【PostgreSQL内核学习(十一)—— (CreatePortal)】
最佳答案 问答题库588位专家为你答疑解惑
CreatePortal
- 概述
- CreatePortal 函数
- GetPortalByName 函数
- PortalHashTableLookup 函数
- MemoryContextAllocZero 函数
- AllocSetContextCreate 函数
- ResourceOwnerCreate
- PortalHashTableInsert
- 总结
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书,OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及OpenGauss社区学习文档
概述
在PostgreSQL数据库中,Portal是一种数据库内部的概念,用于支持客户端和服务器之间的高级查询和结果集处理。Portal允许客户端在多个步骤中执行查询,并且可以在多次执行之间保持状态。以下是Portal的主要功能和作用:
- 多步查询处理:Portal允许客户端执行查询的多个步骤,每个步骤都可以在一个事务中或多个事务中进行。这对于需要分阶段获取结果的查询非常有用,例如大型查询或分批次处理数据。
- 结果集缓存:Portal可以缓存查询的结果集。这意味着客户端可以多次检索相同的结果,而无需重新执行查询。这对于需要反复访问相同数据的应用程序性能提升非常重要。
- 游标支持:Portal通常与游标一起使用,使客户端能够在结果集上进行遍历、滚动和检索操作。客户端可以打开和管理多个Portal,每个Portal都可以与不同的查询或结果集相关联。
- 事务隔离:Portal可以在单个事务内或多个事务之间执行查询。这意味着客户端可以在不同的事务中使用相同的Portal来处理数据,以实现更高级的事务隔离级别。
- 内存管理:Portal还可以管理内存,确保在多步查询处理中不会出现内存泄漏或不必要的内存开销。它可以自动释放不再需要的结果集内存。
其中,关系Portal的概述在【PostgreSQL内核学习(八)—— 查询执行(查询执行策略)】中进行了简要概述。在本文中,我们则来详细的开始一步步的拆解学习有关Portal的执行过程吧。
CreatePortal 函数
在PostgreSQL中,CreatePortal 函数用于创建一个新的 Portal(查询门户)。以下是 CreatePortal 函数的作用和意义:
- 创建 Portal 对象:函数的主要目的是创建一个 Portal 对象。Portal 是一个数据库内部的数据结构,用于处理和管理客户端执行的查询。每个 Portal 对象都与一个查询相关联,它允许客户端执行多个步骤的查询,并管理与查询执行相关的状态。
- 检查是否存在同名的 Portal:在创建新的 Portal 之前,函数首先尝试查找是否已经存在同名的 Portal。如果已经存在同名的 Portal,根据 allowDup 和 dupSilent 参数的设置,可以执行不同的操作。如果不允许重复(allowDup 为 false),函数将抛出一个错误,表明同名 Portal 已经存在。如果 dupSilent 为 false,则会发出警告信息。如果允许重复(allowDup 为 true),则会关闭现有同名的 Portal。
- Portal 属性初始化:函数接着会对新创建的 Portal 对象进行初始化,设置各种属性和状态。这些属性包括 Portal 的状态、内存分配、资源所有者、创建时间、使用计数等。
- 设置 Portal 名称:函数最后会将 Portal 对象插入到 Portal 表中,从而为 Portal 分配一个唯一的名称。这使得客户端可以通过名称引用该 Portal。
- 可选的 PGXC 支持:在 PostgreSQL 中,存在对分布式数据库的支持。函数中存在一段代码,用于获取分布式节点的标识符(PGXCNodeIdentifier)。这部分代码在特定的条件下执行。
CreatePortal 函数源码如下:(路径:src/common/backend/utils/mmgr/portalmem.cpp)
