【Synapse数据集】Synapse数据集介绍和预处理,数据集下载网盘链接
最佳答案 问答题库568位专家为你答疑解惑
【Segment Anything Model】做分割的专栏链接,欢迎来学习。
【博主微信】cvxiaoyixiao
本专栏为公开数据集的介绍和预处理,持续更新中。
文章目录
- 1️⃣Synapse数据集介绍
- 文件结构
- 源文件样图
- 文件内容
- 2️⃣Synapse数据集百度网盘下载链接
- 官网下载
- 登录
- 下载
- 没有加速器的从百度网盘下载 永久有效💮 💯
- 3️⃣Synapse数据集预处理目标
- 改变Synapse数据集类别
- 将官方Synapse数据集的Training 文件分切片转为npz保存。
- 将官方Synapse数据集的Training的部分文件处理为hy文件格式保存
- 4️⃣代码
- 文件目录
- 代码
1️⃣Synapse数据集介绍
文件结构
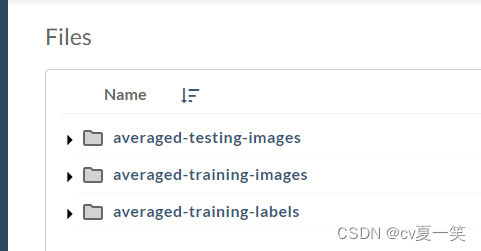
官网分为train和test train有83例患者nii原图和label。test有72名患者nii原图,没有label
源文件样图
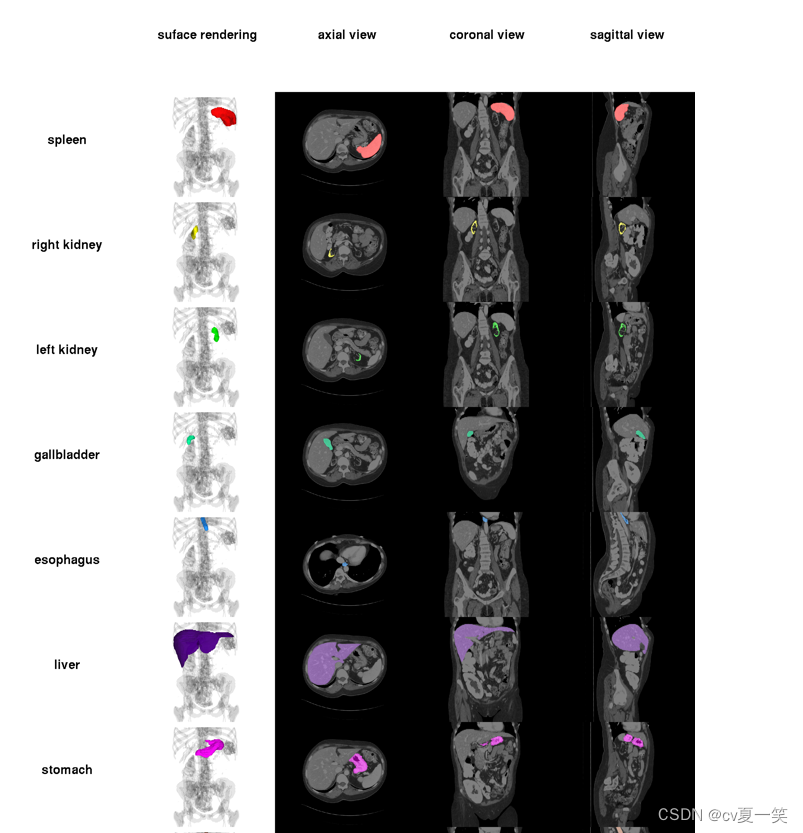
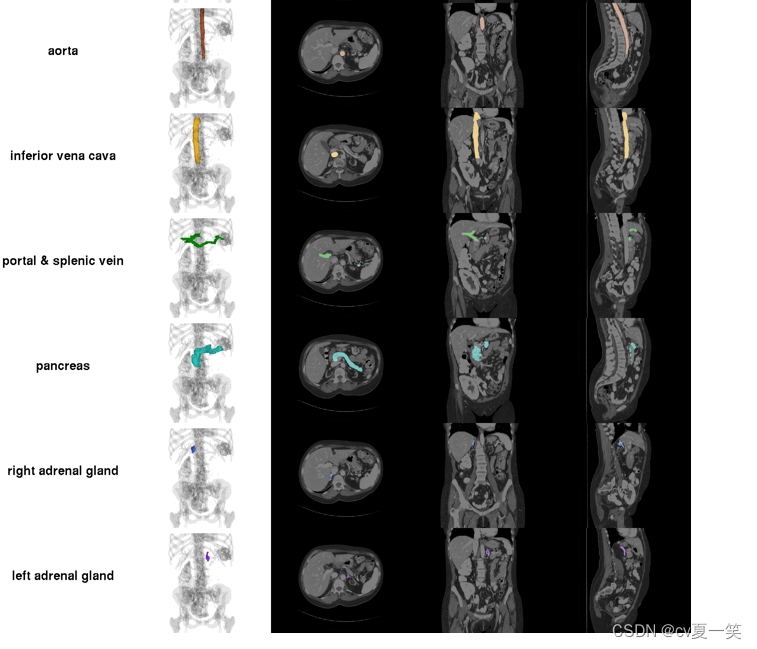
文件内容
Synapse数据集由13个腹部器官由两名经验丰富的本科生手动标记,并由放射科医生使用MIPAV软件在体积基础上进行验证,包括:
(1) 脾脏
(2) 右肾
(3) 左肾
(4) 胆囊
(5) 食道
(6) 肝
(7) 胃
(8) 主动脉
(9) 下腔静脉
