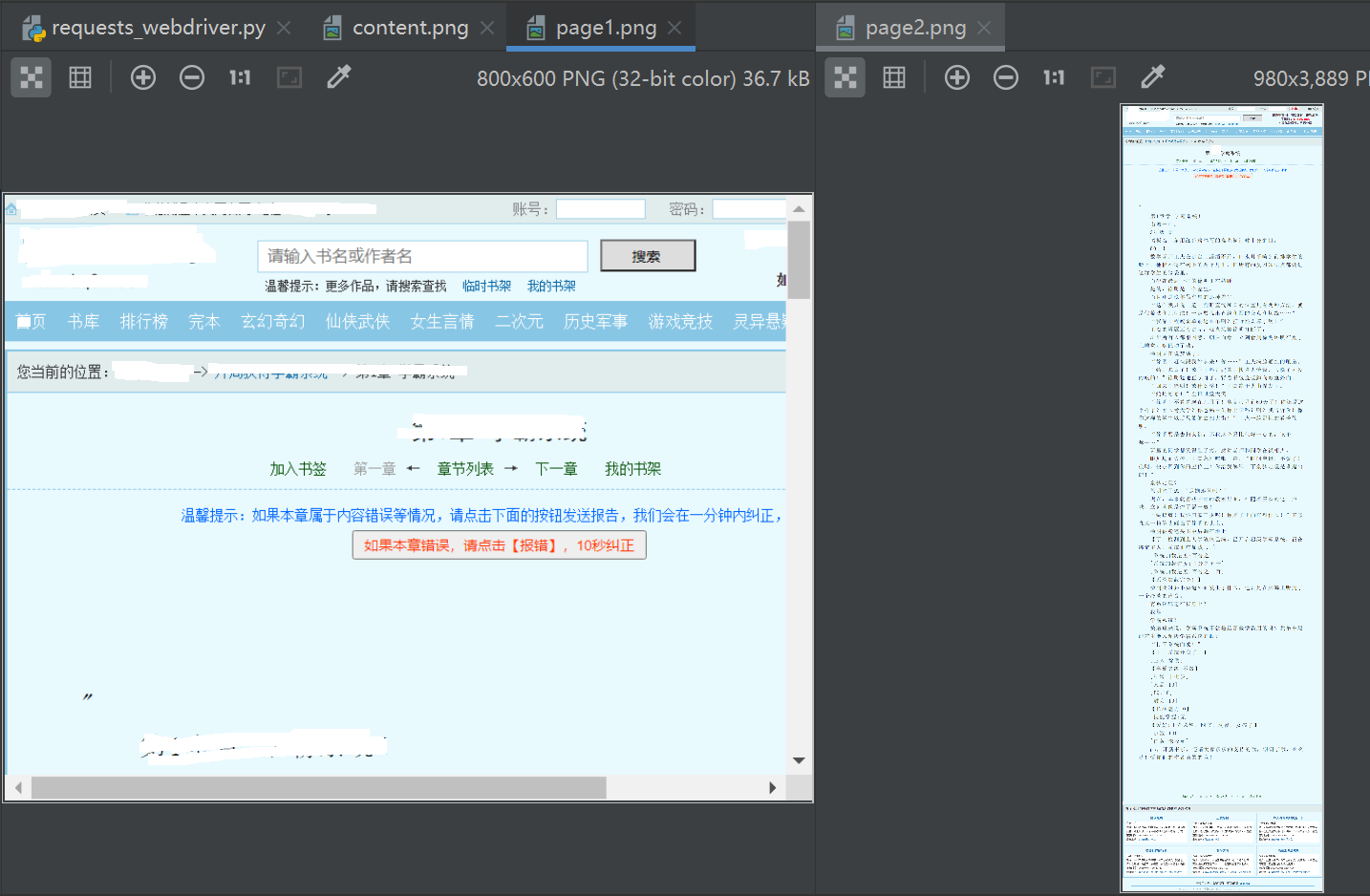
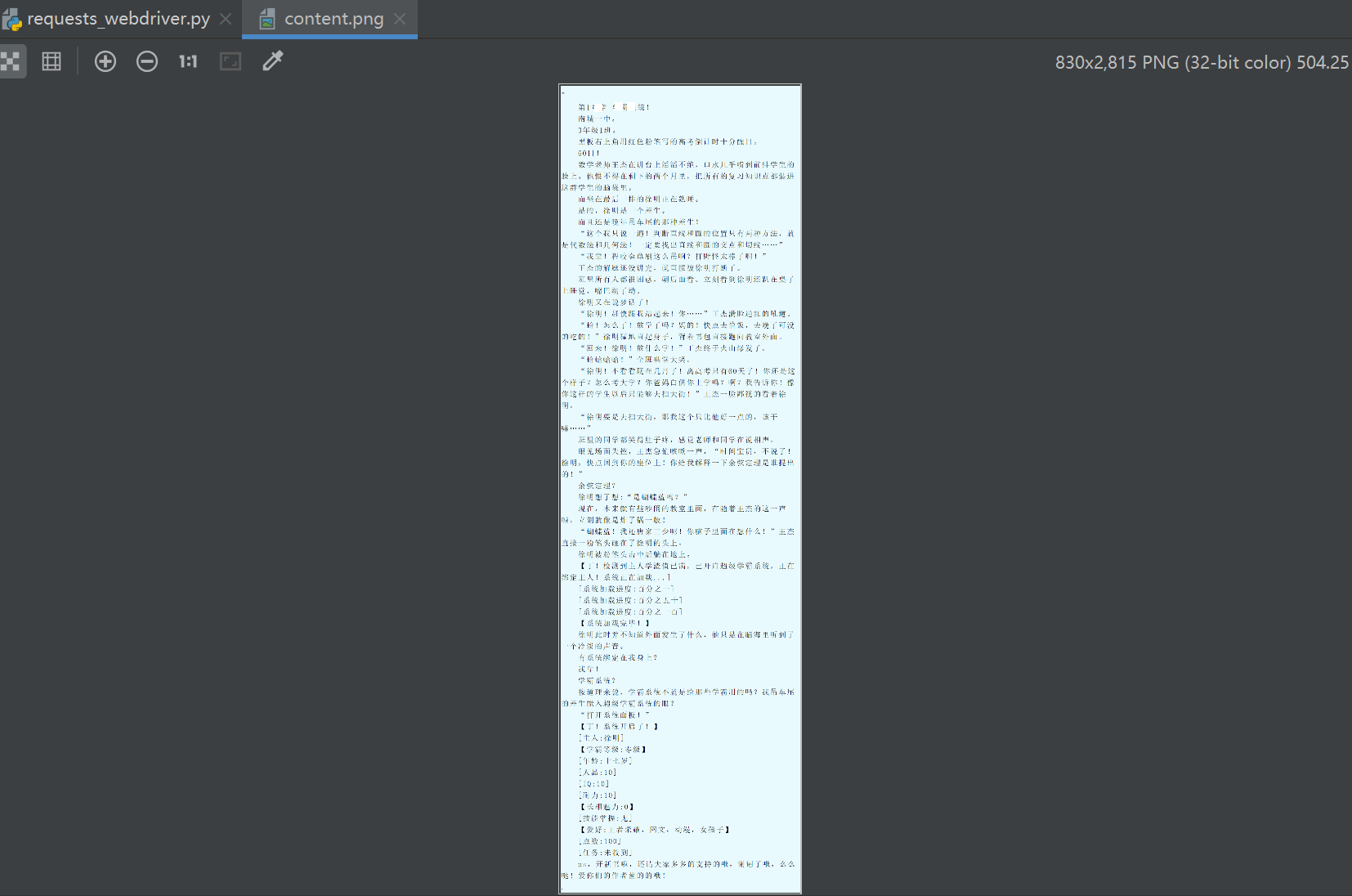
最后说明:上述文章仅供学习参考,请勿用于商业用途,感谢阅读。
查看全文
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"selenium自动化测试-获取网页截图":http://eshow365.cn/6-14496-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: ES6 的 export / import 常用方式总结
- 下一篇: MySQL索引看这篇就够了