/** CreatePortal* 创建一个新的门户(Portal)并返回。** allowDup: 如果为true,则自动删除同名的任何已存在门户(如果为false,则引发错误)。** dupSilent: 如果为true,则不会发出警告。*/
Portal CreatePortal(const char* name, bool allowDup, bool dupSilent, bool is_from_spi)
{Portal portal; // 声明一个门户(Portal)对象AssertArg(PointerIsValid(name)); // 断言:确保名称参数有效portal = GetPortalByName(name); // 通过名称获取门户if (PortalIsValid(portal)) {// 如果同名门户已存在,根据allowDup和dupSilent参数执行不同操作if (allowDup == false)ereport(ERROR, (errcode(ERRCODE_DUPLICATE_CURSOR), errmsg("cursor \"%s\" already exists", name)));if (dupSilent == false)ereport(WARNING, (errcode(ERRCODE_DUPLICATE_CURSOR), errmsg("closing existing cursor \"%s\"", name)));PortalDrop(portal, false); // 关闭或删除同名门户}/* 创建新的门户结构 */portal = (Portal)MemoryContextAllocZero(u_sess->top_portal_cxt, sizeof *portal);/* 初始化门户的堆上下文;通常不会存储太多数据 */portal->heap = AllocSetContextCreate(u_sess->top_portal_cxt,"PortalHeapMemory",ALLOCSET_SMALL_MINSIZE,ALLOCSET_SMALL_INITSIZE,ALLOCSET_SMALL_MAXSIZE);/* 为门户创建资源所有者 */portal->resowner = ResourceOwnerCreate(t_thrd.utils_cxt.CurTransactionResourceOwner, "Portal",MEMORY_CONTEXT_EXECUTOR);/* 初始化门户字段,这些字段初始值不为零 */portal->status = PORTAL_NEW; // 设置门户状态为新建portal->cleanup = PortalCleanup; // 设置门户清理函数portal->createSubid = GetCurrentSubTransactionId(); // 获取当前子事务IDportal->activeSubid = portal->createSubid; // 设置门户的活动子事务IDportal->strategy = PORTAL_MULTI_QUERY; // 设置门户的查询策略portal->cursorOptions = CURSOR_OPT_NO_SCROLL; // 设置门户的游标选项portal->atStart = true; // 设置门户在查询开始时为trueportal->atEnd = true; /* 在设置查询之前禁止获取数据 */portal->visible = true; // 设置门户可见性为trueportal->creation_time = GetCurrentStatementStartTimestamp(); // 获取当前语句的开始时间戳portal->funcOid = InvalidOid; // 设置门户关联的函数OID为无效OIDportal->is_from_spi = is_from_spi; // 标志门户是否来自SPIint rc = memset_s(portal->cursorAttribute, CURSOR_ATTRIBUTE_NUMBER * sizeof(void*), 0,CURSOR_ATTRIBUTE_NUMBER * sizeof(void*)); // 初始化门户的游标属性securec_check(rc, "\0", "\0"); // 安全检查portal->funcUseCount = 0; // 设置门户的函数使用计数为0/* 将门户放入表中(设置门户的名称) */PortalHashTableInsert(portal, name); // 将门户添加到门户哈希表中,并设置门户的名称#ifdef PGXCif (u_sess->pgxc_cxt.PGXCNodeIdentifier == 0 && !IsAbortedTransactionBlockState()) {/* 获取 pgxc_node id */Oid node_oid = get_pgxc_nodeoid(g_instance.attr.attr_common.PGXCNodeName); // 获取PGXC节点OIDu_sess->pgxc_cxt.PGXCNodeIdentifier = get_pgxc_node_id(node_oid); // 设置PGXC节点标识符}
#endifreturn portal; // 返回创建的门户对象
}
这里我们结合案例进行调试学习,案例采用OpenGauss源码学习 —— 执行算子(Result 算子)中所采用的案例,如下所示:
-- 创建 employees 表
CREATE TABLE employees (id SERIAL PRIMARY KEY,name VARCHAR(50),age INT,salary DECIMAL(10, 2)
);-- 插入一些数据
INSERT INTO employees (name, age, salary) VALUES('Alice', 28, 60000.00),('Bob', 35, 75000.00),('Charlie', 22, 45000.00);-- 执行查询
SELECT * FROM employees;-- 查询结果id | name | age | salary
----+---------+-----+----------1 | Alice | 28 | 60000.002 | Bob | 35 | 75000.003 | Charlie | 22 | 45000.00
(3 rows)
函数 CreatePortal 接受四个参数,以下是这些参数的说明:
- const char* name:这是一个字符串参数,表示要创建的 Portal 的名称。它是一个用于唯一标识 Portal 的用户定义的名称。通常,不同的 Portal 会有不同的名称,以便在代码中引用它们。
- bool allowDup:这是一个布尔参数,控制是否允许创建具有相同名称的多个 Portal。如果 allowDup 设置为 true,则允许创建同名 Portal,否则会引发错误。这是一个用于处理同名 Portal 的选项。
- bool dupSilent:这也是一个布尔参数,用于指示是否在创建同名 Portal 时发出警告。如果 dupSilent 设置为 true,则即使有同名 Portal 存在,也不会发出警告消息。如果 dupSilent 设置为 false,则会在同名 Portal 存在时发出警告消息,但不会引发错误。
- bool is_from_spi:这是一个布尔参数,用于指示 Portal 是否由 SPI (Server Programming Interface) 函数创建。SPI 是 PostgreSQL 中的一种动态 SQL 接口,允许在数据库中执行动态 SQL 语句。如果 is_from_spi 为 true,表示该 Portal 是由 SPI 函数创建的;如果为 false,表示不是由 SPI 函数创建的。
调试信息如下:
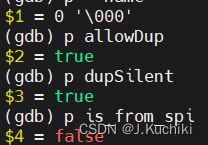
GetPortalByName 函数
函数 GetPortalByName 根据给定的门户名称来查找门户对象,并返回找到的门户对象或者如果没有找到则返回 NULL。函数源码如下:(路径:src/common/backend/utils/mmgr/portalmem.cpp)