(10) 门静脉和脾静脉
(11) 胰腺
(12) 右肾上腺
(13) 左肾上腺
在勾画的GT图像中,像素大小代表类别,并和上面对应,比如 像素为2的地方代表是右肾。
⚠️⚠️⚠️有些患者可能没有(2)右肾或(4)胆囊,因此没有标记。
2️⃣Synapse数据集百度网盘下载链接
官网下载
官网链接
打开点击Files 不要直接点击Download Options❌ 要点击下面三个文件,选择要下载的东西。需要登录谷歌账号和借助加速器。
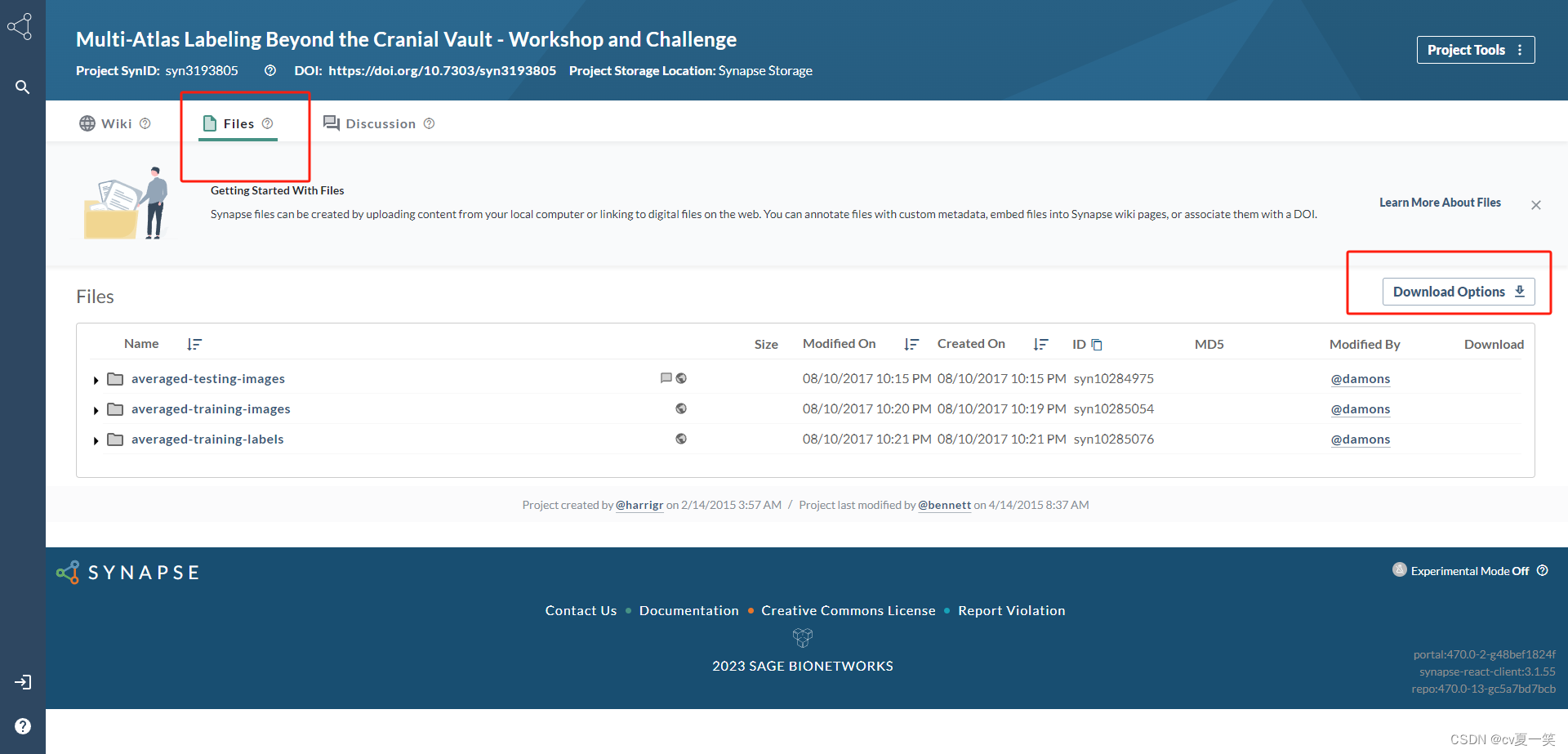
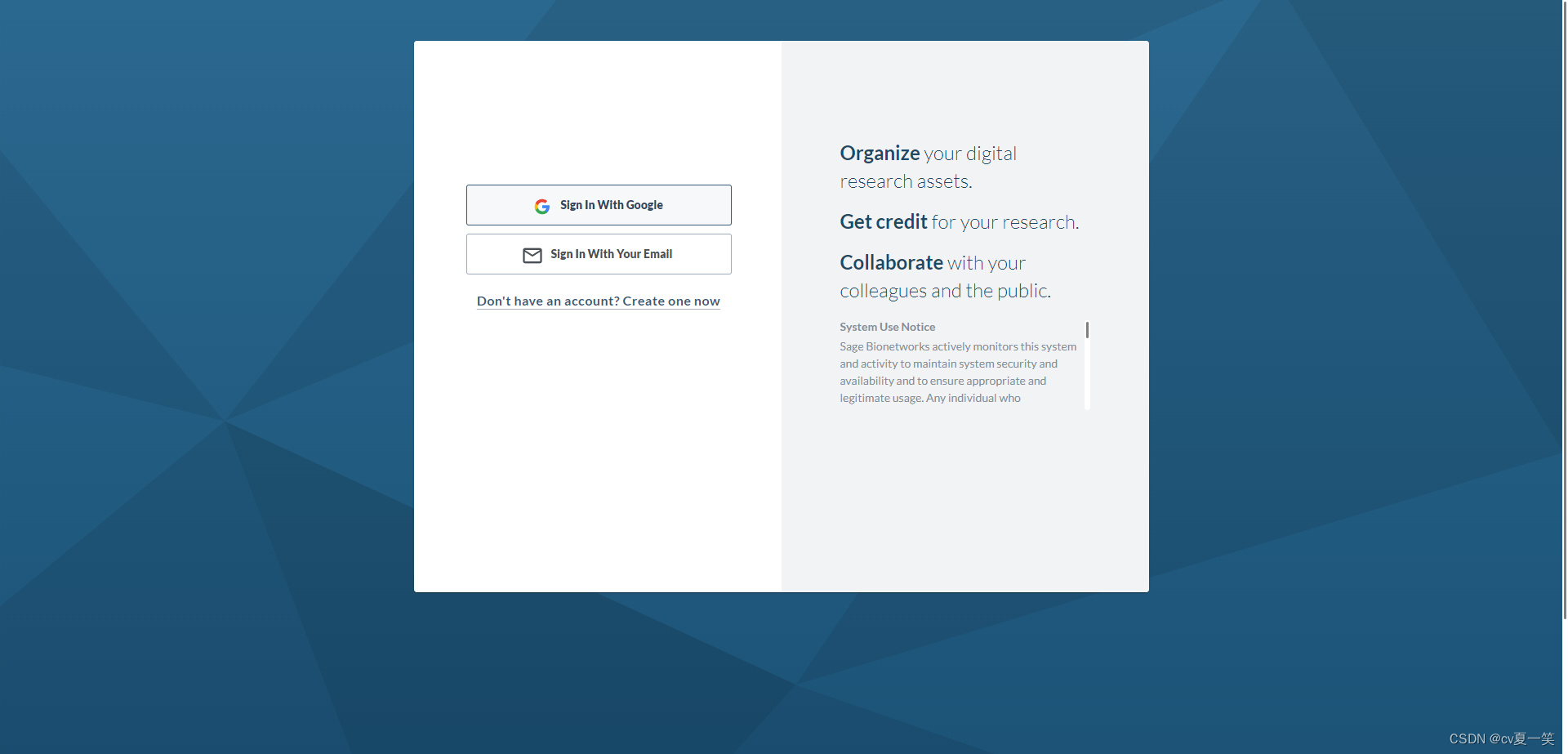
登录
登录进来是这样子的,这个时候在点击Download Options,之后点击Add
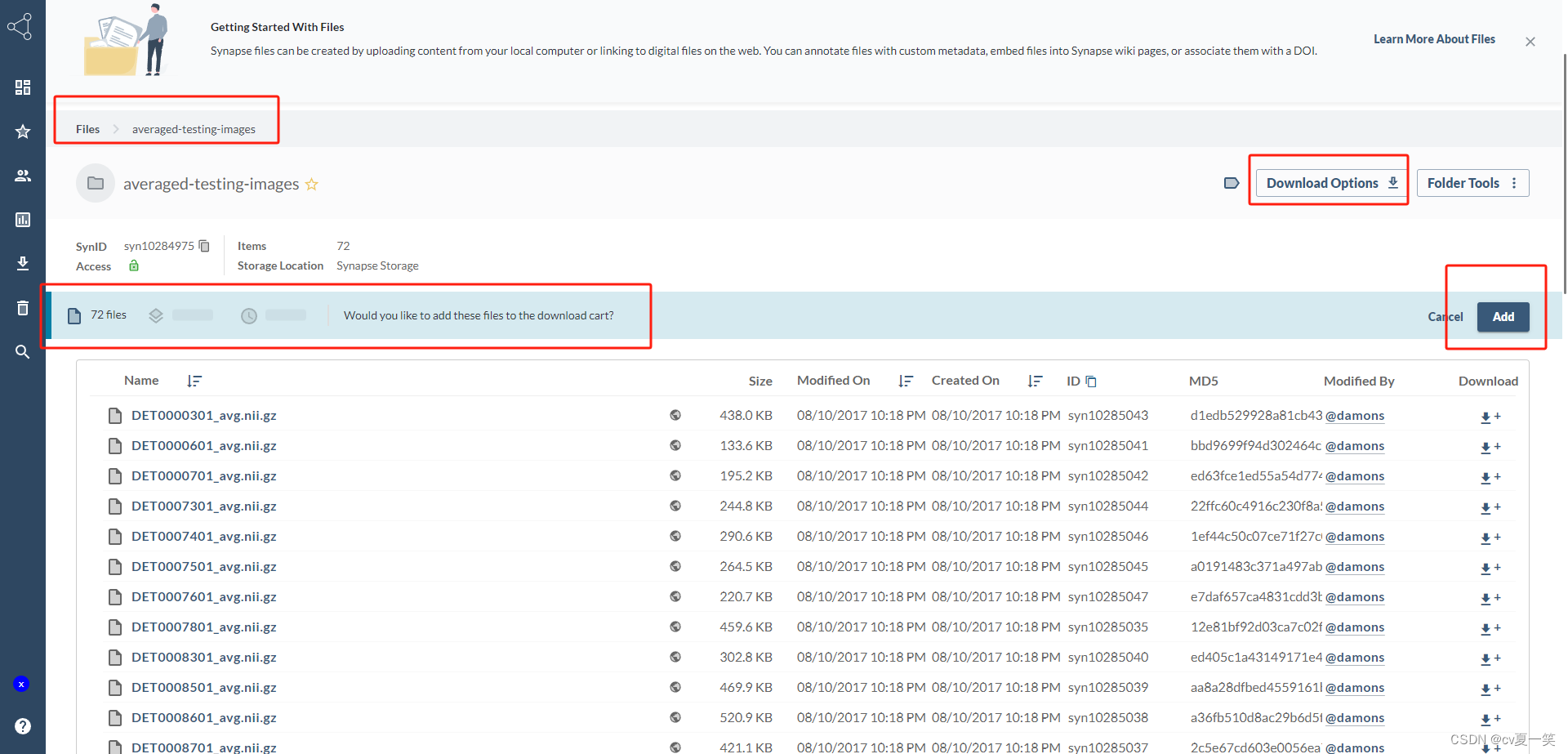
下载
点击左侧栏目的下载箭头,点击download,输入名字,点击Download Package
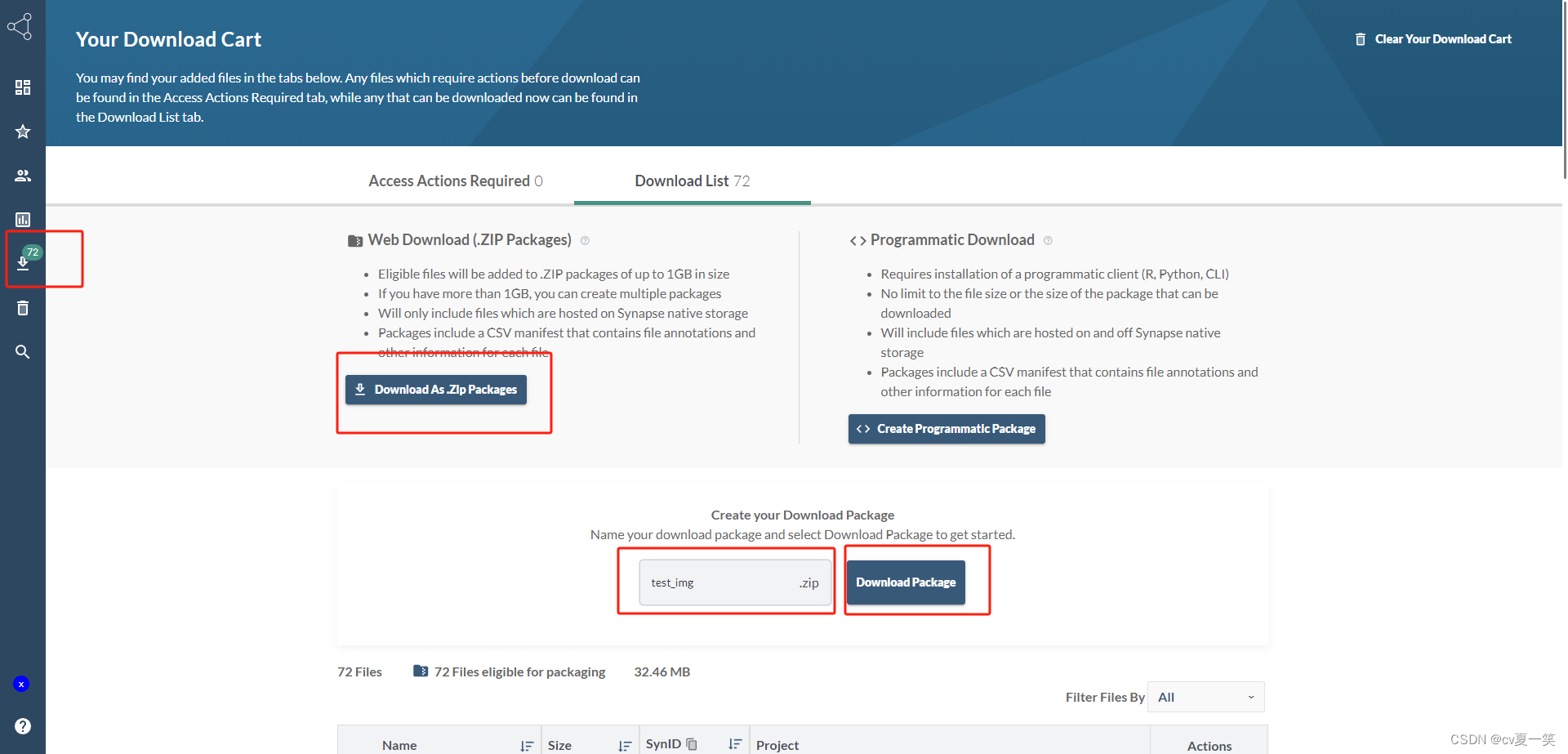
没有加速器的从百度网盘下载 永久有效💮 💯
链接:
https://pan.baidu.com/s/1jJm7tbiDMOA8S331QFu8CQ?pwd=bw5i提取码:bw5i
–来自百度网盘超级会员V6的分享
3️⃣Synapse数据集预处理目标
改变Synapse数据集类别
官方是:
(1) 脾脏
(2) 右肾
(3) 左肾
(4) 胆囊
(5) 食道
(6) 肝
(7) 胃
(8) 主动脉
(9) 下腔静脉
(10) 门静脉和脾静脉
(11) 胰腺
(12) 右肾上腺
(13) 左肾上腺
