已解决
Spark SQL【电商购买数据分析】
来自网友在路上 175875提问 提问时间:2023-09-23 05:46:25阅读次数: 75
最佳答案 问答题库758位专家为你答疑解惑
Spark 数据分析 (Scala)
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
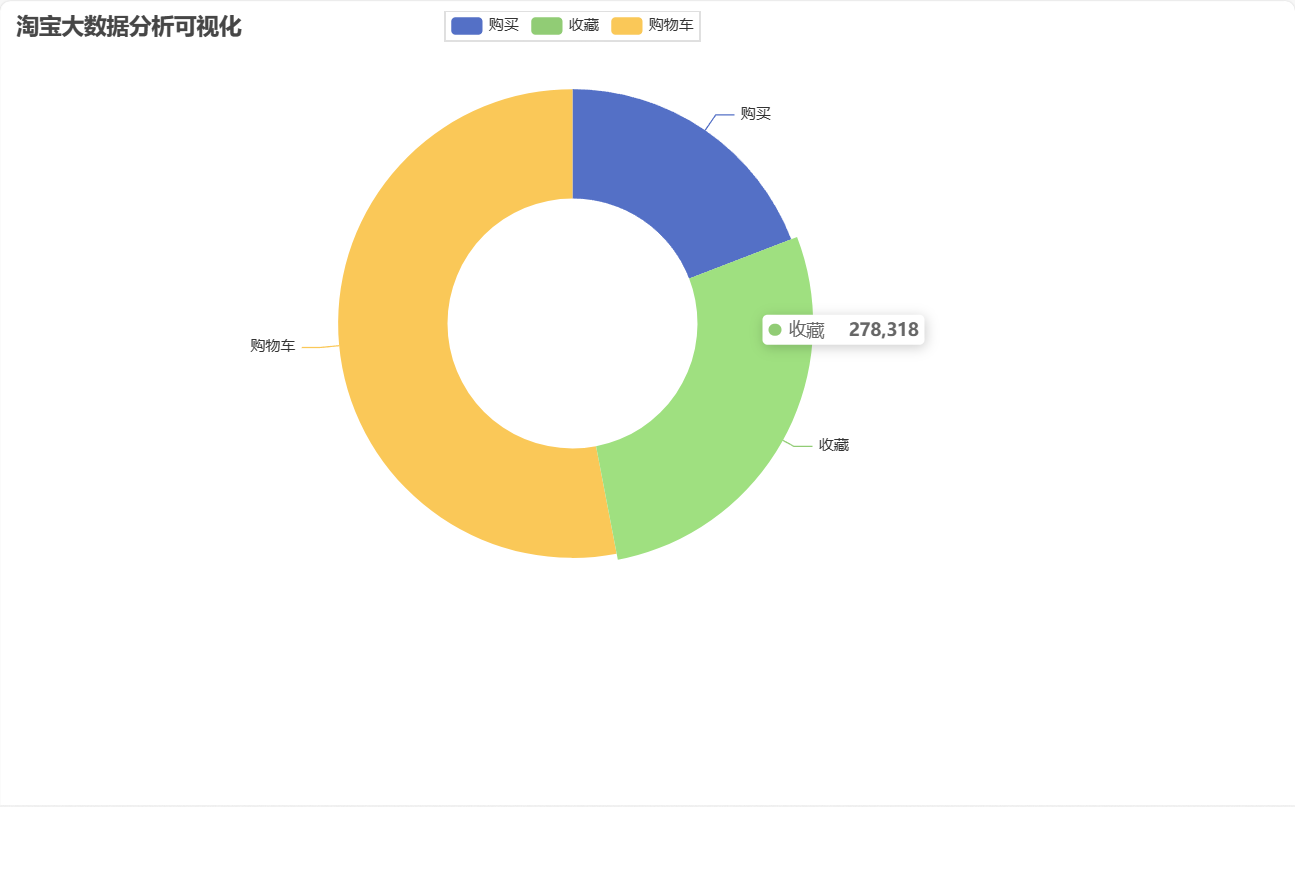
import org.apache.spark.{SparkConf, SparkContext}import java.io.{File, PrintWriter}object Taobao {case class Info(userId: Long,itemId: Long,action: String,time: String)def main(args: Array[String]): Unit = {// 使用2个CPU核心val conf = new SparkConf().setMaster("local[2]").setAppName("tao bao product")val spark = SparkSession.builder().config(conf).getOrCreate()import spark.implicits._val sc = spark.sparkContext// 从本地文件系统加载文件生成RDD对象val rdd: RDD[Array[String]] = sc.textFile("data/practice2/Processed_UserBehavior.csv").map(_.split(","))// RDD 转为 DataFrame对象val df: DataFrame = rdd.map(attr => Info(attr(0).trim.toInt, attr(1).trim.toInt, attr(2), attr(3))).toDF()// Spark 数据分析//1.