/** GetPortalByName* 根据门户名称获取门户对象,如果没有找到则返回NULL。** name: 要查找的门户的名称。*/
Portal GetPortalByName(const char* name)
{Portal portal; // 声明一个门户对象指针// 如果传入的门户名称有效if (PointerIsValid(name))PortalHashTableLookup(name, portal); // 调用 PortalHashTableLookup 函数查找门户// 如果传入的门户名称无效,则将 portal 设置为 NULLelseportal = NULL;return portal; // 返回找到的门户对象或 NULL
}
调试信息如下
PortalHashTableLookup 函数
这段代码定义了一个宏 PortalHashTableLookup,它用于在门户哈希表中查找门户对象并将结果存储在指定的变量中。宏定义源码如下:(路径:src/common/backend/utils/mmgr/portalmem.cpp)
#define PortalHashTableLookup(NAME, PORTAL) \do { \PortalHashEnt* hentry = NULL; \\// 在门户哈希表中查找指定名称的门户hentry = (PortalHashEnt*)hash_search(u_sess->exec_cxt.PortalHashTable, (NAME), HASH_FIND, NULL);\// 如果找到门户条目if (hentry != NULL) { // 将门户对象存储在传入的 PORTAL 变量中PORTAL = hentry->portal; } // 如果未找到门户条目else { // 将 PORTAL 变量设置为 NULL,表示未找到对应的门户PORTAL = NULL; } } while (0)
MemoryContextAllocZero 函数
函数 MemoryContextAllocZero 定义如下:(路径:src/include/utils/palloc.h)
#define MemoryContextAllocZero(context, size) MemoryContextAllocZeroDebug(context, size, __FILE__, __LINE__)
这行代码定义了一个宏 MemoryContextAllocZero,它将实际的内存分配操作委托给了 MemoryContextAllocZeroDebug 函数,同时自动传递了当前源文件的文件名 FILE 和行号 LINE 作为参数。这样做的目的是在生产环境和调试环境之间轻松切换,并提供更多的调试信息,以便在需要时更容易追踪内存分配问题。
函数 MemoryContextAllocZeroDebug,它用于在内存上下文中分配一块内存,并将分配的内存清零。以下是对这个函数的逐行注释和解释:(路径:src/common/backend/utils/mmgr/mcxt.cpp)
/** MemoryContextAllocZeroDebug* 类似于 MemoryContextAlloc,但清零分配的内存** 我们本可以调用 MemoryContextAlloc 然后清零内存,但这是一个非常常见的组合操作,所以我们提供了合并的操作。*/
void* MemoryContextAllocZeroDebug(MemoryContext context, Size size, const char* file, int line)