改变为:
1:脾脏
2:右肾
3:左肾
4:胆囊
5:肝脏
6:胃
7:主动脉
8:胰腺
对应关系也就是:
hashmap = {1:1, 2:2, 3:3, 4:4, 5:0, 6:5, 7:6, 8:7, 9:0, 10:0, 11:8, 12:0, 13:0}
将官方Synapse数据集的Training 文件分切片转为npz保存。
每个npz包含一个切片img和对应的label,文件名字以样本名称和切片id命名
比如第一个样本叫case0005,保存其第2个切片,那么最好的npz名称为case0005_slice002.npz
作为训练集的输入。
将官方Synapse数据集的Training的部分文件处理为hy文件格式保存
每个h5文件包含一个切片img和对应的label,并且以样本名称和切片id命名
4️⃣代码
文件目录
自己划分Training文件到自己的测试集和训练集,因为官网的测试集没有label。
代码
import os
from glob import glob
import h5py
import nibabel as nib
import numpy as np
from tqdm import tqdm# 自己手动选择的测试样本
test_data = [1, 2, 3, 4, 8, 22, 25, 29, 32, 35, 36, 38]
# 源数据集类别和我们规定的类别对应关系
hashmap = {1:1, 2:2, 3:3, 4:4, 5:0, 6:5, 7:6, 8:7, 9:0, 10:0, 11:8, 12:0, 13:0}use_normalize=True