用户行为信息统计val behavior_count: DataFrame = df.groupBy("action").count()val result1 = behavior_count.toJSON.collectAsList().toString
// val writer1 = new PrintWriter(new File("data/practice2/result1.json"))
// writer1.write(result1)
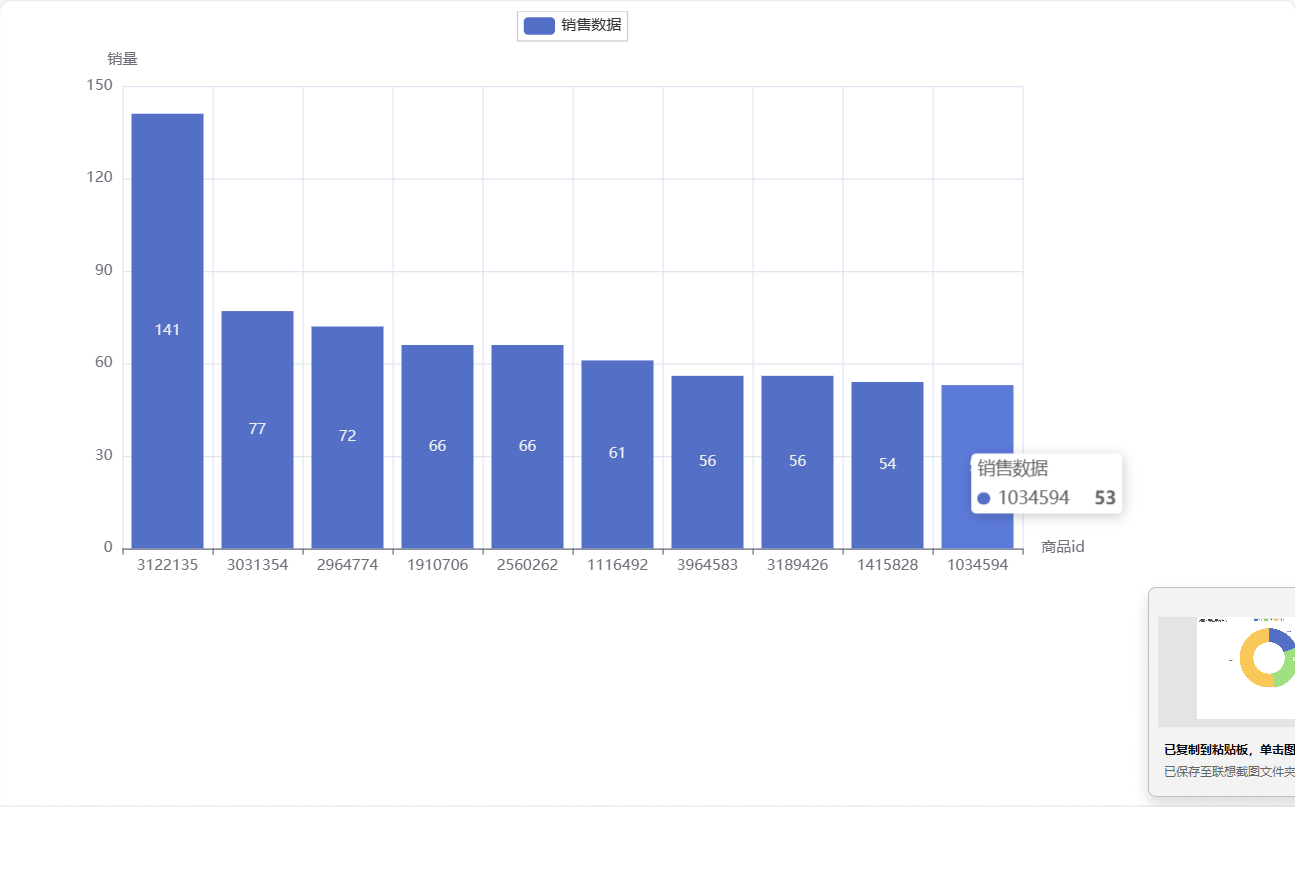
// writer1.close()//2.销量前十的商品信息统计val top_10_item:Array[(String,Int)] = df.filter(df("action") === "buy").select(df("itemId")).rdd.map(v => (v(0).toString,1)).reduceByKey(_+_).sortBy(_._2,false).take(10)val result2 = sc.parallelize(top_10_item).toDF().toJSON.collectAsList().toString
// val writer2 = new PrintWriter(new File("data/practice2/result2.json"))
// writer2.write(result2)