{void* ret = NULL; // 用于存储分配的内存的指针AssertArg(MemoryContextIsValid(context)); // 断言:确保内存上下文有效PreventActionOnSealedContext(context); // 防止在已封闭的上下文上执行操作if (!AllocSizeIsValid(size)) {// 如果分配大小无效,引发错误ereport(ERROR,(errcode(ERRCODE_INVALID_PARAMETER_VALUE),errmsg("invalid memory alloc request size %lu", (unsigned long)size)));}context->isReset = false; // 将上下文的复位标志设置为 false,表示未复位// 调用内存上下文的分配方法以分配内存,同时提供文件名和行号信息ret = (*context->methods->alloc)(context, 0, size, file, line);if (ret == NULL)// 如果分配失败,引发内存不足错误ereport(ERROR,(errcode(ERRCODE_OUT_OF_LOGICAL_MEMORY),errmsg("memory is temporarily unavailable"),errdetail("Failed on request of size %lu bytes under queryid %lu in %s:%d.",(unsigned long)size,u_sess->debug_query_id,file,line)));#ifdef MEMORY_CONTEXT_CHECKING/* 检查内存上下文是否失控 */MemoryContextCheckMaxSize(context, size, file, line);
#endif/* 检查会话使用的内存是否超出限制 */MemoryContextCheckSessionMemory(context, size, file, line);// 使用 MemSetAligned 将分配的内存清零MemSetAligned(ret, 0, size);// 插入内存分配信息,用于跟踪内存使用情况InsertMemoryAllocInfo(ret, context, file, line, size);return ret; // 返回分配的内存指针
}
这个函数的主要目的是在给定的内存上下文中分配一块内存,并将其清零。它还包括了一些内存分配失败的错误检查和内存使用情况的跟踪功能,以便在内存分配问题时进行诊断和报告。这是 PostgreSQL 内存管理系统的一部分,用于安全和可维护的内存分配。执行 MemoryContextAllocZero 函数前后的调试信息如下:

AllocSetContextCreate 函数
AllocSetContextCreate 函数的主要意义是创建一个新的内存上下文(MemoryContext)以进行内存管理。在 PostgreSQL 中,内存上下文是一种内存管理机制,用于将内存分配和释放进行组织和隔离,以确保内存的有效使用和资源的合理管理。
下面是参数和函数行为的解释:
- MemoryContext parent:父上下文,新上下文将成为其子上下文。
- const char* name:上下文的名称,用于标识和调试。
- Size minContextSize:上下文的最小大小。
- Size initBlockSize:初始化内存块的大小。
- Size maxBlockSize:内存块的最大大小。
- MemoryContextType contextType:上下文类型,指定上下文是标准上下文、共享上下文等。
- Size maxSize:用于确定内存分配是否超出阈值的参数。
- bool isSession:表示是否是会话级别的上下文。
以下是对该函数的逐行注释和解释:(路径:src/common/backend/utils/mmgr/aset.cpp)
/** Public routines* 公共函数*/
//
// AllocSetContextCreate
// 创建一个新的AllocSet上下文。
// 参数:
// @maxSize:用于确定内存分配(例如palloc函数)是否超出阈值。
// 这个参数是阈值。
//