# 文件夹路径,保存处理之后的npz文件
dst_path="./pre_over_dataset"
def preprocess_train_image(image_files: str, label_files: str) -> None:# 创建一个文件夹,保存处理之后的npz文件os.makedirs(f"{dst_path}/train_npz", exist_ok=True)a_min, a_max = -125, 275b_min, b_max = 0.0, 1.0print(len(image_files))pbar = tqdm(zip(image_files, label_files), total=len(image_files))for image_file, label_file in pbar:# **/imgXXXX.nii.gz -> parse XXXXnumber = image_file.split('/')[-1][3:10]if int(number) in test_data:continueimage_data = nib.load(image_file).get_fdata()label_data = nib.load(label_file).get_fdata()image_data = image_data.astype(np.float32)label_data = label_data.astype(np.float32)# 除去像素中在最大值和最小值之外的。# 如果某个像素小于最小值则替换成最小值,如果某个像素大于最大值,则替换成最大值image_data = np.clip(image_data, a_min, a_max)# 是否进行归一化if use_normalize:assert a_max != a_minimage_data = (image_data - a_min) / (a_max - a_min)H, W, D = image_data.shape# 通道最先image_data = np.transpose(image_data, (2, 1, 0)) # [D, W, H]label_data = np.transpose(label_data, (2, 1, 0))counter = 1# 遍历哈希表,将元数据分类对应我们规定的新分类。for k in sorted(hashmap.keys()):assert counter == kcounter += 1# 并更改对应位置像素值,到新的分类label_data[label_data == k] = hashmap[k]# 按照deep分切片保存for dep in range(D):save_path = f"{dst_path}/train_npz/case{number}_slice{dep:03d}.npz"# 保存成npz,里面是label和imagenp.savez(save_path, label=label_data[dep,:,:], image=image_data[dep,:,:])pbar.close()def preprocess_valid_image(image_files: str, label_files: str) -> None:os.makedirs(f"{dst_path}/test_vol_h5", exist_ok=True)
