(14)学习笔记:动手深度学习(Pytorch神经网络基础)
最佳答案 问答题库608位专家为你答疑解惑
文章目录
- 神经网络的层与块
- 块的基本概念
- 自定义块
- 问答
神经网络的层与块
块的基本概念
以多层感知机为例, 整个模型接受原始输入(特征),生成输出(预测), 并包含一些参数(所有组成层的参数集合)。
同样,每个单独的层接收输入(由前一层提供), 生成输出(到下一层的输入),并且具有一组可调参数, 这些参数根据从下一层反向传播的信号进行更新。
块可以描述单个层、由多个层组成的组件或者模型本身。
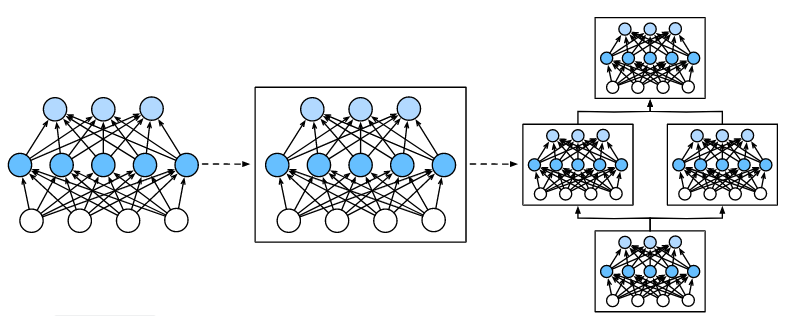
在pytorch中,块由class表示。它的任何子类都必须定义一个将其输入转换为输出的前向传播函数, 并且必须存储任何必需的参数。 注意,有些块不需要任何参数。 最后,为了计算梯度,块必须具有反向传播函数。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))X = torch.rand(2, 20)
print(X)
print(net(X))
自定义块
- 将输入数据作为其前向传播函数的参数。
- 通过前向传播函数来生成输出。请注意,输出的形状可能与输入的形状不同。例如,我们上面模型中的第一个全连接的层接收一个20维的输入,但是返回一个维度为256的输出。
- 计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通常这是自动发生的。
- 存储和访问前向传播计算所需的参数。
- 根据需要初始化模型参数。
class MLP(nn.Module):# 用模型参数声明层。这里,我们声明两个全连接的层def __init__(self):# 调用`MLP`的父类`Module`的构造函数来执行必要的初始化。# 这样,在类实例化时也可以指定其他函数参数,例如模型参数`params`(稍后将介绍)super().__init__()self.hidden = nn.Linear(20, 256) # 隐藏层self.out = nn.Linear(256, 10) # 输出层# 定义模型的前向传播,即如何根据输入`X`返回所需的模型输出def forward(self, X):# 注意,这里我们使用ReLU的函数版本,其在nn.functional模块中定义。return self.out(F.relu(self.hidden(X)))
问答
在将类别变量转换成伪变量的时候内存炸掉了怎么办?
1.转换为系数矩阵
2.考虑其它特征表达的方法(自然语言处理)
实例化后,不用调用实例方法,就可以net(X),是因为父类实现了魔法方法吗?
可以使用net.forward(X),这里在module里面做了映射
我们创建好网络之后torch是按什么规则给参数初始化的?
采用kaiming初始化
跑项目的时候显存不够用怎么办,如果把batch_size调小,显存够用了但是cuda占用一直很低怎么办?
调小bach size后模型的性能会下降,比较好的方法是把模型变小
—般使用gpu训练,data在哪一步to_gpu比较好?
在最后to_gpu,做前向和反向运算
自定义的block被放在同一个Sequential内的不同层,但不想共享参数,该怎么做呢?
每次创建一个实例都会有不同的参数,只有将同一个实例放在不同层才会共享参数
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"(14)学习笔记:动手深度学习(Pytorch神经网络基础)":http://eshow365.cn/6-33125-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: NOIP 赛前模拟总结(第二周)
- 下一篇: angular、 react、vue框架对比