MemoryContext AllocSetContextCreate(_in_ MemoryContext parent, _in_ const char* name, _in_ Size minContextSize,_in_ Size initBlockSize, _in_ Size maxBlockSize, _in_ MemoryContextType contextType, _in_ Size maxSize,_in_ bool isSession)
{/* 如果父上下文不是共享的而当前上下文是共享的,禁止以下情况。 */if (parent != NULL && !parent->is_shared && contextType == SHARED_CONTEXT) {ereport(ERROR,(errcode(ERRCODE_OPERATE_FAILED),errmsg("在标准上下文\"%s\"中创建共享内存上下文\"%s\"失败。",name, parent->name)));}switch (contextType) {
#ifndef ENABLE_MEMORY_CHECKcase STANDARD_CONTEXT:// 使用 GenericMemoryAllocator 创建标准上下文return GenericMemoryAllocator::AllocSetContextCreate(parent, name, minContextSize, initBlockSize, maxBlockSize, maxSize, false, isSession);case SHARED_CONTEXT:// 使用 GenericMemoryAllocator 创建共享上下文return GenericMemoryAllocator::AllocSetContextCreate(parent, name, minContextSize, initBlockSize, maxBlockSize, maxSize, true, false);
#elsecase STANDARD_CONTEXT:// 使用 AsanMemoryAllocator 创建标准上下文return AsanMemoryAllocator::AllocSetContextCreate(parent, name, minContextSize, initBlockSize, maxBlockSize, maxSize, false, isSession);case SHARED_CONTEXT:// 使用 AsanMemoryAllocator 创建共享上下文return AsanMemoryAllocator::AllocSetContextCreate(parent, name, minContextSize, initBlockSize, maxBlockSize, maxSize, true, false);
#endifcase STACK_CONTEXT:// 使用 StackMemoryAllocator 创建堆栈上下文return StackMemoryAllocator::AllocSetContextCreate(parent, name, minContextSize, initBlockSize, maxBlockSize, maxSize, false, isSession);case MEMALIGN_CONTEXT:// 使用 AlignMemoryAllocator 创建对齐上下文return AlignMemoryAllocator::AllocSetContextCreate(parent, name, minContextSize, initBlockSize, maxBlockSize, maxSize, false, isSession);case MEMALIGN_SHRCTX:// 使用 AlignMemoryAllocator 创建共享对齐上下文return AlignMemoryAllocator::AllocSetContextCreate(parent, name, minContextSize, initBlockSize, maxBlockSize, maxSize, true, false);default:// 对于未识别的上下文类型,引发错误ereport(ERROR, (errcode(ERRCODE_UNRECOGNIZED_NODE_TYPE), errmsg("未识别的上下文类型")));break;}return NULL;