#我们规定的最大最小像素。可以改a_min, a_max = -125, 275b_min, b_max = 0.0, 1.0pbar = tqdm(zip(image_files, label_files), total=len(image_files))for image_file, label_file in pbar:# **/imgXXXX.nii.gz -> parse XXXXnumber = image_file.split('/')[-1][3:7]if int(number) not in test_data:continueimage_data = nib.load(image_file).get_fdata()label_data = nib.load(label_file).get_fdata()image_data = image_data.astype(np.float32)label_data = label_data.astype(np.float32)image_data = np.clip(image_data, a_min, a_max)if use_normalize:assert a_max != a_minimage_data = (image_data - a_min) / (a_max - a_min)H, W, D = image_data.shapeimage_data = np.transpose(image_data, (2, 1, 0))label_data = np.transpose(label_data, (2, 1, 0))counter = 1for k in sorted(hashmap.keys()):assert counter == kcounter += 1label_data[label_data == k] = hashmap[k]save_path = f"{dst_path}/test_vol_h5/case{number}.npy.h5"f = h5py.File(save_path, 'w')f['image'] = image_dataf['label'] = label_dataf.close()pbar.close()if __name__ == "__main__":# 根目录,到Training文件夹就行data_root = "./Training"# 获取所有训练测试文件image_files = sorted(glob(f"{data_root}/img/*.nii.gz"))label_files = sorted(glob(f"{data_root}/label/*.nii.gz"))# 传入预处理函数,这个是转为npz的preprocess_train_image(image_files, label_files)# 这个是转为h5的preprocess_valid_image(image_files, label_files)
99%的人还看了
相似问题
猜你感兴趣
版权申明
本文"【Synapse数据集】Synapse数据集介绍和预处理,数据集下载网盘链接":http://eshow365.cn/6-14174-0.html 内容来自互联网,请自行判断内容的正确性。如有侵权请联系我们,立即删除!
- 上一篇: 第八章 结构体
- 下一篇: Qt创建线程(继承于QThread的方法)