// writer2.close()//3.购物数量前十的用户信息统计val top_10_user: Array[(String,Int)] = df.filter(df("action") === "buy").select(df("userId")).rdd.map(v => (v(0).toString, 1)).reduceByKey(_ + _).sortBy(_._2, false).take(10)val result3 = sc.parallelize(top_10_user).toDF().toJSON.collectAsList().toString
// val writer3 = new PrintWriter(new File("data/practice2/result3.json"))
// writer3.write(result3)
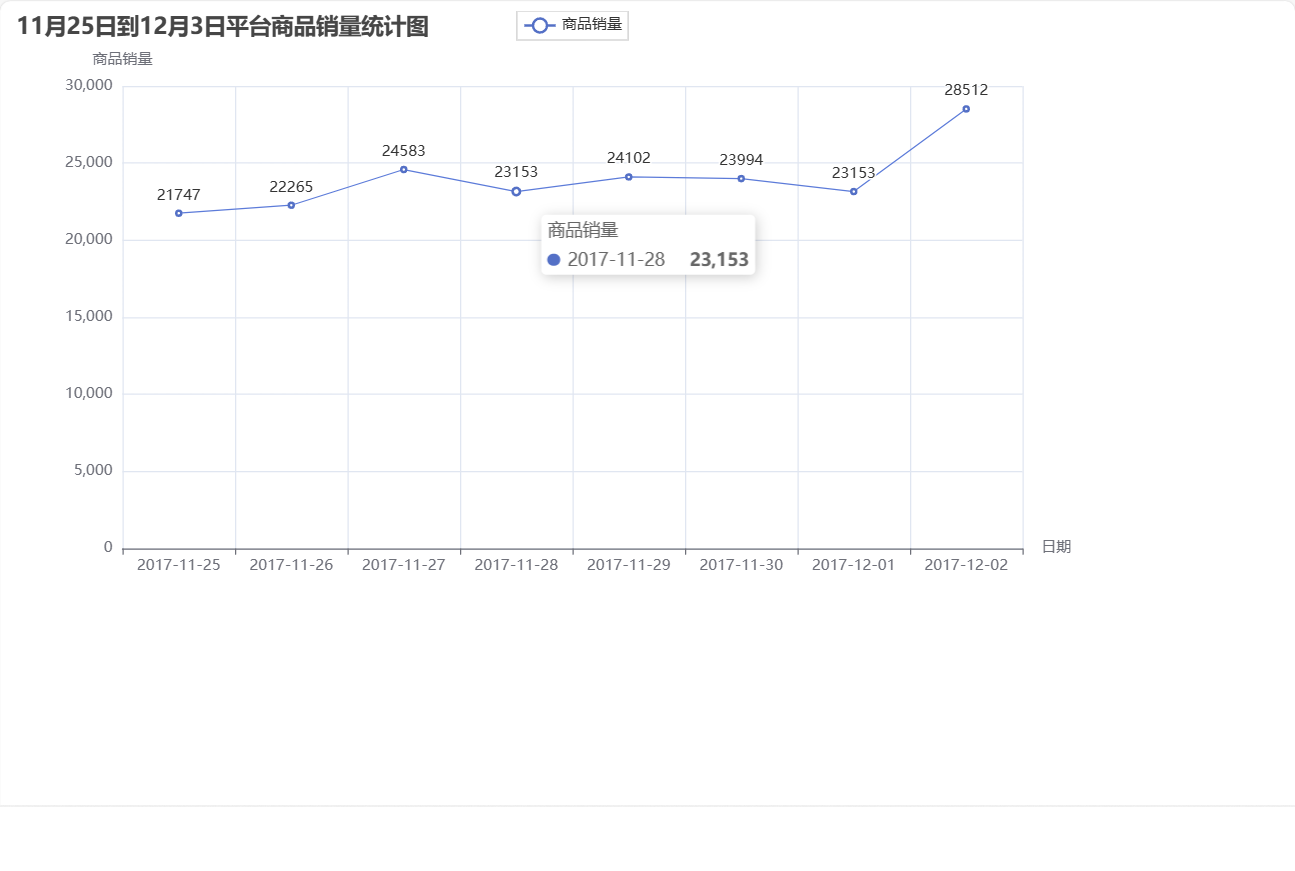
// writer3.close()// 4.时间段内平台商品销量统计val buy_order_by_date: Array[(String,Int)] = df.filter(df("action") === "buy").select(df("time")).rdd.map(v => (v.toString().replace("[","").replace("]","").split(" ")(0),1)).reduceByKey(_+_).sortBy(_._1).collect()//转为dataframe
// buy_order_by_date.foreach(println)/*(2017-11-25,21747)(2017-11-26,22265)(2017-11-27,24583)(2017-11-28,23153)(2017-11-29,24102)(2017-11-30,23994)(2017-12-01,23153)(2017-12-02,28512)*/val result4 = sc.parallelize(buy_order_by_date).toDF().toJSON.collectAsList().toStringval writer4 = new PrintWriter(new File("data/practice2/result4.json"))writer4.write(result4)writer4.close()sc.stop()spark.stop()}
}数据可视化(pyecharts)

查看全文
99%的人还看了
相似问题
- 多平台商品采集——API接口:支持淘宝、天猫、1688、拼多多等多个电商平台的爆款、销量、整店商品采集和淘客功能
- 小白学爬虫:通过商品ID或商品链接封装接口获取淘宝商品销量数据接口|淘宝商品销量接口|淘宝月销量接口|淘宝总销量接口
- 全球先端品牌德妃DERMAFIRM隔离品销量突破780万再创新高
- 电商API:淘宝京东拼多多1688多电商平台的商品销量库存信息获取
- 电商平台API接口接入电商数据平台调用采集阿里巴巴alibaba按关键字搜索商品标题、优惠价、销量、物流费用参数调用案例
- 京东平台数据分析(京东销量):2023年9月京东吸尘器行业品牌销售排行榜
- 京东销量(销额)数据分析:2023年9月京东奶粉行业品牌销售排行榜
- 2023年中国调速器产量、销量及市场规模分析[图]
- 电商数据平台官方API接口苏宁易购获得suning商品详情信息产品图片、销量、价格、商品规格信息调用示例
- 淘宝商品详情API接口(标题|主图|SKU|价格|销量|库存..)
猜你感兴趣
版权申明
本文"Spark SQL【电商购买数据分析】":http://eshow365.cn/6-11929-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!