}
执行 AllocSetContextCreate 函数后的调试信息如下:
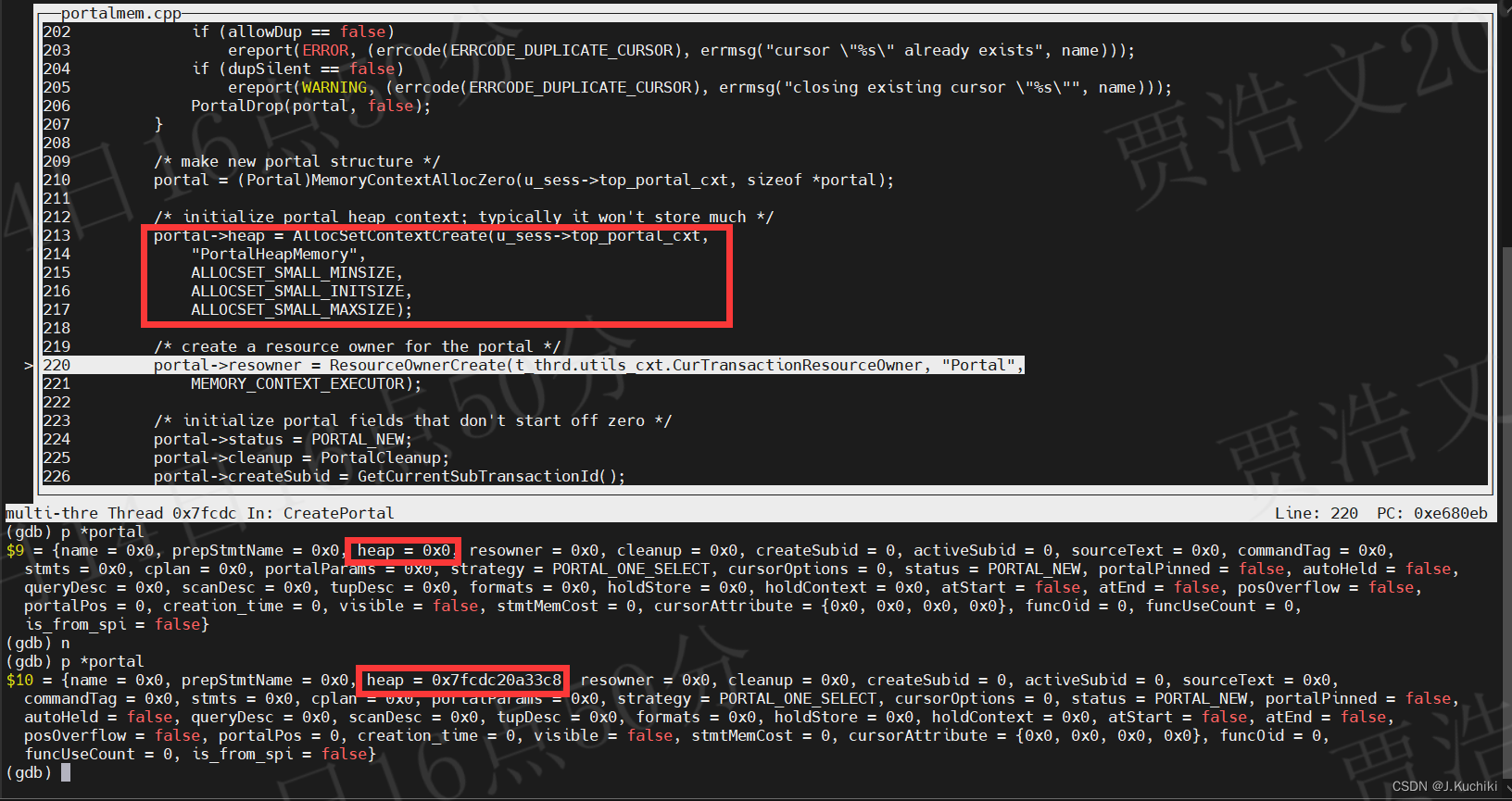

ResourceOwnerCreate
ResourceOwnerCreate 的函数,用于创建资源拥有者(ResourceOwner)。资源拥有者是 PostgreSQL 中用于跟踪和管理资源的对象,通常用于内存和其他资源的管理。函数接受多个参数,包括父资源拥有者、名称和内存组类型,并创建一个新的资源拥有者对象。资源拥有者对象用于组织和跟踪分配给它的资源,并可以构建一个层次结构以表示资源之间的关系。以下是对该函数的解释:(路径:src/common/backend/utils/resowner/resowner.cpp)
/****************************************************************************** EXPORTED ROUTINES* 导出的函数*****************************************************************************/
/** ResourceOwnerCreate* 创建一个空的 ResourceOwner(资源拥有者)。** 所有 ResourceOwner 对象都保存在 t_thrd.top_mem_cxt 中,因为它们只能通过显式方式释放。*/
ResourceOwner ResourceOwnerCreate(ResourceOwner parent, const char* name, MemoryGroupType memGroup)
{ResourceOwner owner; // 创建一个 ResourceOwner 对象// 使用 MemoryContextAllocZero 函数在指定的内存上下文中分配内存并清零,// 返回的内存块大小为 sizeof(ResourceOwnerData) 字节。owner = (ResourceOwner)MemoryContextAllocZero(THREAD_GET_MEM_CXT_GROUP(memGroup), sizeof(ResourceOwnerData));owner->name = name; // 设置 ResourceOwner 的名称if (parent) {// 如果存在父 ResourceOwner,则设置当前 ResourceOwner 的父节点、// 下一个子节点为父 ResourceOwner 的第一个子节点,并将当前 ResourceOwner// 设置为父 ResourceOwner 的第一个子节点。owner->parent = parent;owner->nextchild = parent->firstchild;parent->firstchild = owner;}// 如果父 ResourceOwner 为空且名称不为 "TopTransaction",// 则将当前 ResourceOwner 设置为 IsolatedResourceOwner。if (parent == NULL && strcmp(name, "TopTransaction") != 0)IsolatedResourceOwner = owner;return owner; // 返回创建的 ResourceOwner 对象
}
调试信息如下:

PortalHashTableInsert
宏 PortalHashTableInsert 用于将一个 portal(查询计划的执行状态)插入到 portal 哈希表中。这个宏的主要目的是将一个 portal 插入到 portal 哈希表中,确保 portal 名称的唯一性。宏接受两个参数,一个是要插入的 portal 对象(PORTAL),另一个是 portal 的名称(NAME)。
主要执行过程解释如下:
- PortalHashInsert 宏使用 hash_search 函数在 portal 哈希表中查找或插入一个 entry(条目)。
- 如果在哈希表中找到具有相同名称的 portal,则会引发错误,因为 portal 名称必须唯一。
- 如果未找到同名的 portal,则会将 portal 对象关联到哈希表的 entry 中,并将 portal 的名称指向哈希表 entry 的 portalname 字段,以避免重复存储。
以下是对宏 PortalHashTableInsert 源码的注释:(路径:src/common/backend/utils/mmgr/portalmem.cpp)
#define PortalHashTableInsert(PORTAL, NAME) \do { \PortalHashEnt* hentry = NULL; \bool found = false; \\// 使用 hash_search 函数在指定的哈希表中查找或插入 portal,如果找到则设置 found 为 true。hentry = (PortalHashEnt*)hash_search(u_sess->exec_cxt.PortalHashTable, (NAME), HASH_ENTER, &found); \if (found) { \// 如果找到了同名的 portal,则引发错误,因为 portal 名称必须唯一。ereport(ERROR, (errcode(ERRCODE_SYSTEM_ERROR), errmsg("duplicate portal name"))); \} \// 将 portal 对象关联到哈希表的 entry 中。hentry->portal = PORTAL; \/* 为了避免重复的存储,将 PORTAL->name 指向哈希表 entry 的 portalname 字段 */ \(PORTAL)->name = hentry->portalname; \} while (0)
调试信息如下:
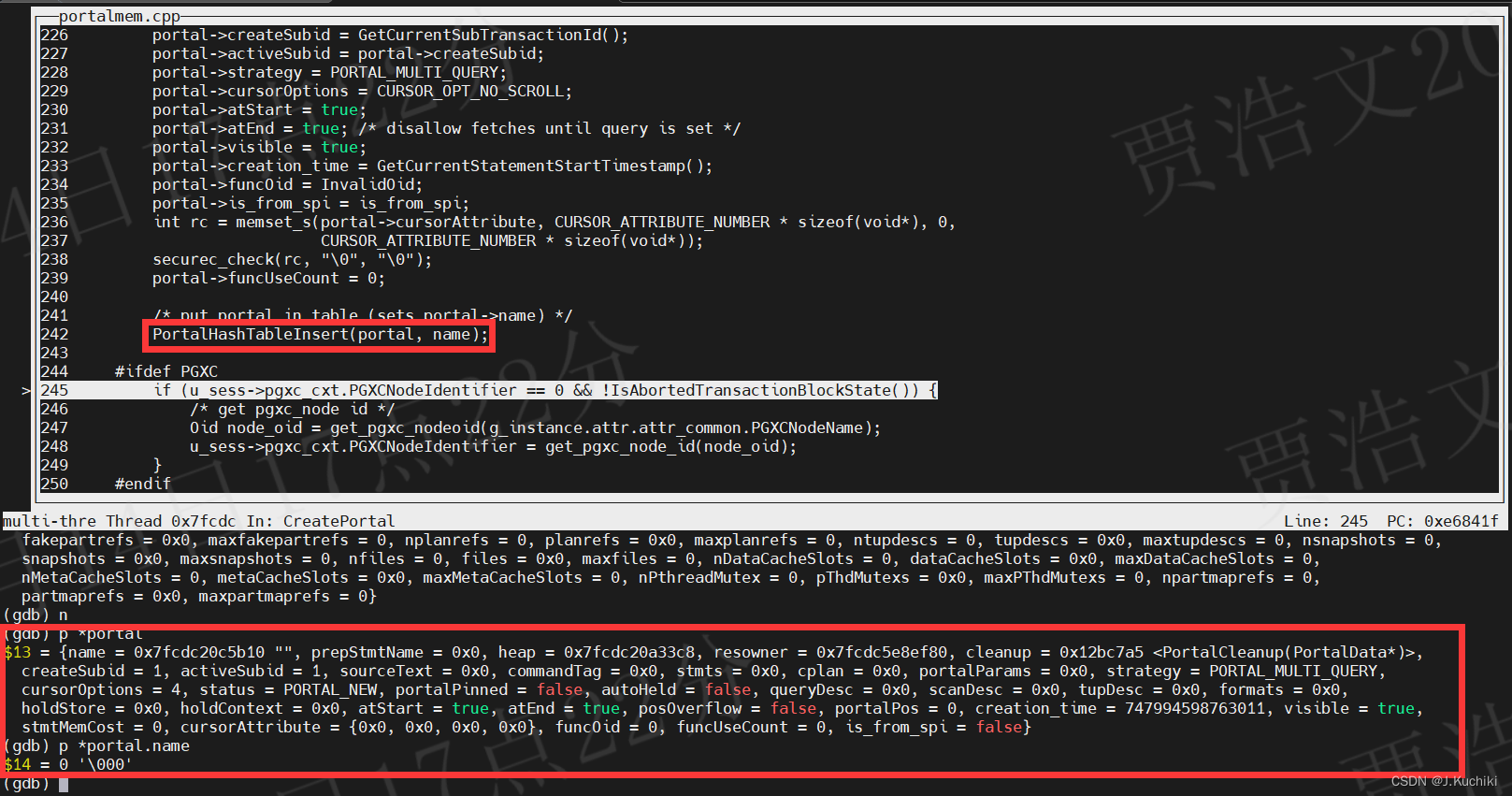
总结
CreatePortal 函数的主要目的是创建一个新的 portal(查询计划的执行状态)对象,并将其添加到 portal 哈希表中。以下是 CreatePortal 函数的主要过程总结:
- 首先,函数接收四个参数:name(portal 的名称)、allowDup、dupSilent 和 is_from_spi。这些参数用于配置创建的 portal 对象。
- 函数开始执行时,首先会检查传递的 name 参数是否有效,即不为 NULL。
- 接下来,函数调用 GetPortalByName 函数,尝试通过传递的 name 参数查找已存在的 portal。如果找到了同名的 portal,根据 allowDup 和 dupSilent 参数的设置,可能会执行不同的操作:
- 如果 allowDup 为 false,则会引发错误,因为不允许重复的 portal 名称。
- 如果 dupSilent 为 false,则会发出警告,指示正在关闭已存在的 portal。
- 如果 allowDup 和 dupSilent 都为 true,则会关闭已存在的 portal。
- 如果不存在同名的 portal 或者已经关闭了同名 portal,接下来会创建一个新的 portal 对象。这个过程包括以下步骤:
- 分配内存以创建 portal 对象。
- 初始化 portal 的各个字段,包括状态、资源管理器等。
- 将新的 portal 添加到 portal 哈希表中,确保 portal 名称的唯一性。
- 在 portal 对象创建完成后,函数可能还会执行一些与上下文管理相关的操作,如内存分配和资源管理。
- 最后,函数返回新创建的 portal 对象,供后续的查询执行和管理使用。
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"【PostgreSQL内核学习(十一)—— (CreatePortal)】":http://eshow365.cn/6-10768-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!